

目录
0.三者主要作用
1.元组
元组特点
创建元组
元组解包
可变和不可变元素元组
2.集合
集合特点
创建集合
集合元素要求
集合方法
访问与修改
子集和超集
相等性判断
集合运算
不可变集合
3.字典
字典特点
字典创建和常见操作
字典内置方法
pprin模块
0.三者主要作用
可以使用元组存储一个固定的元素列表 可以使用集合存储和快速访问不重复的元素 可以使用字典存储键值对并使用这些关键字来快速访问元素1.元组
元组特点
元组跟列表相似,但是元组中的元素是固定的(固定元素+固定顺序)。 也就是说,一旦一个元组 A 被创建,就无法对元组 A 中的元素进行添加、删除、替换或重新排序。(但是可以访问) 但是可以将元组 A 进行像列表相似的操作然后创建新元组 B,比如 B = 2 * A,B = A[2: 4],C = A + B 等。 再比如 A = (1, 2, 3),B = (1, 2, 3,4)时,B = A 进行赋值操作也是可行的。 注意,B[: -1] = B[0: -1] = B[0: -1 + len(B)] 。创建元组
# 创建一个空元组
t1 = ()
t2 = tuple()
# 创建一个具有 3 个元素的元组
t3 = (1, 2, 3)
# 使用 tuple 函数通过列表创建一个元组
t4 = tuple([x for x in range(5)])
# 使用 tuple 函数通过字符串创建一个元组
t5 = tuple("abcdabcd")
# t5 = ('a', 'b', 'c', 'd', 'a', 'b', 'c', 'd')
# 使用 list 函数将元组转换为列表
t6 = list(t5)
# t6 = ['a', 'b', 'c', 'd', 'a', 'b', 'c', 'd']
创建只有一个元素的元组
# 创建一个只有一个元素的元组 t1 = (4,) # 注意有个逗号 t1 = 4, # 元组 t2 = (1) # t2 不是元组,而是一次赋值,将 1 赋给 t2 print(type(t2), t2) #1
元组解包
在Python中,元组解包是一种将元组中的多个值赋给多个变量的方式。这可以在赋值操作中直接完成,也可以在函数调用中使用来提供参数。
解包可以使用星号表达式来选择性地解包元组中的部分元素。
# -*- coding: utf-8 -*-
# 直接解包
tup = (1, 2, 3)
a, b, c = tup
print(a, b, c)
# a = 1, b = 2, c = 3
# 使用星号表达式解包
tup = (1, 2, 3, 4, 5)
x, y, *rest = tup
print(x, y, rest)
# x = 1, y = 2, rest = [3, 4, 5]
# 函数调用中的解包
def func(v1, v2, v3):
print(v1, v2, v3)
args = (1, 2, 3)
# func(args)
# TypeError: func() missing 2 required positional arguments: 'v2' and 'v3'
func(*args) # 输出: 1 2 3
# 函数返回多个值时的解包
def get_values():
return 1, 2, 3
a, b, c = get_values() # a = 1, b = 2, c = 3
可变和不可变元素元组
一个元组包含了一个固定的元素列表。一个元组里的一个个体元素可能是易变的。如果一个元组的元素都是不可变的,那么这个元组被称为元素不可变元组。否则是元素可变元组。
# -*- coding: utf-8 -*-
# 元素不可变元组
data = (1, 2, 3) # 这里1, 2, 3都是不可变的
data2 = ("abc", "hello", "world") # 这里字符串"abc", "hello", "world"都是不可变的
# data2[0][0] = 'x'
# 将会报错:TypeError: 'str' object does not support item assignment
# 元素可变元组
data3 = ([1, 2, 3], ["x", "y"]) # [1, 2, 3]是列表,是可变的
data3[0][0] = 100 # 不会报错
print(data3) # ([100, 2, 3], ['x', 'y'])
# 这里是将元组的第一个元素,是个列表,这个列表的第一个元素的地址进行改变
# 而没有该彼岸元组第一个元素的地址,即还是这个列表
# 元组本身不可变和可变是指在元组内容初始化后,不能更改元组元素的内存地址
value = [99, 99]
# data3[0] = value
# 将会报错:TypeError: 'tuple' object does not support item assignment
# 这里试图将data3这个元组的第一个元素的地址换成[99, 99]的地址,是非法的
# 因为元组是不可变的
2.集合
集合特点
集合与列表相似,但是集合中的元素时不重复且不是按任何特定顺序放置的。 集合内的元素不能是列表或集合。创建集合
# -*- coding: utf-8 -*-
# 创建一个空集
set1 = set() # 注意 set2 = {} 是创建了一个字典
# 创建 1 个元素的集合
set2 = {5}
# 创建 3 个元素的集合
set3 = {1, 3, 5}
# 用 set 函数通过元组创建集合
set4 = set((1, 3, 5))
# 用 set 函数通过列表创建集合
set5 = set([x ** 2 for x in range(5)])
# 用 set 函数通过字符串创建集合
set6 = set("helloworld")
print(set6) # 注意集合是无序的,每次打印可能会不一样
# 用 list 函数通过集合创建一个列表
list1 = list(set5)
# 用 tuple 函数通过集合创建一个元组
t1 = tuple(set5)
集合元素要求
集合中的每个元素必须是可哈希的,hashable。 python 中的每一个对象都有一个哈希值,而且如果在对象的生命周期里该对象的哈希值从未改变,那么这个对象是哈希的,也就是不可变的。 列表、集合和字典是不可哈希的;数字、字符串和元组是哈希的。# -*- coding: utf-8 -*-
set1 = {1, 3, 5} # ok
set2 = {[1, 2], [3]} # error:TypeError: unhashable type: 'list'
集合方法
访问与修改
# -*- coding: utf-8 -*-
set1 = {1, 2, 3, "a", "b"}
# 对集合添加一个元素
set1.add(4)
print(set1)
# update 方法 # 单个元素用 add,可迭代的对象用 update
set1 = {1, 2, 3}
set1.update("abc")
print(set1) # {1, 2, 3, 'b', 'c', 'a'}
set1.update({2, 3, 4})
print(set1) # {1, 2, 3, 'b', 'c', 4, 'a'}
set1.update([4, 5, 6])
print(set1) # {1, 2, 3, 'b', 'c', 4, 5, 6, 'a'}
# 删除元素
set1.remove(3) # 删除元素,不存在则抛出一个 KeyError 异常
print(set1.pop())
set1.discard(3) # 删除元素,不存在不报错
# len 函数、max 函数、min 函数、sum 函数
print(len(set1))
# 可以使用 for 循环遍历一个集合中的所有元素
for x in set1:
print(x)
# in 和 not in
print(100 in set1)
子集和超集
使用 issubset()方法和 issuperset()方法set1 = {1, 2, 3}
set2 = {1, 3, 2, 4}
print(set1.issubset(set2)) # True
print(set2.issuperset(set1)) # True
比较运算符

相等性判断
set1 = {1, 2, 3}
set2 = {1, 3, 2, 4}
set3 = {3, 1, 2,2}
print(set1 == set2) # False
print(set1 != set2) # True
print(set1 == set3) # True
集合运算
并集、交集、差集、对称差 集合运算是带有返回值,用来创建新集合,而不会改变原有集合 并集,用 union 方法或者 | 运算符set1 = {1, 2, 4}
set2 = {1, 3, 5}
print(set1.union(set2)) # {1, 2, 3, 4, 5}
print(set1 | set2) # {1, 2, 3, 4, 5}
交集,用 intersection 方法或者 &运算符
print(set1.intersection(set2))
print(set1 & set2) # {1}
差集,用 difference 方法或者 -运算符(A–B 表示出现在集合 A 但不出现在集合 B 的元素的集合)
print(set1.difference(set2))
print(set1 - set2) # {2, 4}
对称差,用 symmetric_difference 方法或者 ^运算符
print(set1.symmetric_difference(set2))
print(set1 ^ set2) # {2, 3, 4, 5}
不可变集合
# -*- coding: utf-8 -*-
# 可变集合
set1 = {1, 2, 3, "a", "b"}
set1.add(4) # ok
print(set1) # {1, 2, 3, 4, 'b', 'a'}
# 不可变集合
data = [1, 2, 3]
set2 = frozenset(data) # 转变为不可变集合
# set2.add(4) # AttributeError: 'frozenset' object has no attribute 'add'
3.字典
字典特点
一个字典是按照关键字存储值的集合,简称存储“键值”的集合。 它通过使用关键字实现快速获取,删除和更新值。这些关键字很像下标运算符。 在一个列表中,下标是整数; 在一个字典中,关键字必须是一个可哈希对象。 一个字典不能包含有重复的关键字 ,每个关键字都对应着一个值。 一个关键字和它对应的值形成存储在字典的一个键值对。这种数据结构被称为“字典”。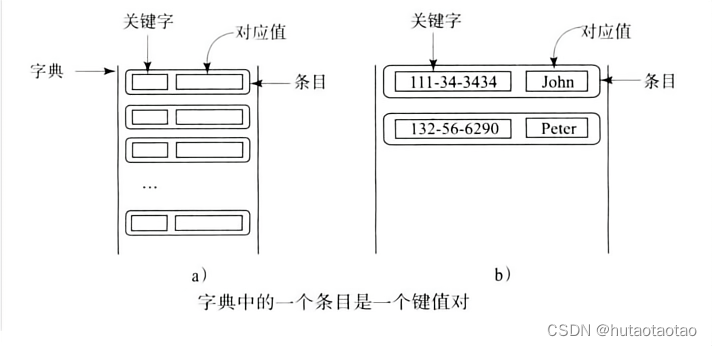
字典创建和常见操作
条目 = 关键字(key) : 值(value) 关键字必须是可哈希的,比如字符串和数字,元组。 值可以是任意类型,比如是不可哈希的列表、字典、集合。# 创建空字典
d0 = {}
# 创建具有 3 个条目的字典
d1 = {11: "bob", 12: "other", "ras2": 234}
print(type(d1)) #
print(d1) # {11: 'bob', 12: 'other', 'ras2': 234}
创建字典时指明key和value的类型
在Python中创建字典时,通常不需要显式指定键(key)和值(value)的类型,因为字典是一种动态类型的数据结构,它可以容纳任意类型的键和值。然而,如果你想在字典中指定键和值的类型,可以使用类型提示(Type Hints)来提供额外的信息,这在代码的可读性和维护性方面是有益的。
# -*- coding: utf-8 -*-
from typing import Dict, Any, Union
# 使用类型提示声明字典的键和值的类型
my_dict: Dict[str, Union[int, str]] = {
"key1": 42,
"key2": "value2",
"key3": 3.14 # 这个值将被视为 Union[int, str] 中的任一类型
}
# 打印字典
print(my_dict)
请注意,类型提示仅仅是一种静态分析工具,对于 Python 解释器本身并没有强制约束。它主要用于提高代码的可读性和与其他开发者的交流。
添加、替换和获取值# -*- coding: utf-8 -*-
# 添加一个条目到字典中,dictionaryName[key] = value
d1 = {"22-23-1827": "bob"}
d1["22-23-1828"] = "tom"
print(d1) # {'22-23-1827': 'bob', '22-23-1828': 'tom'}
# 如果这个关键字在字典中已经存在,添加条目的语法将替换该关键字对应的值
d1["22-23-1828"] = "xxxxx"
print(d1) # {'22-23-1827': 'bob', '22-23-1828': 'xxxxx'}
# 从字典中获取一个值,varName = dictionaryName[key]
x = d1["22-23-1827"]
print(x)
# 如果字典中没有这个关键字,将抛出一个 KeyError 异常
# print(d1["123456"]) # KeyError: '123456'
删除数据
使用语法:del DictName[key]
d2 = {'22-23-1827': 'tom', '22-23-1828': 'bob'}
del d2['22-23-1828']
print(d2) # {'22-23-1827': 'tom'}
# 如果字典中没有这个关键字,将抛出一个 KeyError 异常
遍历全部的键值对
使用 for 循环来遍历字典的所有
关键字
d2 = {'22-23-1827': 'tom', '22-23-1828': 'bob'}
for key in d2:
print(key + " : " + d2[key])
"""
22-23-1827 : tom
22-23-1828 : bob
"""
len 函数获取键值对的个数
d2 = {'22-23-1827': 'tom', '22-23-1828': 'bob'}
print(len(d2)) # 2
in 和 not in 判断关键字是否在字典中
d2 = {'22-23-1827': 'tom', '22-23-1828': 'bob'}
print('22-23-1827' in d2) # True
print('123456' in d2) # False
print('tom' in d2) # False
相等性判断
d1 = {'22-23-1827': 'tom', '22-23-1828': 'bob'}
d2 = {'22-23-1828': 'bob', '22-23-1827': 'tom'}
print(d1 == d2) # True
print(d2 != d1) # False
注意字典和字典之间不能用 <, <=, >, >= 这几个比较运算符,否则会抛出 TypeError 异常
字典内置方法
 get(key)方法,当 key 不在字典时,会返回一个空值 None,类似于 dictionaryName[key]
get(key, elseValue)
,当 key 不在字典时,返回值 elseValue
get(key)方法,当 key 不在字典时,会返回一个空值 None,类似于 dictionaryName[key]
get(key, elseValue)
,当 key 不在字典时,返回值 elseValue
data = {'tom': 18, 'bob': 19}
print(data.get('tom')) # 18
print(data.get('zhang')) # None
print(data.get('zhang', 99)) # 99
setdefault(key, elseValue)
方法,如果 key 在字典,则返回该关键字对应的值
如果 key 不在字典,则添加键值对 key: elseValue,并返回值 elseValue
data = {'tom': 18, 'bob': 19}
print(data.setdefault('tom', 100)) # 18
print(data) # {'tom': 18, 'bob': 19}
print(data.setdefault('zhang', 100)) # 100
print(data) # {'tom': 18, 'bob': 19, 'zhang': 100}
print(data.setdefault('zhang', 999)) # 100
print(data) # {'tom': 18, 'bob': 19, 'zhang': 100}
pop(key)方法,比 del dictionaryName[key]多了一个作用,如果 key 不存在则 KeyError 异常
pop(key, elseValue)
data = {'tom': 18, 'bob': 19}
ret = data.pop("tom")
print(data) # {'bob': 19}
print(ret) # 18
# data.pop("xxx") # KeyError: 'xxx'
ret = data.pop("xxx", 100) # 不会KeyError
print(data) # {'bob': 19}
print(ret) # 100
update 方法用来字典合并
# 相同 key 的部分新的字典会覆盖旧的字典
old_dict = {"部门": "财务", "姓名": "王涛", "电话": 12345678900}
new_dict = {"性别": "男", "部门": "技术", "电话": 12734735335}
old_dict.update(new_dict)
print(old_dict) # {'部门': '技术', '姓名': '王涛', '电话': 12734735335, '性别': '男'}
keys()、values()和items()方法
data = {'tom': 18, 'bob': 19}
x1 = data.keys()
y1 = tuple(x1)
print(x1) # dict_keys(['tom', 'bob'])
print(y1) # ('tom', 'bob')
print()
x2 = data.values()
y2 = list(x2)
print(x2) # dict_values([18, 19])
print(y2) # [18, 19]
print()
x3 = data.items()
y3 = tuple(x3)
print(x3) # dict_items([('tom', 18), ('bob', 19)])
print(y3) # (('tom', 18), ('bob', 19))
print()
pprin模块
漂亮打印:pprint 模块的 pprint 函数和 pformat 函数# -*- coding: utf-8 -*-
import pprint
message = "我爱程序设计,我要好好学习,天天向上。"
count_dict = {}
for character in message:
count_dict[character] = count_dict.get(character, 0) + 1
#print(count_dict)
#print()
pprint.pprint(count_dict)
print()
new = pprint.pformat(count_dict)
print(new)
print()
运行结果
{'。': 1,
'上': 1,
'习': 1,
'向': 1,
'天': 2,
'好': 2,
'学': 1,
'序': 1,
'我': 2,
'爱': 1,
'程': 1,
'要': 1,
'计': 1,
'设': 1,
',': 2}
{'。': 1,
'上': 1,
'习': 1,
'向': 1,
'天': 2,
'好': 2,
'学': 1,
'序': 1,
'我': 2,
'爱': 1,
'程': 1,
'要': 1,
'计': 1,
'设': 1,
',': 2}
end

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)





还没有评论,来说两句吧...