

目录
前言:
1 部分简单函数的实现
2 push_back和pop_back
3 reserve和resize
4 Print_vector
5 insert和erase
6 拷贝构造
7 构造
8 赋值
9 memcpy的问题
10 迭代器失效
前言:
继上文模拟实现了string之后,接着就模拟实现vector,因为有了使用string的基础之后,vector的使用就易如反掌了,所以这里直接就模拟实现了,那么实现之前,我们先看一下源代码和文档:
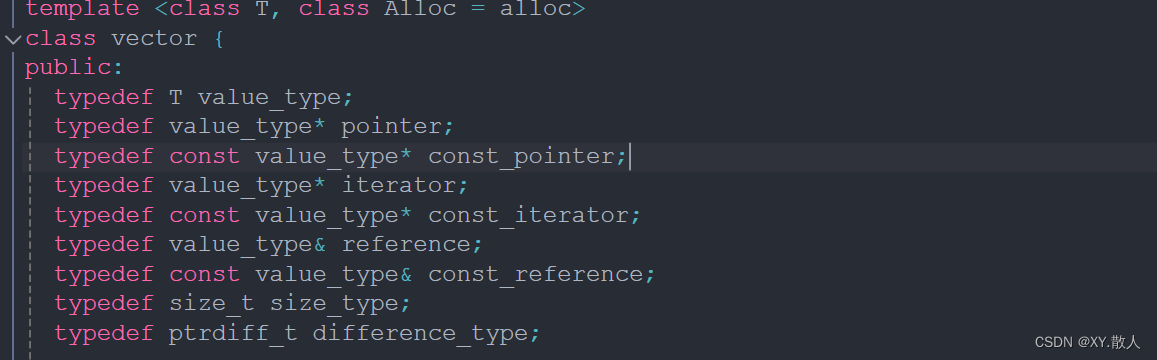
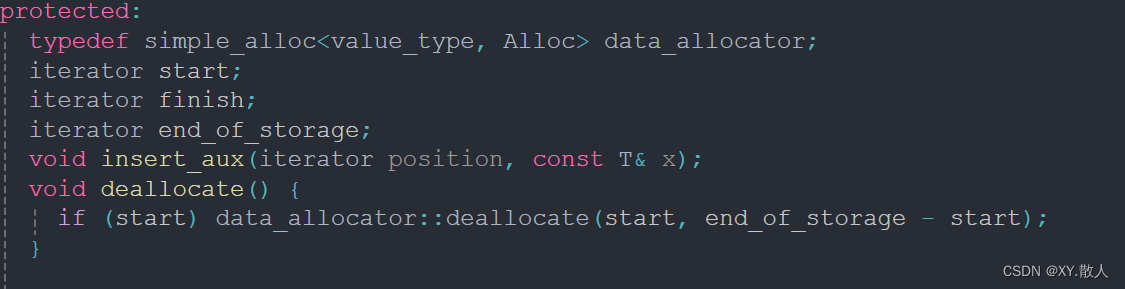
源码不多看,因为很容易绕晕进去,我们从这两个部分得到的信息就够了,首先,vector是一个类模板,即我们可以往里存放许多不同的数据,比如实现一个二维数组,我们可以用vector里面套一个vector,就实现了一个二维数组,为什么说二维数组是一维数组的集合,因为vector的每个空间的start指针指向的空间又是一块连续的空间,即这就是二维数组的构造。
在public的下面有一堆的typedef,这也是不要多看源码的一个原因,很容易绕进去的,比如vector的成员变量的类型是iterator,我们看到value_type*是重命名为iterator了,那么value_type又是T的重命名,即start的类型就是T*,现在我们搞懂了一个问题即模拟实现vector的时候成员变量的类型是模板指针。
那么现在就需要搞懂三个成员变量是什么?
这里就明说了,start是空间的起始位置,finish是空间的最后一个数据的下一个位置,end_of_storage是空间的最后一个位置,所以我们实现size(),capacity()的时候就两两相减就可以了。
基本类型我们了解了,现在就开始模拟实现吧。
1 部分简单函数的实现
这里实现以下函数,size(),capacity(),begin(),end()以及const版本,operator[]以及const版本,empty(),析构函数,注意的就是返回值返回类型即可:
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin()const
{
return _start;
}
const_iterator end()const
{
return _finish;
}
size_t size()
{
return _finish - _start;
}
size_t capacity()
{
return _end_of_storage - _start;
}
T& operator[](size_t pos)
{
assert(pos <= _finish);
return *(_start + pos);
}
const T& operator[](size_t pos)const
{
assert(pos <= _finish);
return *(_start + pos);
}
bool empty()
{
return _start == _finish;
}
~vector()
{
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}
因为是[]重载,返回的是可以修改的类型所以用引用,这里模拟实现的时候一般都返回size_t类型,这里文档里面的原型,最好保持一致。
2 push_back和pop_back
尾插的时候要注意空间的扩容,扩容的判断条件即是_finish = _end_of_storage的时候,扩容方式和前面实现顺序表链表的时候没有什么区别,使用2倍扩容,但是实际上vs下的vector扩容的时候是使用的1.5倍扩容,我们模拟实现的是linux下的vector,在string模拟实现的时候,我们拷贝数据使用的是strcpy,在这里因为是模板,所以不能使用字符串函数,使用内存拷贝,即使用memcpy,当然memset也可以,但是memcpy就可以了,因为不存在空间重叠的问题。
这里有个隐藏的坑,到后面插入string类的时候才会显式出来,这里先不说,目前插入内置类型是没有问题的:
void push_back(const T& val)
{
//判断扩容
if (_finish == _end_of_storage)
{
size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();
T* tmp = new T[newcapacity];
memcpy(tmp, _start, sizeof(T) * size());
delete[] _start;
_start = tmp;
_finish = _start + size();
_end_of_storage = tmp + newcapacity;
}
*_finish = val;
_finish++;
}
好了,实现好了吗?当然没有,这里也有个坑,即size()的问题,因为实现size()的时候,实现方式是_finish - _start,但是扩容之后,_start的位置已经改变,所以此时size()的实现变成了原来的_finish - 新的_start了,所以会报错,解决方式就是把size()先存起来再使用:
void push_back(const T& val)
{
//判断扩容
if (_finish == _end_of_storage)
{
size_t old_size = size();
size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();
T* tmp = new T[newcapacity];
memcpy(tmp, _start, sizeof(T) * size());
delete[] _start;
_start = tmp;
_finish = tmp + old_size;//容易出错
_end_of_storage = tmp + newcapacity;
}
*_finish = val;
_finish++;
}
这里如果忘了memcpy的使用可以看看文档。
那么push_back就还有一个坑没有解决了,欲知后事如何,请看下去咯。
pop_back的实现相对来说就简单多了,尾删不代表真正的删除数据,指针指向的位置改变就是尾删了,当然,删除操作想要执行就vector就不能为空:
void pop_back()
{
assert(!empty());
_finish--;
}
3 reserve和resize
reserve的实现我们刚才其实已经实现过了,reserve即是扩容,push_back的时候我们已经考虑了扩容,所以代码差不了多少:
void reserve(size_t n)
{
if (capacity() < n)
{
size_t old_size = size();
T* tmp = new T[n];
memcpy(tmp, _start, sizeof(T) * size());
delete[] _start;
_start = tmp;
_finish = tmp + old_size;
_end_of_storage = tmp + n;
}
}
当然,这里的坑和push_back是一样的,只有在插入自定义类型的时候才会出现,先不急,那么这里的扩容就是把newcapacity换成了n而已,其余的是没有差别的。
resize模拟实现的时候就要注意了,如果resize实现的是缩容,就直接移动_finish指针就好了,如果实现的是扩容,那么默认参数我们怎么给呢?

文档里面记录的缺省值是value_type(),而value_type是typedef之后的T,所以我们可以看成T val = T(),看着是有点奇怪?其实一点都不奇怪,比如:
int main()
{
//Test7_vector();
int a = int();
cout << a;
char ch = char();
cout << ch;
return 0;
}
这种代码运行是完全没有问题的,这里的a是0,这里的ch是'\0',这是一种初始化方式,所以我们传参的时候就不能写成0,因为不是所有的vector都是vevtor
void resize(size_t n, const T& val = T())
{
if (size() < n)
{
//扩容
reserve(n);
while (_finish < _start + n)
{
*_finish = val;
_finish++;
}
}
else
{
//删减
_finish = _start + n;
}
}
实际上我们也可以一直尾插T(),但是我们既然知道了我们要多少空间,我们不如直接把空间开完,然后进行赋值就好了,赋值的循环条件是_finish指针到最后扩容的指针的位置,也是比较好理解的。
4 Print_vector
当插入和扩容操作都完成了,下一步就是打印了,当然会有人说初始化怎么办,不急,我们先构造一个空的vector就可以了:
vector()
{}
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_storage = nullptr;
先使用上缺省值,方便测试即可。
Print_vector是用来打印vector的,这里其实变相的考了遍历方式,遍历就是三件套:
void Print_vector(const T& t)
{
for (auto e : t)
{
cout << e << " ";
}
cout << endl;
//typename 告诉编译器这是个类型
typename vector::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
it++;
}
for (int i = 0;i < size();i++)
{
cout << v[i] << " ";
}
}
这是三种遍历方式,下标访问和迭代器使用都是没有问题的,唯独需要注意的是typename那里,如果那里我们使用auto it = v.begin()是没有问题的,但是如果我们使用vector
5 insert和erase
push_back和pop_back是尾插尾删,想要任意位置插入就需要用到insert和erase,文档里面erase有删除一段区间的,这里我们就实现任意位置删除一个数据即可,因为删除一段区间的原理是一样的,因为是任意位置删除和插入,所以实现了之后在push_back和pop_back上也可以复用
insert实现的原理很简单,挪动数据添加数据即可,当然要注意是否要扩容:
void insert(iterator pos, const T& val)
{
assert(pos <= _finish);
assert(pos >= _start);
if (_finish == _end_of_storage)
{
size_t len = pos - _start;
reserve(capacity() == 0 ? 4 : 2 * capacity());
pos = len + _start;//易错点
}
iterator it1 = _finish - 1;
while (it1 >= pos)
{
*(it1 + 1) = *it1;
it1--;
}
*pos = val;
_finish++;
}
当然,为了位置的合法性,这里使用assert断言一下,然后就是判断扩容,但是这里和push_back的size是一个道理,一旦发生扩容,那么pos位置就会变化,while循环的判断就会出问题,所以我们扩容后要更新一下pos的位置,这样才能保证循环的进行。
这里相对string还有一个很好的地方就是我们不用担心end >= pos的那种隐式类型转换比较的发生。
erase的实现原理是一样的,把删除位置的数据往后移动即可。
iterator erase(iterator pos)
{
assert(pos <= _finish);
assert(pos >= _start);
iterator it1 = pos + 1;
while (it1 < _finish)
{
*(it1 - 1) = *it1;
it1++;
}
_finish--;
return pos;
}
那么这里的复用就是:
void push_back(const T& val)
{
insert(end(), val);
}
void pop_back()
{
assert(!empty());
_finish--;
}
6 拷贝构造
这里的拷贝构造没有string拷贝那么复杂了,不用想深拷贝的问题,开空间一直插入就可以了:
vector(const vector& v) { reserve(capacity()); for (auto& e : v) { push_back(e); } }
拷贝构造的最基本要求不能忘记,参数必须是const 的引用类型,不然会发生无限递归的问题。
7 构造
构造是最终boss。

第一个构造,即构造一个空的顺序表,我们可以专门写个函数:
vector()
:_start(nullptr)
,_finish(nullptr)
,_end_of_storage(nullptr)
{}
当然,没有必要,我们给上三个缺省值就可以了,这是一个构造重载。
第二个重载是给n个element,也很好操作,一直尾插就好了:
vector(size_t n, const vector& val = T()) { reserve(n); for (int i = 0;i < n;i++) { push_back(val); } }
第二个也没多大问题,再来看第三个区间构造,实际上第三个重载的最后一个参数可以完全不用管的,没有多大意义,区间构造会再用到一个模板,即类模板的成员函数也可以是个模板:
templatevector(InputIterator first,InputIterator last) { while (first != last) { push_back(*first); first++; } }
以为结束了?还没有,看这段代码:
vectorv3 = { 1,2,3,4,5,6 };
这个构造是不是觉得有点奇怪,好像对不上上面三个构造中的任何一个,因为花括号里面的类型是initializer_list
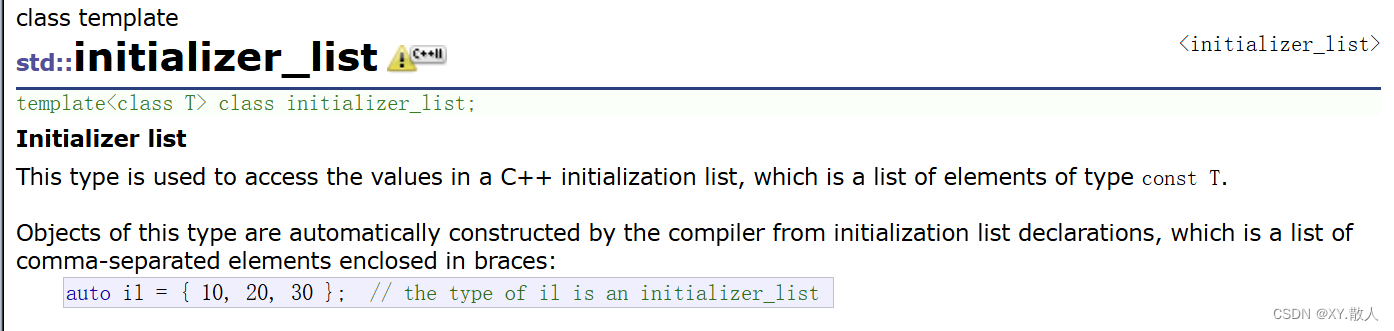

这是一个类,它的成员变量也就几个迭代器和size,但是这是c++11引进的,即c++11准许如下的初始化方式:
void Test_vector()
{
//有关initializer_list
int a = 1;
int b = { 1 };
int c{ 1 };
//上面写法均正确 但是不推荐后面两种
vector v1 = { 1,2,3,4,5,6 };//隐式类型转化
vector v2({ 1,2,3,4,5,6,7,8 });//直接构造
}
但是不推荐这种方式,代码可读性没那么高,但是我们看到这种初始化方式应该知道这是使用的initializer_list类型来初始化的,这里的初始化也是涉及到了隐式类型转换,先构造一个临时对象,再拷贝构造这个临时对象,那么编译器会优化为直接构造。
所以构造就是这样构造的:
vector(initializer_listil) { reserve(il.size()); for (auto& e : il) { push_back(e); } }
但是,这里会出问题了:
vector(initializer_listil) { reserve(il.size()); for (auto& e : il) { push_back(e); } } vector(size_t n, const vector & val = T()) { reserve(n); for (int i = 0;i < n;i++) { push_back(val); } } void Test() { vector v(10,1); vector v(10u,1); vector v(10,'a'); }
下面的两个构造就不会出问题,第二个的u是无符号的标志,即size_t,第一个会出问题,因为10和1默认的类型是int,那你说,调用上面的没问题吧?调用下面的,虽然第一个的参数类型是size_t,但是将就将就吧也可以,那你说,编译器调用哪个?
所以这里会报错,那么源代码里面解决的就很简单粗暴:
vector(int n, const vector& val = T()) { reserve(n); for (int i = 0;i < n;i++) { push_back(val); } }
类型转换一下~
8 赋值
这里的赋值我们可以直接采用现代写法,不用传统的先开空间,再进行数据拷贝,我们利用swap函数,可以达到很好的效果:
void swap(const vector& v) { std::swap(_start,v._start); std::swap(_finish,v._finish); std::swap(_end_of_storage,v._end_of_storage); }
这里需要注意到的是swap的调用需要用到域名访问限定符,不然编译器会调用离函数最近的函数,即它本身,而我们使用的是std库里面的交换函数,所以需要使用::。
有了交换,我们构造一个临时对象,再进行交换即可:
vector& operator=(vector v) { swap(v); return *this; }
我们提及到过连续赋值的条件是返回值应该是赋值过后的值,所以我们需要返回赋值之后的对象。
9 memcpy的问题
先看这样一段代码:
void Test5_vector()
{
vector v;
v.push_back("11111");
v.push_back("22222");
v.push_back("33333");
v.push_back("44444");
v.push_back("55555");
for (auto& e : v)
{
cout << e << " ";
}
cout << endl;
}
如果我们只存入4个或者及以下的数据是没有问题的,但是存入5个数据之后,就会存在访问出错的问题,这一切都是因为memcpy,也就是在扩容,尾插的时候会涉及到的问题。
我们了解memcpy的底层之后,就知道memcpy拷贝的方式是逐字节的拷贝,所以当_start指向的空间是自定义类型的时候,经过扩容之后,就会导致_start指向的空间被销毁,但是拷贝过来的指针依旧是指向那块被销毁的空间的,我们再次访问自然就会报错。
所以这里我们最好的方法就是进行赋值:
void reserve(size_t n)
{
if (capacity() < n)
{
size_t old_size = size();
T* tmp = new T[n];
//memcpy(tmp, _start, sizeof(T) * size());
for (int i = 0; i < old_size; i++)
{
tmp[i] = _start[i];
}
delete[] _start;
_start = tmp;
_finish = tmp + old_size;
_end_of_storage = tmp + n;
}
}
本质就是拷贝构造一个临时对象,就不会导致越界访问的问题。
10 迭代器失效
void Test6_vector()
{
vector v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.push_back(5);
v1.push_back(6);
v1.push_back(7);
v1.push_back(8);
vector::iterator it = v1.begin() + 3;
v1.insert(it, 40);
Print_vector(v1);
//it = v1.begin() + 3;
cout << *it << endl;
}
当我们多次插入之后,伴随着扩容的发生,所以it的位置会发生改变,it指向的是原来的空间位置,所以此时我们打印it的值的时候就会打印出来错误的值,所以如果发生了空间的改变导致迭代器失效,如果我们还要使用迭代器,我们就需要重置迭代器-》即那段注释。
void Test7_vector()
{
vector v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.push_back(4);
v1.push_back(5);
v1.push_back(4);
vector::iterator it = v1.begin();
while (it != v1.end())
{
if (*it % 2 == 0)
{
v1.erase(it);
it++;
}
}
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
且看这段删除偶数的代码,好像没有问题?有以下几种情况就会出错了,11252,1223。
因为删除之后会有移动数据的发生,比如1223,删除了第一个2,第二个2往前面移动,然后再pos位置的指针往后移动,就相当于it指针移动了两次,所以会错过,那么如果最后一个是偶数,即11252,就会完美错过end,那么循环条件就无法结束,就会死循环了。
解决方法也很简单,让it删除之后原地踏步就好了:
while (it != v1.end())
{
if (*it % 2 == 0)
{
it = v1.erase(it);//解决方法
}
else
{
++it;
}
}
这也是为什么erase的返回值是iterator的原因,整个代码都是前后呼应的。
感谢阅读!

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)





还没有评论,来说两句吧...