

项目介绍
【开源】项目基于python+pandas+flask+mysql等技术实现豆瓣电影数据获取及可视化分析展示,觉得有用的朋友可以来个一键三连,感谢!!!
项目演示
【开源】2024最新python豆瓣电影数据爬虫+可视化分析项目
项目截图
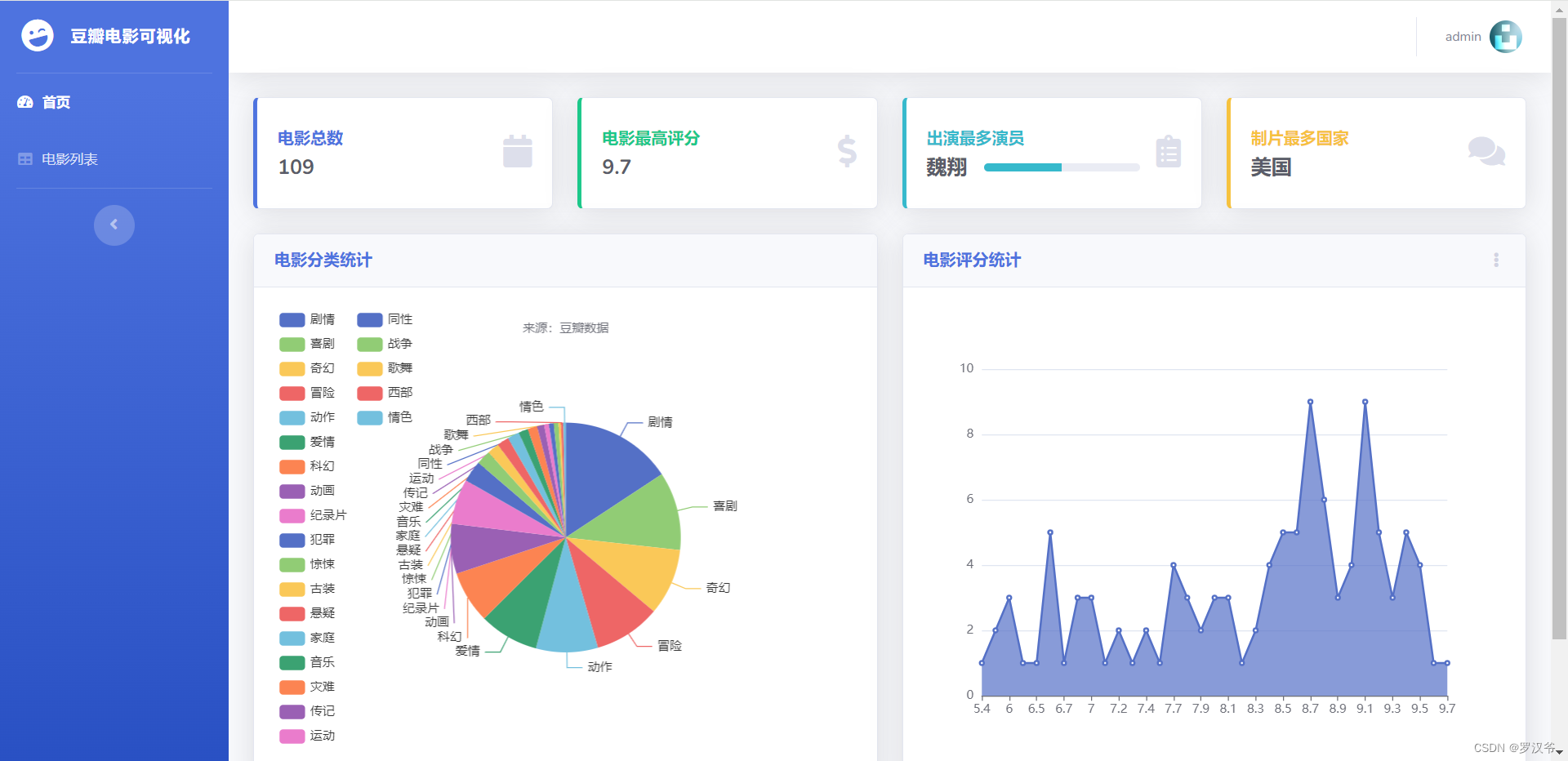
- 首页
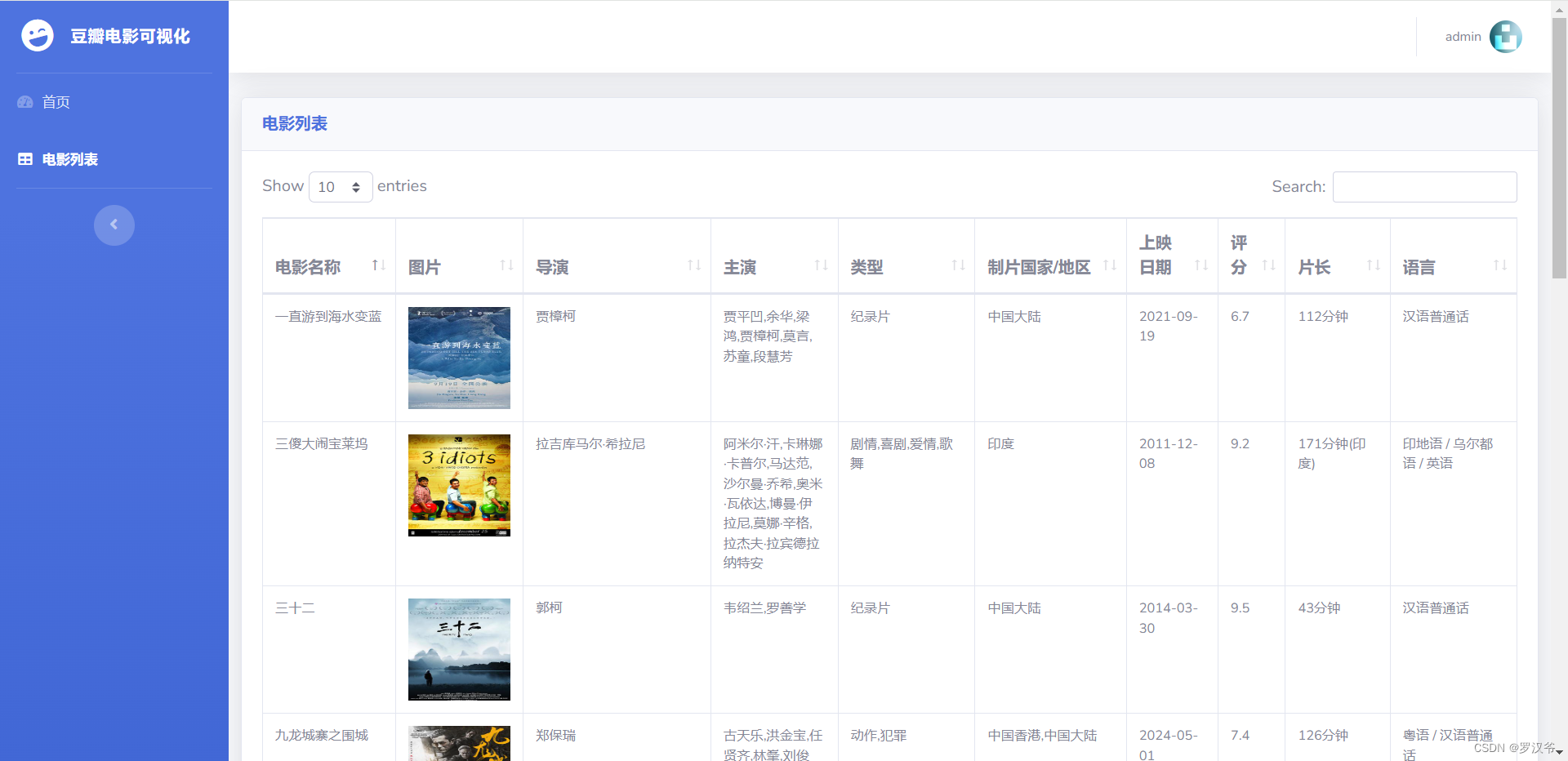
- 列表页
- 爬虫演示

项目地址
https://github.com/mudfish/python-douban-view
项目结构
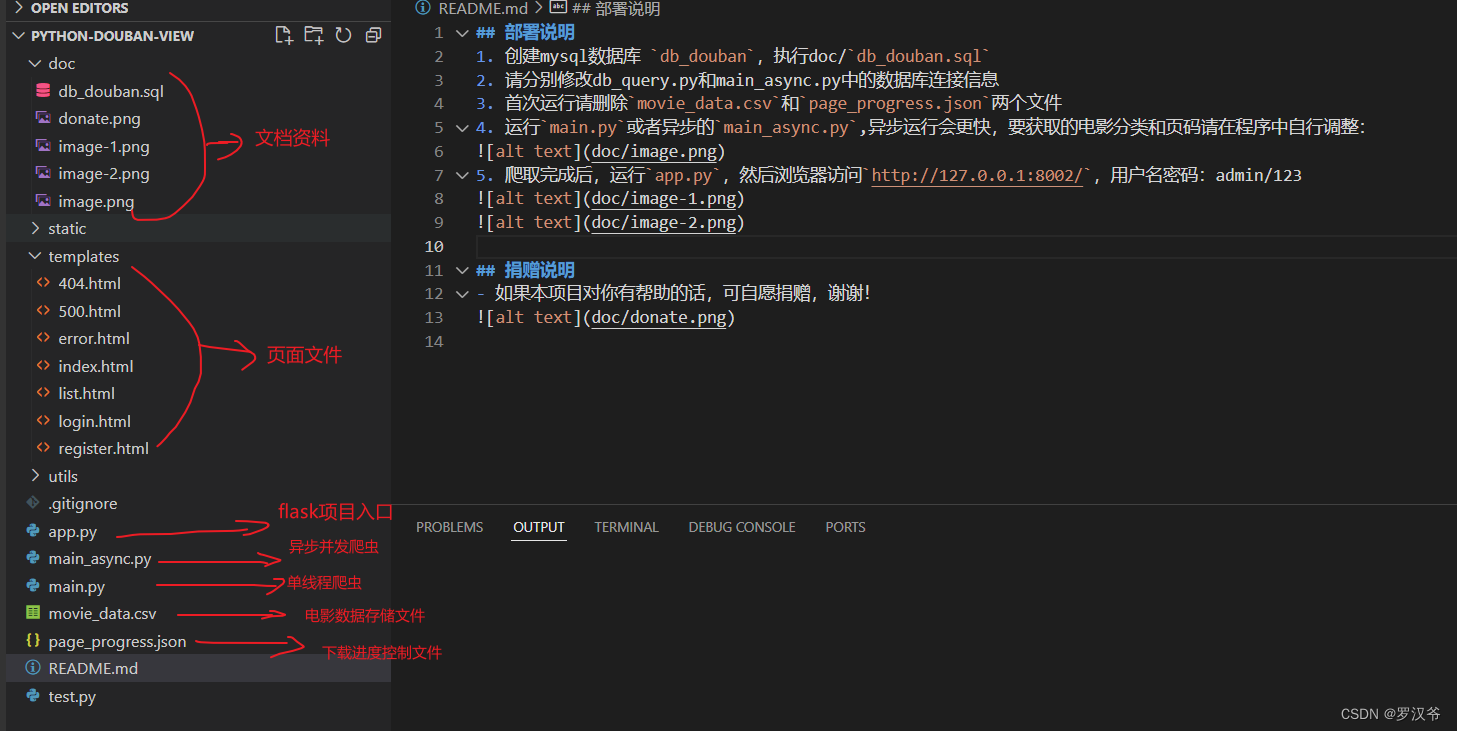
核心模块
电影爬虫
""" 异步并发爬虫 """ # 本次运行获取的最大页数 MAX_PAGES = 5 # 进度控制文件 PAGE_PROGRESS_FILE = "page_progress.json" # 电影类型 MOVIE_TYPES = ["剧情", "喜剧", "动作", "爱情", "科幻", "动画"] # CSV文件名 CSV_NAME = "movie_data.csv" # CSV头 CSV_HEADS = [ "id", "movie_id", "title", "year", "directors", "casts", "rating", "cover", "country", "summary", "types", "lang", "release_date", "time", "url", ] # 上映日期匹配正则,剔除非数字和- RELEASE_DATE_REMOVE_RE = r"[^0-9-]" engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/db_douban") def get_id(): return str(random.randint(1, 100000000)) + str(time.time()).split(".")[1].strip() class Spider: def __init__(self): self.movie_page_url = "https://m.douban.com/rexxar/api/v2/movie/recommend?" self.movie_detail_url = "https://movie.douban.com/subject/{}/" self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36", "Referer": "https://movie.douban.com/explore", } self.movie_types = MOVIE_TYPES self.page_progress = {} # 需要抓取的页面数 self.total_pages = 0 self.completed_pages = 0 self.global_progress_bar = None def init(self): # 每次跑之前,先删除之前的csv文件 if os.path.exists(CSV_NAME): os.remove(CSV_NAME) with open(CSV_NAME, "w", newline="", encoding="utf-8") as writer_f: writer = csv.writer(writer_f) writer.writerow(CSV_HEADS) def load_page_progress(self): if os.path.exists(PAGE_PROGRESS_FILE): with open(PAGE_PROGRESS_FILE, "r", encoding="utf-8") as f: # 判断文件内容是否为空 if os.stat(PAGE_PROGRESS_FILE).st_size == 0: # 初始化页面进度 print("初始化页面进度") self.page_progress = {} self.save_page_progress() else: self.page_progress = json.load(f) def save_page_progress(self): with open(PAGE_PROGRESS_FILE, "w", encoding="utf-8") as f: json.dump(self.page_progress, f, ensure_ascii=False) async def get_movie_pages(self, session, type_name): start_page = self.page_progress.get(type_name, 1) if start_page <= MAX_PAGES: for page in range(start_page, MAX_PAGES + 1): # print(f'{type_name}第{page}页:') start_time = time.time() params = {"start": (page - 1) * 20, "count": 10, "tags": type_name} try: async with session.get( self.movie_page_url, headers=self.headers, params=params ) as resp: resp.raise_for_status() respJson = await resp.json() movie_list = respJson["items"] for i, m in enumerate(movie_list): if m["type"] == "movie": await self.process_movie(session, m) # progress_bar.update(round(1/len(movie_list))) self.page_progress[type_name] = page + 1 # 记录进度 self.save_page_progress() # 刷新全局进度 self.update_global_progress() except Exception as e: print(f"处理:{type_name}第{page}页失败: {e}") traceback.print_exc() continue async def process_movie(self, session, movie): movie_data = [] movie_data.append(get_id()) movie_data.append(movie["id"]) movie_data.append(movie["title"]) movie_data.append(movie["year"]) async with session.get( self.movie_detail_url.format(movie["id"]), headers=self.headers ) as resp: resp.raise_for_status() html_text = await resp.text() path = etree.HTML(html_text) # 导演 movie_data.append(",".join(path.xpath('//a[@rel="v:directedBy"]/text()'))) # 主演 movie_data.append(",".join(path.xpath('//a[@rel="v:starring"]/text()'))) # 评分 movie_data.append(path.xpath('//strong[@property="v:average"]/text()')[0]) # 封面 movie_data.append(path.xpath('//img[@rel="v:image"]/@src')[0]) # 国家 movie_data.append( path.xpath( '//span[contains(text(),"制片国家")]/following-sibling::br[1]/preceding-sibling::text()[1]' )[0].replace(" / ", ",") ) # 摘要 movie_data.append(path.xpath('//span[@property="v:summary"]/text()')[0].strip()) # 类型 movie_data.append( ",".join(path.xpath('//div[@id="info"]/span[@property="v:genre"]/text()')) ) # 语言 movie_data.append( path.xpath( '//span[contains(text(),"语言")]/following-sibling::br[1]/preceding-sibling::text()[1]' )[0] ) # 上映日期 movie_data.append( re.sub( RELEASE_DATE_REMOVE_RE, "", path.xpath('//span[@property="v:initialReleaseDate"]/text()')[0][:10], ) ) # 时长(空处理) # print(movie["id"]) movie_time = path.xpath('//span[@property="v:runtime"]/text()') if len(movie_time) > 0: movie_data.append(movie_time[0]) else: movie_data.append("") # url movie_data.append(self.movie_detail_url.format(movie["id"])) self.save_to_csv(movie_data) def save_to_csv(self, row): with open(CSV_NAME, "a", newline="", encoding="utf-8") as f: writer = csv.writer(f) writer.writerow(row) def clean_csv(self): print("===========清理数据============") df = pd.read_csv(CSV_NAME, encoding="utf-8") df.drop_duplicates(subset=["movie_id"], keep="first", inplace=True) print("存储到数据库...") df.to_sql("tb_movie", con=engine, index=False, if_exists="append") print("清理重复数据...") engine.connect().execute( text( "delete t1 from tb_movie t1 inner join (select min(id) as id,movie_id from tb_movie group by movie_id having count(*) > 1) t2 on t1.movie_id=t2.movie_id where t1.id>t2.id" ) ) def update_global_progress(self): self.completed_pages += 1 # print(self.completed_pages) self.global_progress_bar.update(1) self.global_progress_bar.refresh() async def run(self): self.init() self.load_page_progress() # self.total_pages = MAX_PAGES*len(MOVIE_TYPES) - sum(self.page_progress.get(type_name, 1) for type_name in MOVIE_TYPES) for type_name in MOVIE_TYPES: if MAX_PAGES > self.page_progress.get(type_name, 1): self.total_pages += MAX_PAGES + 1 - self.page_progress.get(type_name, 1) print(self.total_pages) if self.total_pages > 0: self.global_progress_bar = tqdm( total=self.total_pages, desc="progress", unit="page", colour="GREEN" ) async with aiohttp.ClientSession() as session: tasks = [ self.get_movie_pages(session, type_name) for type_name in self.movie_types ] await asyncio.gather(*tasks) # 请求结束后,清空页面进度 # self.page_progress = {} # self.save_page_progress() self.global_progress_bar.close() self.clean_csv() if __name__ == "__main__": loop = asyncio.get_event_loop() spider = Spider() loop.run_until_complete(spider.run())电影可视化
接口代码
from flask import Flask, render_template, request, redirect, url_for, session from utils import db_query app = Flask(__name__) app.secret_key = "mysessionkey" # 统一请求拦截 @app.before_request def before_request(): # 利用正则匹配,如果/static开头和/login, https://blog.csdn.net/logout,/register的请求,则不拦截;其他的判断是否已登录 if ( request.path.startswith("/static") or request.path == "/login" or request.path == "https://blog.csdn.net/logout" or request.path == "/register" ): return # 如果没有登录,则跳转到登录页面 if not session.get("login_username"): return redirect(url_for("login")) # 首页 @app.route("/") def index(): # 获取电影统计数据 movie_stats = db_query.fetch_movie_statistics() # 获取电影分类统计 movie_type_distribution = db_query.fetch_movie_type_distribution() # 获取电影评分统计 movie_rating_distribution = db_query.fetch_movie_rating_distribution() print(movie_rating_distribution) return render_template( "https://blog.csdn.net/IndexMan/article/details/index.html", login_username=session.get("login_username"), movie_stats=movie_stats, movie_type_distribution=movie_type_distribution, movie_rating_distribution=movie_rating_distribution, ) # 登录 @app.route("/login", methods=["GET", "POST"]) def login(): if request.method == "POST": req_params = dict(request.form) # 判断用户名密码是否正确 sql = "SELECT * FROM `tb_user` WHERE `username` = %s AND `password` = %s" params = (req_params["username"], req_params["password"]) if len(db_query.query(sql, params)) > 0: # 存储session session["login_username"] = req_params["username"] return redirect(url_for("index")) else: return render_template( "error.html", error="用户名或密码错误", ) elif request.method == "GET": return render_template("login.html") # 退出 @app.route("https://blog.csdn.net/logout") def logout(): session.pop("login_username", None) return redirect(url_for("index")) # 注册 @app.route("/register", methods=["GET", "POST"]) def register(): if request.method == "POST": req_params = dict(request.form) if req_params["password"] == req_params["password_confirm"]: # 判断是否已存在该用户名 sql = "SELECT * FROM `tb_user` WHERE `username` = %s" params = (req_params["username"],) result = db_query.query(sql, params) if len(result) > 0: return render_template( "error.html", error="用户名已存在", ) sql = "INSERT INTO `tb_user` (`username`, `password`) VALUES (%s, %s)" params = ( req_params["username"], req_params["password"], ) db_query.query(sql, params, db_query.QueryType.NO_SELECT) return redirect(url_for("login")) else: return render_template( "error.html", error="两次密码输入不一致", ) elif request.method == "GET": return render_template("register.html") @app.route("https://blog.csdn.net/list") def movie_list(): # 查询数据库获取电影列表 movies = db_query.fetch_movie_list() # 假设此函数返回一个包含电影信息的列表 # 渲染并返回list.html,同时传递movies数据 return render_template( "list.html", login_username=session.get("login_username"), movies=movies ) @app.errorhandler(404) def page_not_found(error): return render_template("404.html"), 404 @app.errorhandler(500) def system_error(error): return render_template("500.html"), 500 if __name__ == "__main__": # 静态文件缓存自动刷新 app.jinja_env.auto_reload = True app.run(host="127.0.0.1", port=8002, debug=True)首页
首页

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...