

系列文章目录
上手第一关,手把手教你安装kafka与可视化工具kafka-eagle
Kafka是什么,以及如何使用SpringBoot对接Kafka
架构必备能力——kafka的选型对比及应用场景
Kafka存取原理与实现分析,打破面试难关
防止消息丢失与消息重复——Kafka可靠性分析及优化实践
Kafka的重要组件,谈谈流处理引擎Kafka Stream
- 系列文章目录
- 一、Kafka Stream是什么
- 1. 简介
- 2. 特点
- 二、流程与核心类
- 1. KStream 和 KTable 概念
- 2. 常用逻辑与转换
- 三、使用场景与Demo
- 1. 实时数据分析
- 2. 实时预测
- 四、总结

我们前面介绍了很多kafka本身的特性与设计,也说了不少原理性的内容,本次我们稍微放松一下,来介绍一下 Kafka的一个重要组件—— Kafka Stream
📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
📗本文收录于 kafka 专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙Zookeeper Redis dubbo docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、Kafka Stream是什么
1. 简介
Kafka Stream是 Apache Kafka 的一个子项目,它提供了一种简单而快速的方法来对数据流进行处理,是一种无状态的流处理引擎,可以消费Kafka中的数据并将其转换为输出流。Kafka Stream不像其他流处理工具,它是一个Java库,能够快速构建、部署和管理数据流处理任务。
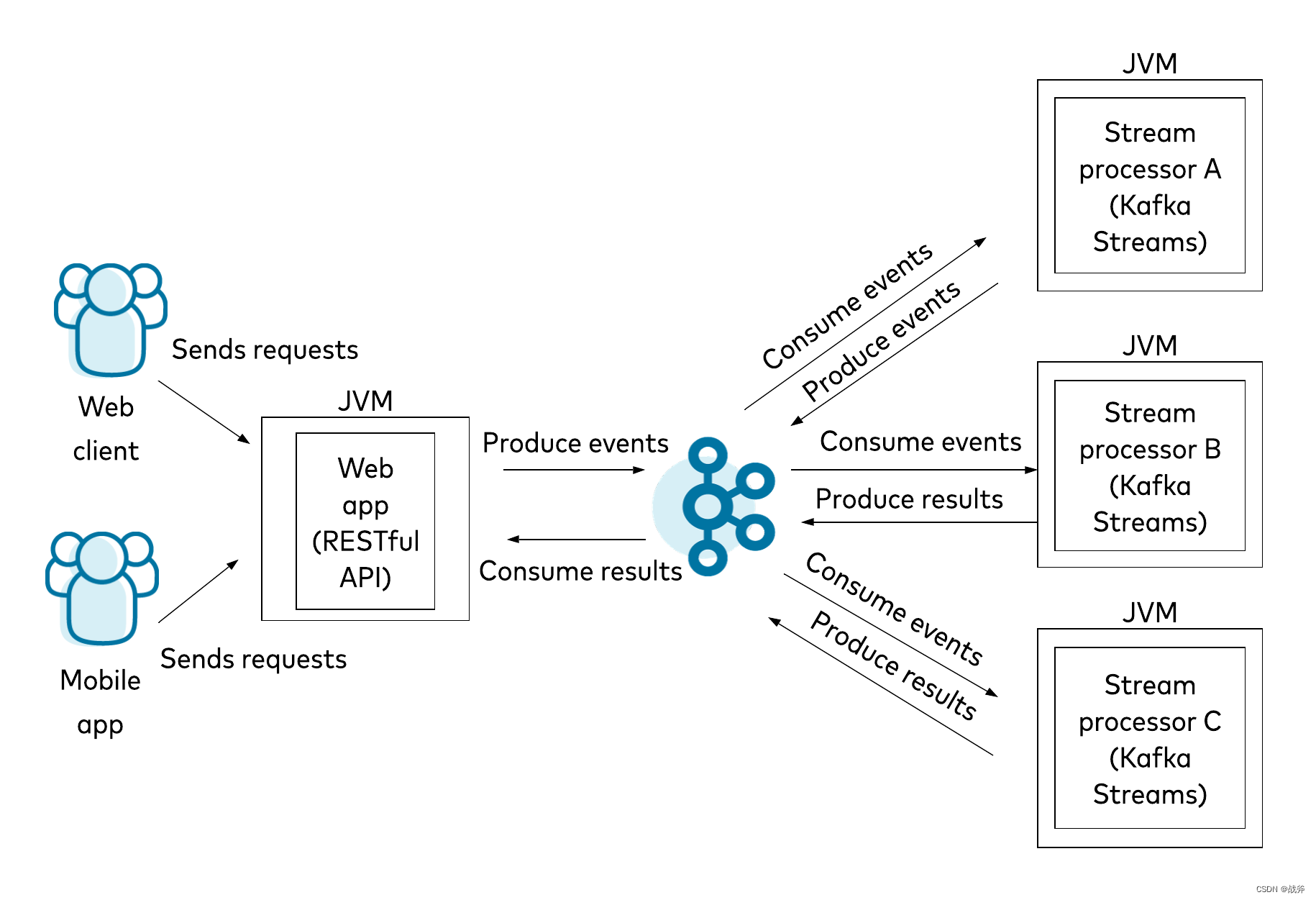
我们在前面的文章中《Kafka是什么,以及如何使用SpringBoot对接Kafka》 初步接触了kafka的客户端kafka client,当时如果有眼尖的同学应该也注意到了,在使用Spring Initializr创建项目时,就看见了Kafka Stream的身影
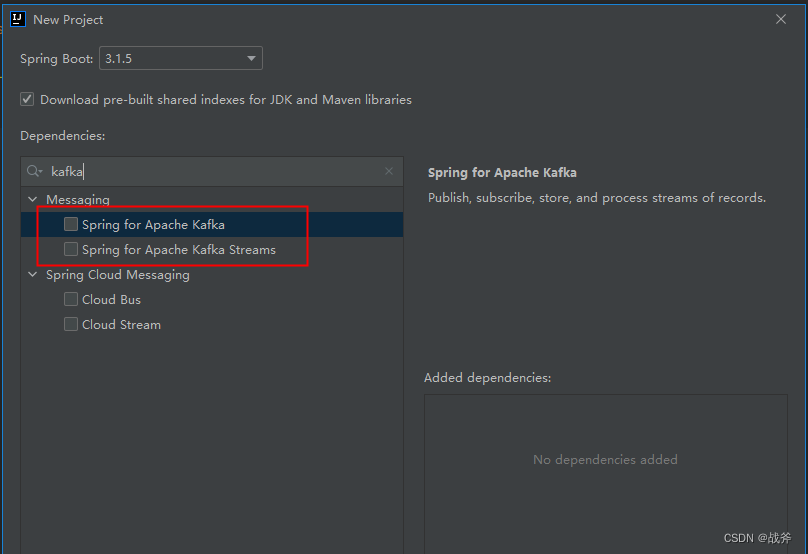
那么Kafka Stream 与 我们当时接触的 Kafka client 有什么联系吗?其实它们的共同点在于他们都是与Kafka集成的API,从逻辑层次来说,Kafka Stream 是建立在 Kafka client 上的,我们在引用 Kafka Stream 时, 其会自带着 Kafka client 的包,如下:

那它们的作用到底哪不一样呢?具体来说,它们的不同之处可从这几个方面看:
-
功能不同
Kafka Stream是用于流处理任务的API,它提供了一种简单而快速的方法来对数据流进行处理。相反,Kafka Client主要用于生产和消费Kafka消息。
-
处理方式不同
Kafka Client主要依赖于订阅和轮询来消费Kafka消息。而Kafka Stream依赖于数据流的处理,它会自动将Kafka消息转化为数据流,并实时处理这些数据。
-
API调用方式不同
在Kafka Stream中,您需要定义一个拓扑结构,描述如何将输入流转换成输出流,并执行转换。而在Kafka Client中,您需要调用API来发送和接收Kafka消息。
-
应用场景不同
Kafka Stream适用于实时数据分析、实时预测等需要流处理的场景。而Kafka Client更适用于异步数据传输的场景,例如日志收集、事件处理等。
2. 特点
我们前面说过,流处理引擎做的人也是很多的,常见的比如说Apache Flink、Apache Spark Streaming、Apache Storm 以及阿里参考 Apache Storm 开发的Jstorm。既然有如此多的可选项,为什么还有Kafka Stream这个东西呢?其实说来也简单,就是应用简单+功能丰富
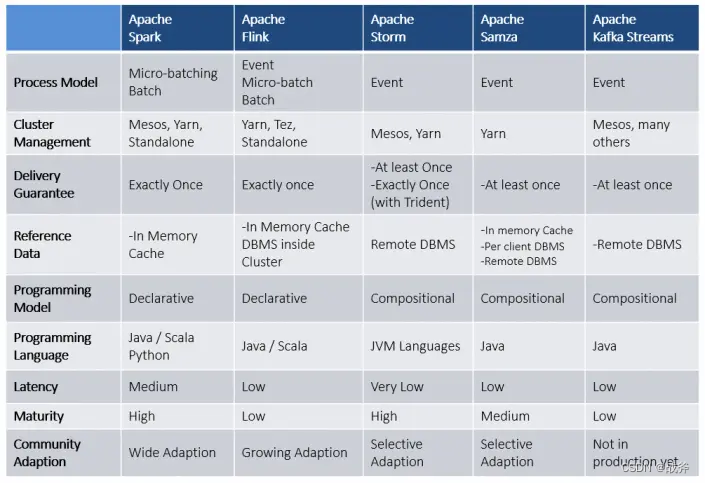
总计来说,其具备以下特点:
-
无需额外征用集群资源
在传统的流处理中,需要单独的集群进行数据处理,这就意味着需要额外的开销。而Kafka Stream是直接在Kafka集群上执行的,不会征用额外的资源。
-
易于使用
Kafka Stream提供了简单易用的API,使得开发人员可以快速地进行流处理任务的开发。它还支持Java 8中的Lambda表达式,使得代码更加简洁。
-
支持丰富的转换操作
Kafka Stream支持丰富的转换操作,包括过滤、映射、聚合等。这些操作可以被组合使用,以满足不同的处理需求。
二、流程与核心类
1. KStream 和 KTable 概念
我们上面简要介绍了下Kafka Stream的特点。但是,要想明白其流程并正确使用,我们还需要讲两个核心概念,也就是KStream 和 KTable
-
KStream
KStream是一个持续不断的流数据记录,每个记录都是一个key-value对,可以被读取、写入和转换。通常,KStream用于处理实时数据流,我们可以直接从kafka集群中指定主题来获取源源不断的数据
-
KTable
KTable顾名思义,可以看作是一张持久化的、可查询的、支持状态更新的表格。它通常是利用KStream的数据经过一系列转换和聚合操作生成的,KTable可以被读取和更新,但不能被删除。
KStream和KTable是互补的。KStream可以转换成KTable,也可以从KTable中获取值;KTable也可以转换成KStream,我们可以使用下图,看一下是如何针对数据流中,出现的单词进行计数并”落表“的:
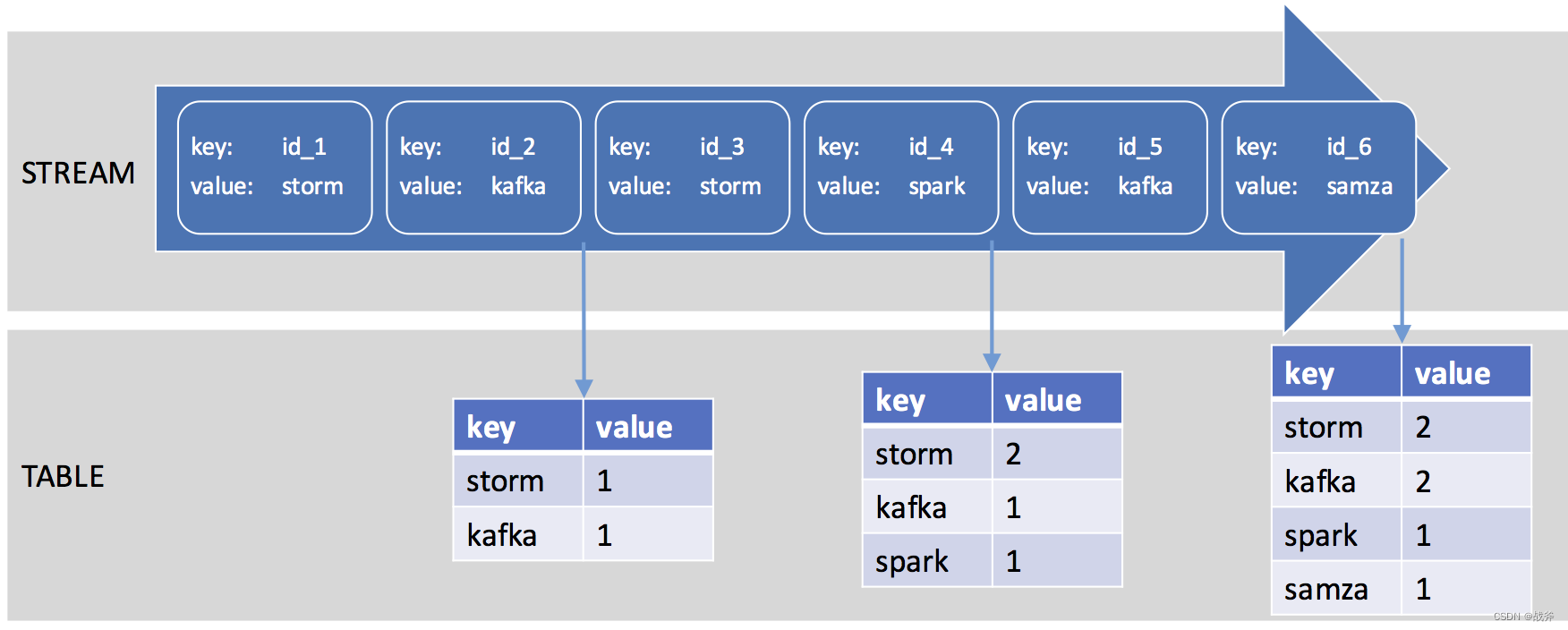
当然,我们还有必要提及一下GlobalKTable,它是一种特殊的KTable,GlobalKTable通常用于处理比较静态的全局数据,例如维护一个全局的用户信息表,而且只在应用程序启动时从Kafka主题中加载所有数据,这意味着需要消耗较大的内存空间。
2. 常用逻辑与转换
我们上面说了KStream 和 KTable ,在代码里其实也对应了两个类,那这两个类都有些什么方法呢?最重要的,我们想知道,它们是如何互相转换的。
其实关于 KStream ,可能有些同学会想到JDK 里的 Stream ,因为确实很多方法是一致的,所以不用慌张。我们先来介绍下 KStream 的常用方法:
- filter:过滤数据流中不符合条件的记录。
- map:将每个记录转换为一个新的记录,可以改变记录的key和value。
- flatMap:与map类似,可以将一个记录转换为多个新的记录。
- mapValues:与map类似,但记录的键保留不变,只改变值
- groupByKey:将记录按key进行分组,生成一个KGroupedStream对象,可以用于聚合操作。
- reduce:对KGroupedStream对象进行聚合操作。
- join:将两个KStream对象进行join操作,生成一个新的KStream对象。
- windowed:对KStream对象进行窗口操作,可以使用时间窗口或大小窗口。
- aggregate:将当前流中的记录聚合,并生成一个新的KTable。与reduce方法不同,aggregate方法不仅考虑当前记录,还考虑之前记录的聚合结果
- to:将结果输出到输出主题中
我们举一个小代码段来看下这些方法的使用
KStream
而关于KTable,也有一些常用方法,如下:
- filter:根据指定的谓词过滤记录,并返回一个新的KTable。谓词是一个接受key和value作为参数的函数,如果返回true,则保留该记录,否则过滤掉。
- mapValues:对KTable中的每个value执行指定的转换函数,并返回一个新的KTable。
- groupBy:根据指定的key进行分组,并返回一个KGroupedTable对象,该对象用于执行各种聚合操作。
- join:将当前KTable与另一个KTable或KStream进行连接,并返回一个新的KTable。
- toStream:将KTable转换为KStream,并返回一个新的KStream对象。
我们也写一小段代码用于演示:
// 从输入流中建立一个KTable StreamsBuilder builder = new StreamsBuilder(); KTable
当然,关于上述哪些方法,我们也可以用一张图来概括它们之间的转换关系,如下图,其中的 KGroupedStream 和 KGroupedTable 其实就是KStream 和 KTable 进行聚合操作后的产物
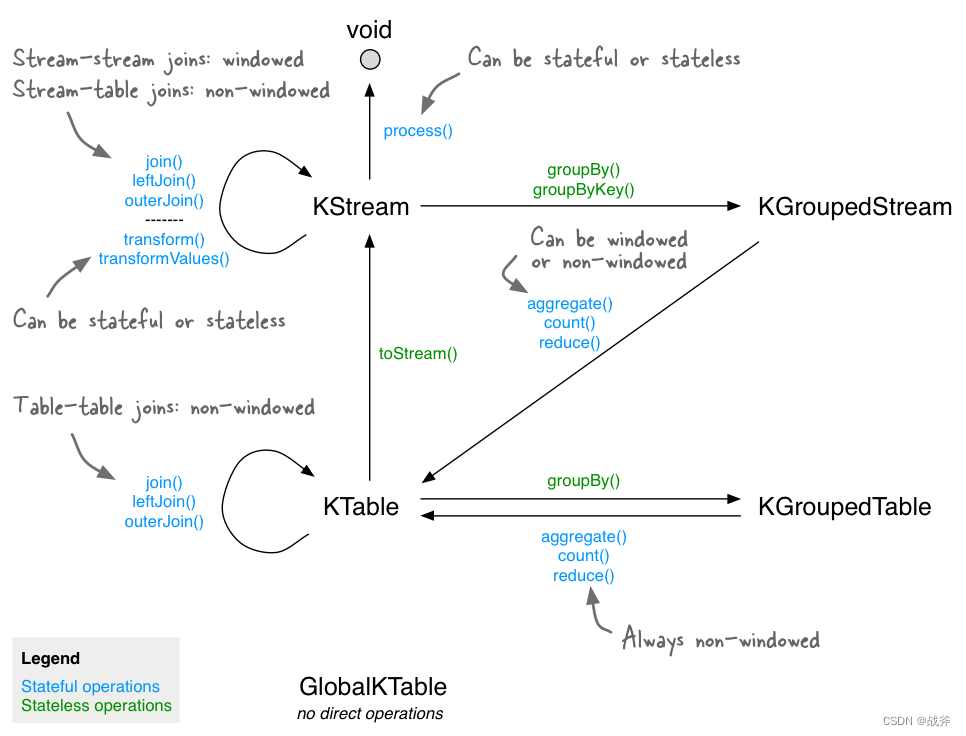
三、使用场景与Demo
1. 实时数据分析
Kafka Stream可以将实时到达的数据进行处理,以便进行实时数据分析。在这种情况下,Kafka Stream通常会将数据转换为一些有用的信息,以便于更好的理解数据,我们可以举一个简单的示例demo
假设我们有一个数据流,其中包含电影评分信息和电影相关信息。我们的任务是计算出每个电影的平均评分。
首先,我们需要定义输入数据流所需的数据结构。假设我们的数据结构如下:
@Data public class MovieRating { private String movieId; private float rating; } @Data public class Movie { private String movieId; private String title; }接下来,我们需要编写Kafka流应用程序。我们可以将其分为三个步骤:
1.从Kafka主题读取电影评分和电影相关信息。
2.以电影ID为键,将电影评分聚合到一个窗口中,并计算平均值。
3.将结果写入新的Kafka主题。
public static void main(String[] args) throws Exception { Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "movie-ratings-app"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, SpecificAvroSerde.class); final StreamsBuilder builder = new StreamsBuilder(); // 步骤1:从kafka主题中读取电影信息及评分 // 我们假设主题包含Avro编码的数据 KStream{ public RatingAggregateSerde() { super(new JsonSerializer<>(), new JsonDeserializer<>(RatingAggregate.class)); } } 在上面的代码中,我们使用Serdes.String()和SpecificAvroSerde来序列化和反序列化字符串和Avro-encoded对象。我们使用TimeWindows.of(Duration.ofMinutes(10))定义大小为10分钟的窗口。我们使用RatingAggregate类来辅助计算每个电影的平均评分,RatingAggregateSerde类来序列化和反序列化RatingAggregate对象
2. 实时预测
Kafka Stream可以用于实时预测任务,例如在一些应用中,需要根据实时到达的数据来进行预测。Kafka Stream可以使用已有的模型,对实时数据进行预测,从而实现实时的推荐或预测等功能。
还是拿电影举例,我们经常可以看到电影票房的预测,我们可以以此写一个Demo
public class MovieProcessor { private static final String INPUT_TOPIC = "box-office-input"; private static final String OUTPUT_TOPIC = "box-office-output"; public static void main(String[] args) { // 创建 Kafka Streams 配置 Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "box-office-predictor"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); // 创建 Kafka Streams StreamsBuilder builder = new StreamsBuilder(); KStream() { @Override public Double apply(Double value1, Double value2) { return value1 + value2; } }) .mapValues(new ValueMapper 四、总结
今天我们学了一些关于Kafka Stream的内容太,知道了它是一种流处理引擎,可以消费Kafka中的数据,进行处理后,还能其转换为输出流。它特点在于不需要额外征用集群资源、易于使用、支持丰富的转换操作。使用场景包括实时数据分析、实时预测等。但其实Kafka Stream的内容还是很多的,我们将在后面的学习中继续讲解
-
-

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...