

1. 基本原理

CIF 作为Parafoemr的核心模块,用于预测字数和生成声学向量,从而实现了单轮非自回归解码。其中字数的预测主要通过encoder输出系数alpha的累计得分,满足通关阈值β=1.0即可产生一个token,其中alpha曲线在一定程度上呈现着vad效果,或者依次进行断句。
2. alpha-token 强制对齐
cif的时间戳对齐采用peak(通关方式)得到,这里我们直接尝试alpha-token对齐方式,将识别的token在编码器输出上进行对齐,其中对齐算法采用动态规划。具体参考main.py中的maxSumSubarrayWithGaps()。
以10s窗长进行音频切块,下面展示alpha-token 的对齐效果:
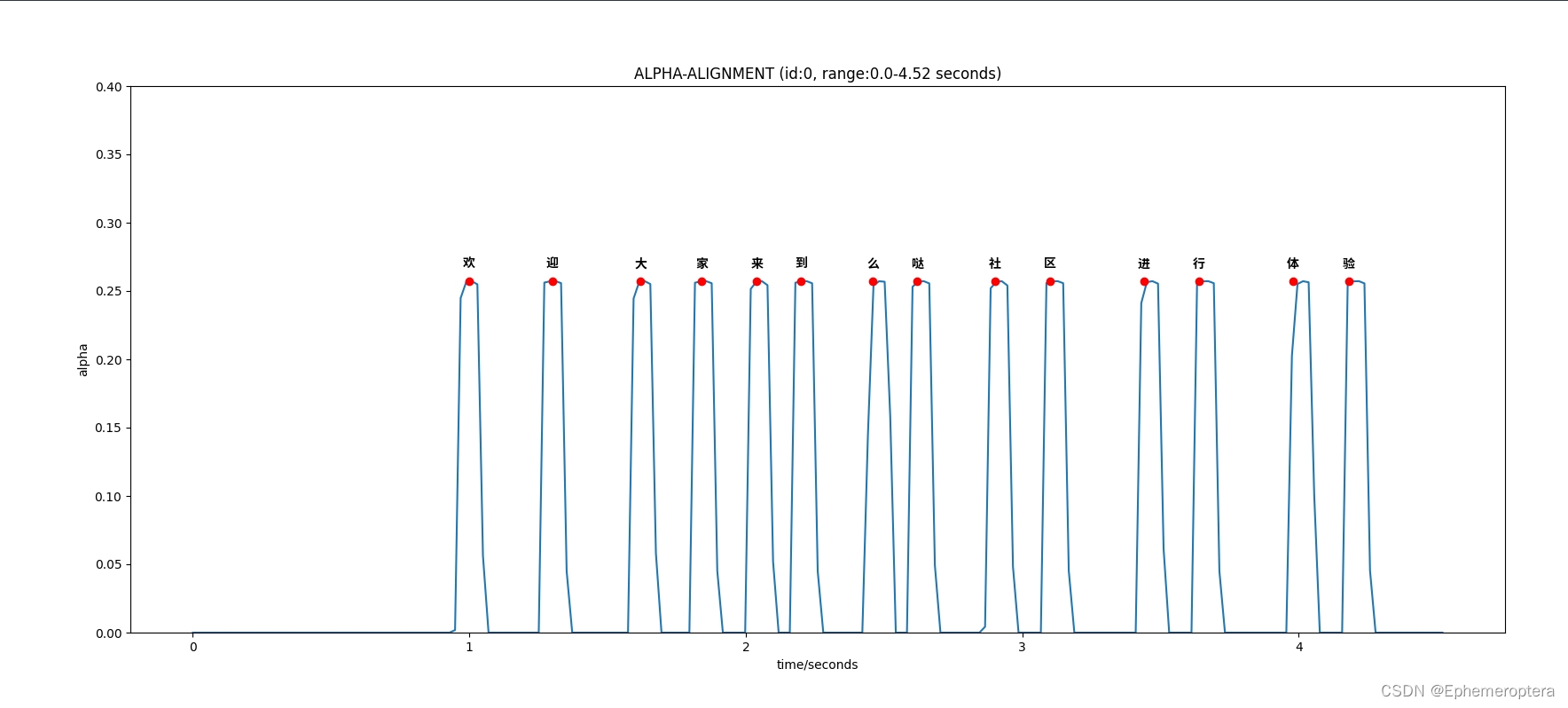
用户可以修改main.py 参数进行试验
3. code
github:https://github.com/coolEphemeroptera/funasr_alpha_token_alignment
import subprocess
from typing import List
import matplotlib.font_manager
import numpy as np
from funasr_onnx import SeacoParaformer
import os
import shutil
import matplotlib.pyplot as plt
import matplotlib
zhfont1 = matplotlib.font_manager.FontProperties(fname="./SourceHanSansSC-Bold.otf")
class SeacoParaformerPlus(SeacoParaformer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.SR = 16000
self.SECONDS_PER_FRAME = 0.02
self.UPSAMPLE_TIMES = 3
def decode(self,am_scores, valid_token_lens):
res = []
for am_score, valid_token_len in zip(am_scores, valid_token_lens):
token_ids = am_score.argmax(axis=-1)
token_chs = self.converter.ids2tokens(token_ids)
token_chs_valid = token_chs[:valid_token_len]
res.append(token_chs_valid)
return res
def __call__(self, waveform_list: list, hotwords: str, imgDir = './display',**kwargs) -> List:
# 加载热词编码
hotwords, hotwords_length = self.proc_hotword(hotwords)
[bias_embed] = self.eb_infer(hotwords, hotwords_length)
bias_embed = bias_embed.transpose(1, 0, 2)
_ind = np.arange(0, len(hotwords)).tolist()
bias_embed = bias_embed[_ind, hotwords_length.tolist()]
bias_embed = np.expand_dims(bias_embed, axis=0)
# onnx推理
waveform_nums = len(waveform_list)
content = []
id = 0
duration = 0
for beg_idx in range(0, waveform_nums, self.batch_size):
end_idx = min(waveform_nums, beg_idx + self.batch_size)
# 1.计算mel特征
feats, feats_len = self.extract_feat(waveform_list[beg_idx:end_idx])
# 2.热词编码同步复制
bias_embed_ = np.repeat(bias_embed, feats.shape[0], axis=0)
# 3. 解码
am_scores, valid_token_lens,us_alphas, us_peaks = self.bb_infer(feats, feats_len, bias_embed_)
# 4. 后处理
res = self.decode(am_scores, valid_token_lens)
for r,alpha,peak in zip(res,us_alphas,us_peaks):
content.append({'id':id,
'range':[duration,duration+len(waveform_list[id])],
'tokens':r,
'alpha':alpha,
'peak':peak})
duration += len(waveform_list[id])
id += 1
return content
def align_with_alpha(self,asr_res,img_path="tmp.png"):
id = asr_res['id']
tokens = asr_res['tokens'][:-1]
tokens_n = len(tokens)
stime,etime = round(asr_res['range'][0]/self.SR,2),round(asr_res['range'][1]/self.SR,2)
alpha = asr_res['alpha']
peak = asr_res['peak']
# alpha 对齐
max_val,max_path = maxSumSubarrayWithGaps(alpha,tokens_n,3)
AX,AY = [],[]
for ft,i,score in max_path:
AX.append(ft*self.SECONDS_PER_FRAME+stime)
AY.append(alpha[ft])
# 绘图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(20, 8))
plt.xlabel('time/seconds')
plt.ylabel('alpha')
plt.ylim([0,0.4])
plt.title("ALPHA-ALIGNMENT (id:%s, range:%s-%s seconds)"%(id,stime,etime))
x = np.linspace(stime,etime,len(alpha))
plt.plot(x,alpha)
plt.plot(AX, AY, 'o',color='red')
for i,ax in enumerate(AX):
ay = AY[i] + 0.01
token = tokens[i]
plt.text(ax, ay, token, fontsize=10, color='black',ha='center',fontproperties=zhfont1)
plt.savefig(img_path)
plt.close()
def rebuild_dir(dir):
def delete_directory(directory):
if os.path.exists(directory):shutil.rmtree(directory)
delete_directory(dir)
os.makedirs(dir)
print(f"Success to create {dir}")
def audio_f2i(data,width=16):
data = np.array(data)
return np.int16(data*(2**(width-1)))
def audio_i2f(data,width=16):
data = np.array(data)
return np.float32(data/(2**(width-1)))
def read_audio_file(url):
ffmpeg_cmd = [
'ffmpeg',
'-y',
'-i', url,
'-vn',
'-f', 's16le',
'-acodec', 'pcm_s16le',
'-ar', '16k',
'-ac', '1',
'-' ]
with subprocess.Popen(ffmpeg_cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=False) as proc:
stdout_data, stderr_data = proc.communicate()
if stderr_data:
audio_data = np.frombuffer(stdout_data,dtype=np.int16)
audio_data = audio_i2f(audio_data)
return audio_data
# 动态规划实现alpha-token强制对齐
def maxSumSubarrayWithGaps(NUMS,K,GAP):
N = len(NUMS)
# 初始化表单
dp = [[-float('inf') for j in range(K+1)] for _ in range(N)]
path = [[[] for j in range(K+1)] for _ in range(N)]
# 初始化边界
for i in range(N): # dp[:,0]
dp[i][0] = 0
path[i][0] = []
for j in range(K+1): # dp[0,:]
if j==0:
dp[0][j] = 0
elif j==1:
dp[0][j] = NUMS[0]
else:
dp[0][j] = -float('inf')
# dp填表
for i in range(1,N):
for j in range(1,K+1):
# 不满足G间隔
if (j-1)*GAP+1>i+1:
dp[i][j] = -float('inf')
path[i][j] = []
# 满足间隔
else:
for k in range(j-1,i-GAP+1):
# 更新最大值且区间内满足极差(停顿)要求
if dp[k][j-1]+NUMS[i]>dp[i][j] and max(NUMS[k:i+1])-min(NUMS[k+1:i])>0.02:
dp[i][j] = dp[k][j-1]+NUMS[i]
path[i][j] = [k,j-1,dp[k][j-1]]
# 回溯
max_i = np.argmax([dp[i][K] for i in range(N)])
max_val = dp[max_i][K]
max_path = []
i,j,v = max_i,K,max_val
max_path.append([i,j,v])
while 1:
if not path[i][j]:break
i,j,v = path[i][j]
if j>0:
max_path.append([i,j,v])
if j==1:break
max_path.reverse()
return max_val,max_path
if __name__ == '__main__':
SR = 16000
# 参数
url = "/home/nvidia/funasr_alpha_token_alignment/funasr_models/iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/example/asr_example.wav"
img_dir = 'alpha_align_plot'
chunk_seconds = 10
cache_dir='./funasr_models'
model_name = 'iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch'
model_quant = True
batch_size = 60
# 1. 加载模型
paraformer = SeacoParaformerPlus(model_dir=model_name,
quantize=model_quant,
batch_size=batch_size,
cache_dir=cache_dir)
# 2. 音频分块
audio_data = read_audio_file(url)
audio_length = len(audio_data)
chunk_size = chunk_seconds*SR
batch = []
for i in range(0,audio_length,chunk_size):
s,e = i,min(i+chunk_size,audio_length)
chunk = audio_data[s:e]
batch.append(chunk)
# 3. ASR
content = paraformer(batch,hotwords='')
# 4. alpha对齐
rebuild_dir(img_dir)
for asr_res in content:
id = asr_res['id']
text = asr_res['tokens']
print(id,text)
paraformer.align_with_alpha(asr_res,img_path=f"{img_dir}/{id}.png")
print("saved into:",f"{img_dir}/{id}.png")

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...