


【分布式·大数据】大模型赛道如何实现华丽的弯道超车 —— AI/ML训练赋能解决方案
文章目录 大模型赛道如何实现华丽的弯道超车 —— AI/ML训练赋能解决方案01 具备对海量小文件的频繁数据访问的 I/O 效率02 提高 GPU 利用率,降低成本并提高投资回报率03 支持各种存储系...

Hive常用日期格式转换
文章目录获取当前时间日期格式转换返回日期中的年,月,日,时,分,秒,当前的周数计算日期差值返回当月或当年的第一天获取当前时间获取当前时间戳select unix_timestamp()复制把时间戳转为正常的日期se...
Spark-机器学习(5)分类学习之朴素贝叶斯算法
在之前的文章中,我们学习了回归中的逻辑回归,并带来简单案例,学习用法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮...
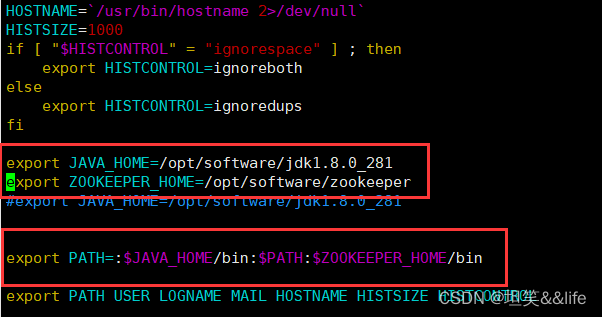
centos7系列:出现ZooKeeper JMX enabled by default这种错误的解决方法
出现ZooKeeper JMX enabled by default这种错误的解决方法 前言一 问题描述二 解决方法2.1 可能的原因分析2.2 小编的问题解决方法First:检查/etc/profi...

头歌——HBase 开发:使用Java操作HBase
第1关:创建表 题目 任务描述 本关任务:使用Java代码在HBase中创建表。 相关知识 为了完成本关任务,你需要掌握:1.如何使用Java连接HBase数据库,2.如何使用Java代码在HBase中创...

educoder大数据作业答案
第1关:第一题 任务描述编程要求测试说明 任务描述 本关任务:根据编程要求,完成任务。 编程要求 打开右侧代码文件窗口,在 Begin 至 End 区域补充代码,完成任务。 在本地目录 /data/b...

Hive表DDL操作(一)
目录 第1关:Create/Alter/Drop 数据库 任务描述 相关知识 编程要求 测试说明 代码: 第...

HBase 基础结构
HBase 是一个分布式[集群]、可扩展[动态上下线]、支持海量存储的 NoSQL 数据库。相当于 BigTable,负责海量数据的存储。如果数据量小的时候不适合使用 HBase,因为生产上需要不断的切分和合并比较...

Flink WordCount实践
目录 前提条件 基本准备 批处理API实现WordCount 流处理API实现WordCount 数据源是文件...

Kafka的重要组件,谈谈流处理引擎Kafka Stream
系列文章目录 上手第一关,手把手教你安装kafka与可视化工具kafka-eagleKafka是什么,以及如何使用SpringBoot对接Kafka架构必备能力——kafka的选型对比及应用场景Kafka存取原理...