

💓博主CSDN主页:杭电码农-NEO💓
⏩专栏分类:高阶数据结构专栏⏪
🚚代码仓库:NEO的学习日记🚚
🌹关注我🫵带你学习更多数据结构
🔝🔝

高阶数据结构
- 1. 前言
- 2. 初识B树
- 3. B树的插入分析
- 4. B树的规则再分析
- 5. B树模拟实现
- 6. 总结以及拓展
1. 前言
相信大家之前或多或少都听说过B树或B+树,奔跑文章将从认识B树到手撕B树(注意不是B减树,是B树),一步一步带你吃透它!
本章重点:
本篇文章着重讲解B树的概念和它的性质,并且回一步一步分析它的插入规则,为后续手撕B树做铺垫. 手撕B树指挥实现插入版本,删除过于复杂这里不多做讨论, 期间回将B树和传统的搜索结构如哈希,红黑树等做对比.
B树学习难度较大, 请大家耐心学习
2. 初识B树
首先要明确一点, B树是一个搜索结构.那么它和传统的搜索结构,比如红黑树, 哈希等有什么区别呢?先请看下图:
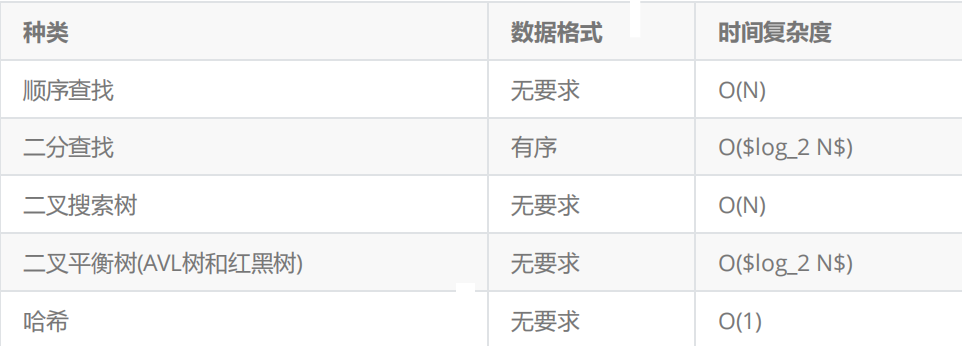
以上结构适合用于数据量相对不是很大,能够一次性存放在内存中,进行数据查找的场景。如果数据量很大,比如有100G数据,无法一次放进内存中,那就只能放在磁盘上了. 是的传统的搜索结构用于内查找,也就是在内存中查找,但B树是用于外查找,就是磁盘或文件中的查找
一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
- 根节点至少有两个孩子
- 每个分支节点都包含k-1个关键字和k个孩子,其中 ceil(m/2) ≤ k ≤ m ceil是向上取整函数
- 每个叶子节点都包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m
- 所有的叶子节点都在同一层
- 每个节点中的关键字从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
- 每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)其中,Ki(1≤i≤n)为关键字,且Ki
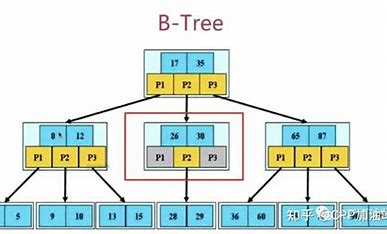
光看B树的定义是非常抽象的, 但定义中你需要记住的关键点是每个节点中的关键字是有序的, 并且节点的结构是: 关键字,孩子,关键字,孩子…实际上当M=2时,B树就是一颗二叉树, B树的节点中是一个数组,可存放多个数据
3. B树的插入分析
现在我们使用一个B树做插入的案例,来解释B树的这些性质. 设M=3,即三叉树,每个节点存两个数据,和三个孩子区域的划分
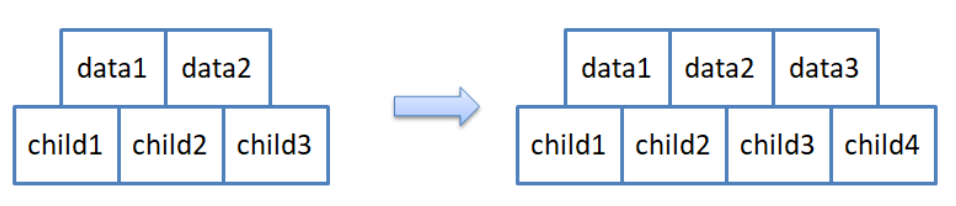
注意:孩子永远比数据多一个。
用后面的图可以更好的演示B树的分裂
用序列{53, 139, 75, 49, 145, 36, 101}构建B树的过程如下:第一步:
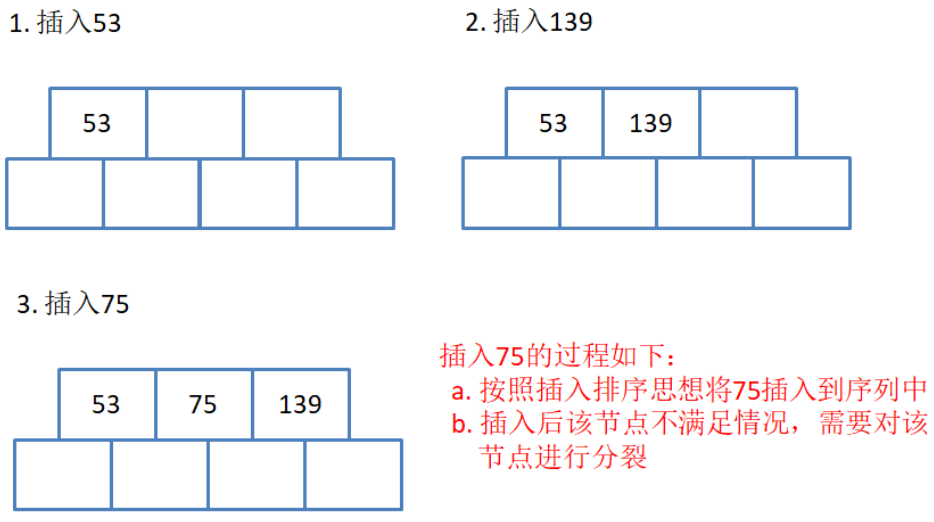
由于M=3,一个节点只能存储两个数据,所以当插入75时,需要对这棵树做分裂. 怎样分裂呢? 普遍的做法是: 1. 找到节点中的中间数据(图中为75). 2. 创建一个新节点, 将中间数据挪动到新节点. 3. 以中间数据(75)作为分割, 将中间数据左边的所有节点保持不动, 将中间数据右边的所有节点移动至另外一个新节点. 4. 将中间数据所在的新节点当父亲, 左右两个兄弟节点当儿子, 连接起来. 具体结果看下图:
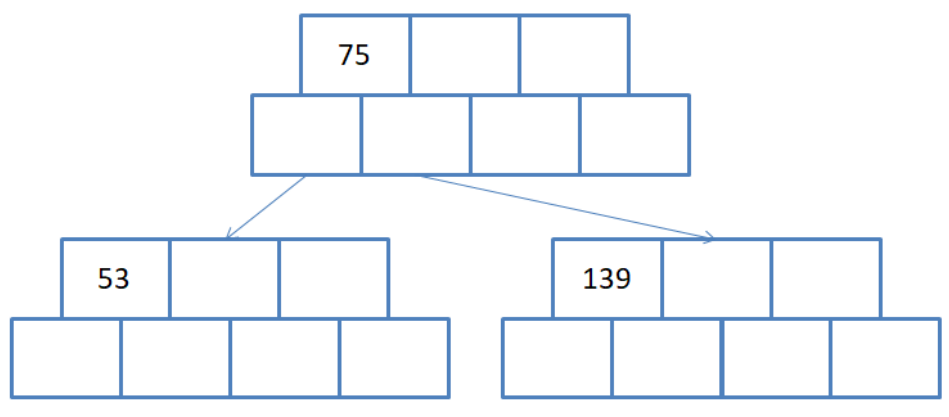
这样做恰好满足了B树的一个性质: A1,K1,A2,K2数组中, A1,这里代表75的左孩子,是小于K1的,K1也就是75. 而A2,对应是139所在的节点, 是大于K1的.
第二步:
注意: B树的插入都是在叶子节点进行的,当叶子节点不符合B树规则时才会向上形成新的节点,也就是所谓的分裂操作
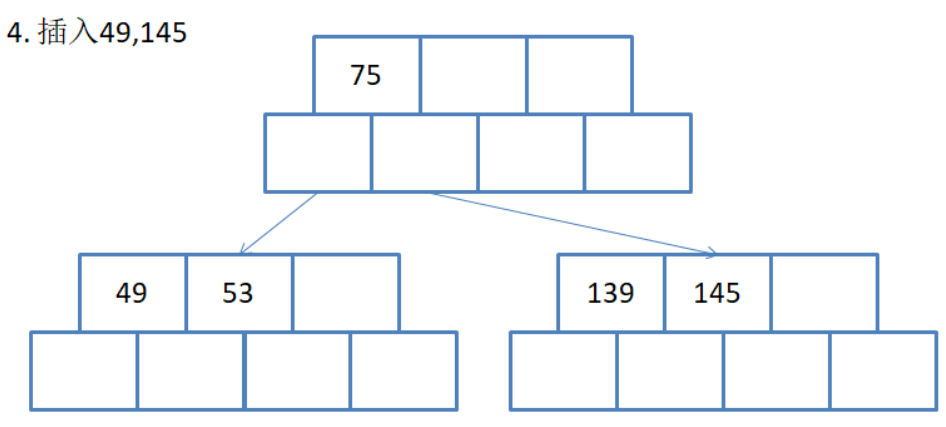
这两次插入都没违反规则
第三步:
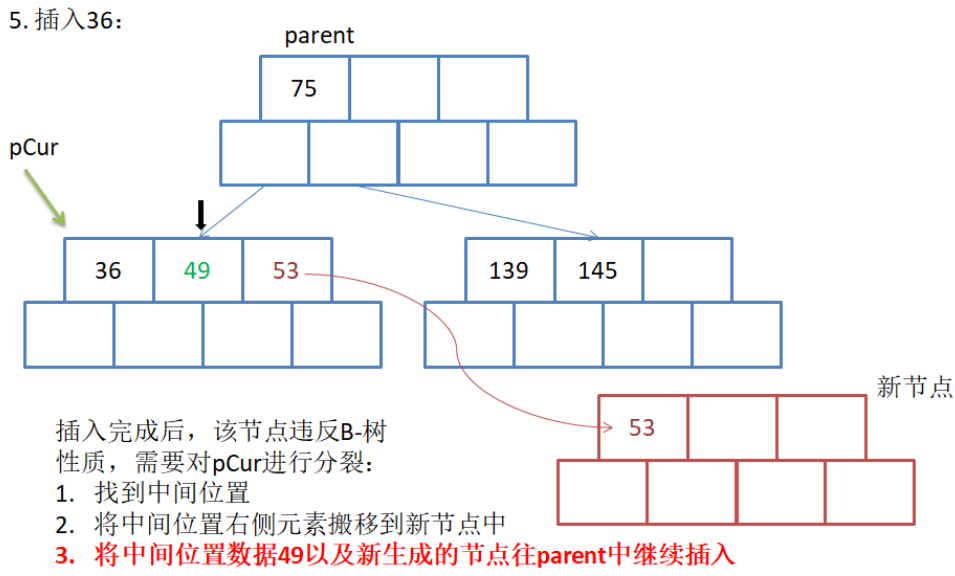
这一次插入36,会导致左下角的节点违反B树的规则,所以需要进行分裂. 本次分裂和上次分裂基本一致,唯一的区别就是, 中间数据,也就是49,不需要再重新形成一个新节点并将49放入,数据49可以直接被放在数据75所在的节点中. 具体的结果图如下:
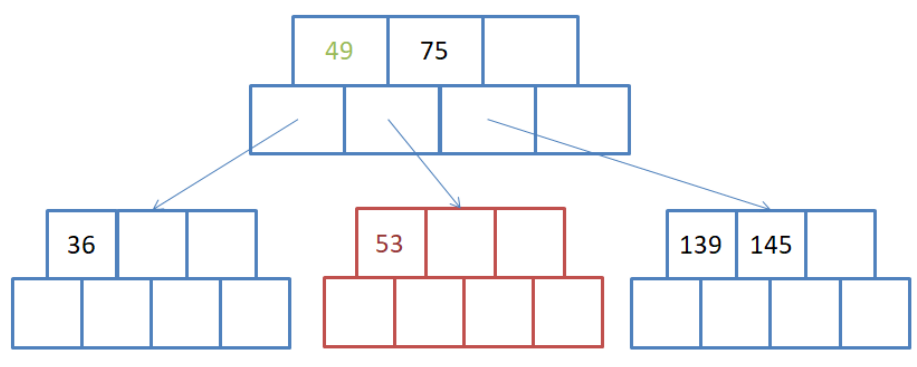
并且也要满足上面所说的A1
注意, 节点中只存了两个数据, 数据下面的数据存储的是孩子节点的地址
第四步:
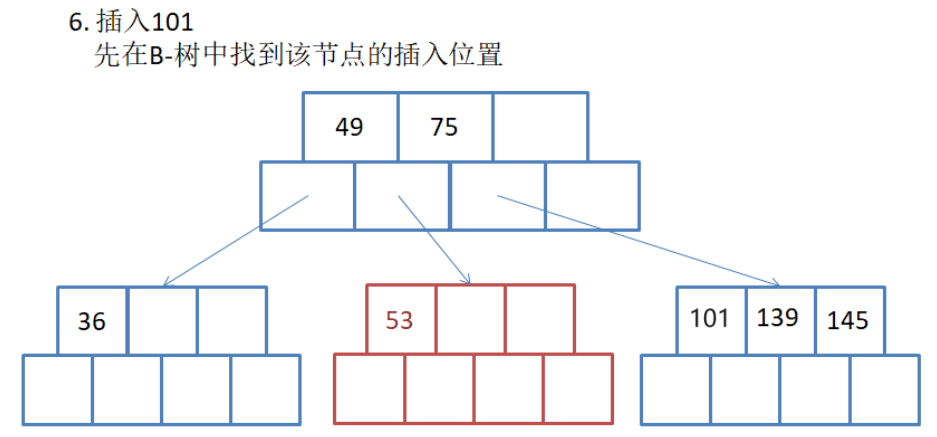
看见此图,聪明的你肯定已经想到了需要进行分裂, 将中间数据139提到父亲节点. 那么更聪明的人也发现了,此时父亲节点的数据也是三个,不符合规则, 所以父亲节点也需要进行分裂. 分裂的规则和之前是一样的,这里就不再画图了,大家可以自己尝试去画一下图.
4. B树的规则再分析
了解了B树是如何分裂了之后,我们在倒过来看看B树的规则,就好理解多了:
- 根节点至少有两个孩子: 为什么呢?因为B树进行一次分裂之后, 至少会分裂出两个孩子.
- 第二点解释: 孩子的数量永远比数据多一个,K一般就取值为M
剩下的我相信大家都能理解了
5. B树模拟实现
首先是基本的B树节点的结构:
template
struct BTreeNode { K _keys[M];//m个孩子,m-1个关键字.但为了方便插入再分裂,定义为M个关键字,M+1个child BTreeNode class BTree { typedef BTreeNode 当然在实现B树的插入之前, 我们需要先实现Find函数, 如果插入的值已存在,那么就什么都不用做了. 当前我们也可以提前封装好插入节点的逻辑
pair
对于B树的插入来说, 步骤就是上面分析过的步骤,但是代码实现是比较抽象,比较难懂的, B树的模拟实现本身就属于拓展内容, 如果你理解不了也是没关系的, 知道B树的性质和用途就好了
bool Insert(const K& key) { //第一次插入的逻辑 if (_root == nullptr) { _root = new Node; _root->_keys[0] = key; _root->_num++; return true; } pair
6. 总结以及拓展
B树模块的重点是它的分裂逻辑和使用场景, 并且B树在实际生产中运行并不多, 因为有更好的数据结构: B+树或是B*树来代替它. 但是学习后两者的前提是需要你知晓B树的性质, 所以学习不是一蹴而就的,是需要持之以恒的
🔎 下期预告:B+树,B*树,MySQL索引讲解 🔍

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...