

Python网页爬虫爬取豆瓣Top250电影数据——Xpath数据解析
将使用Python网页爬虫爬取豆瓣电影Top250的电影数据,网页解析方法使用xpath。 获取数据后会将数据保存到CSV文件中。
一、分析网页,初步获取信息
1.1 查看原页面信息
首先打开豆瓣Top250电影页面,其网址是:https://movie.douban.com/top250。
可以发现,该页面展示的电影信息有中英文电影名、导演、主演、上映年份、国籍、电影类型、评分等。
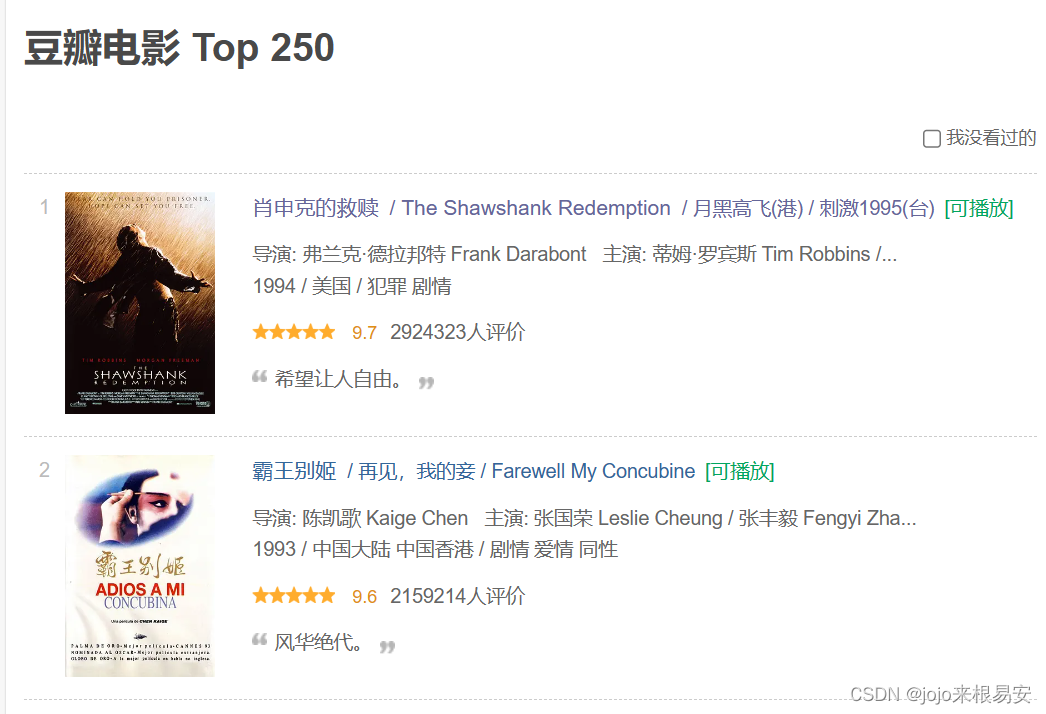
下滑到页面底部,发现第一页有25部电影的数据,并且可以点击页码数实现页面跳转翻页。
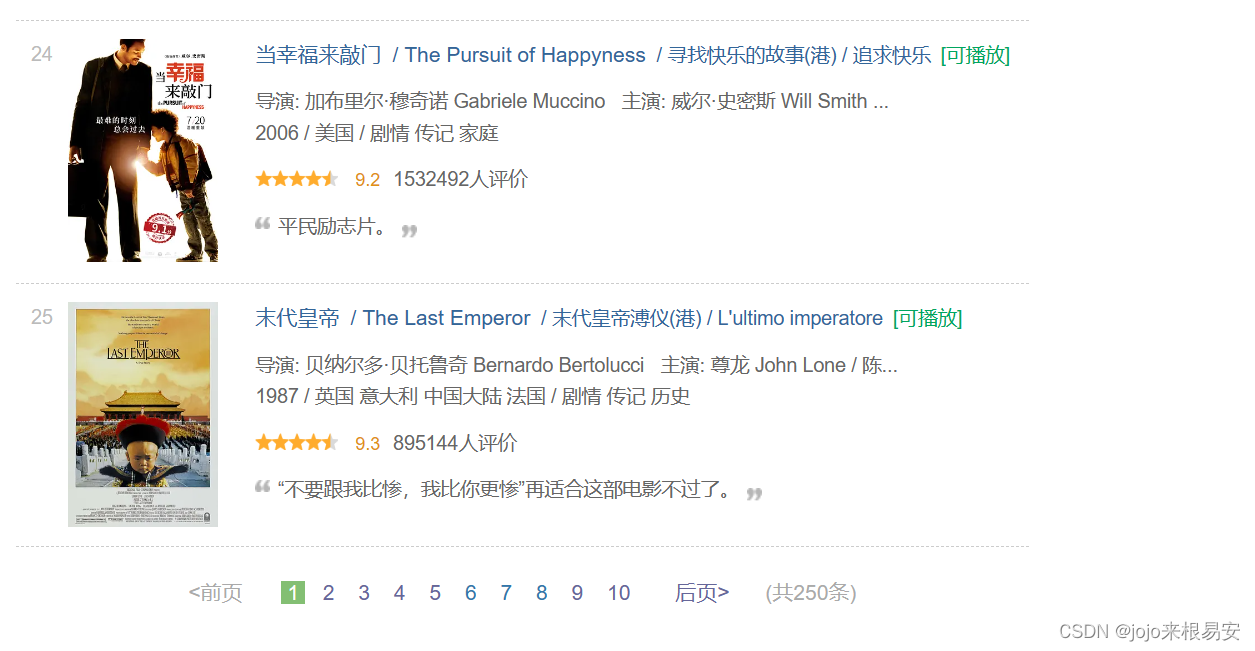
第一页的URL:https://movie.douban.com/top250
第二页的URL:https://movie.douban.com/top250?start=25&filter=
第三页的URL:https://movie.douban.com/top250?start=50&filter=
…
第十页的URL:https://movie.douban.com/top250?start=225&filter=
URL中问号?之后的是页面参数,即页面参数有start和filter,第二页start=25,第三页start=50,相差25,而每一页刚好有25部电影。所以可以猜测start是指从第几部电影开始,我们可以令start=0(因为25-0=25),得到URL:https://movie.douban.com/top250?start=0&filter=,访问该URL,刚好是第一页。所以这些URl就有共同的两个参数start和filter,通过改变参数可以定位到任意一部电影。
由于每次只能获取到25部电影,因此我们可以通过循环,改变start参数的值,每次循环都增加25,即步长为25,依次获取每一页的电影数据。第一页start=0,最后一页start=225。
1.2 查看网页源码和响应数据包
打开网页源码,在‘网络’下查看网页响应数据包,响应数据包中包含有返回的响应数据。所以需要寻找包含响应数据的响应数据包,在top250响应数据包的“响应”中可以看到其包含了我们想要获取的数据。
查看网页响应数据包的“标头”,网页的请求方法为GET方法,响应内容的类型是text/html,编码格式是utf-8。
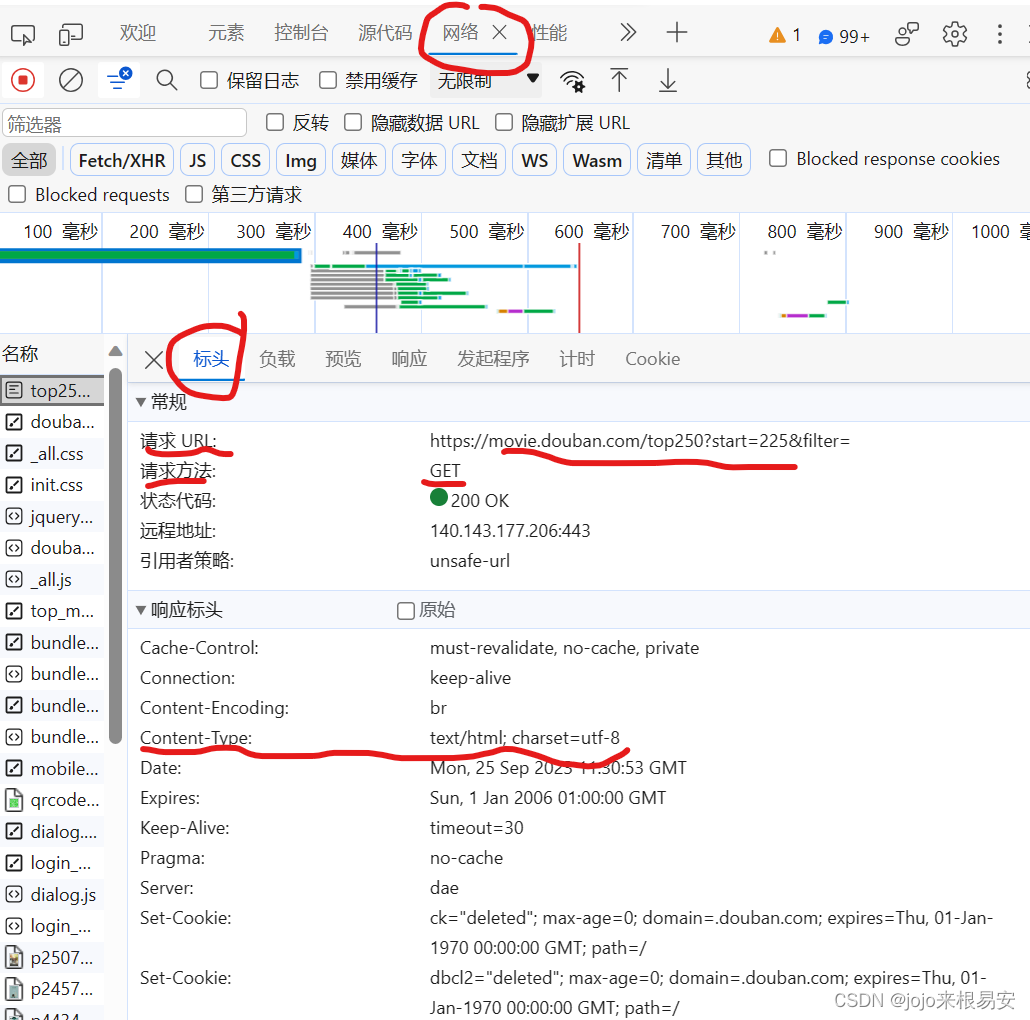
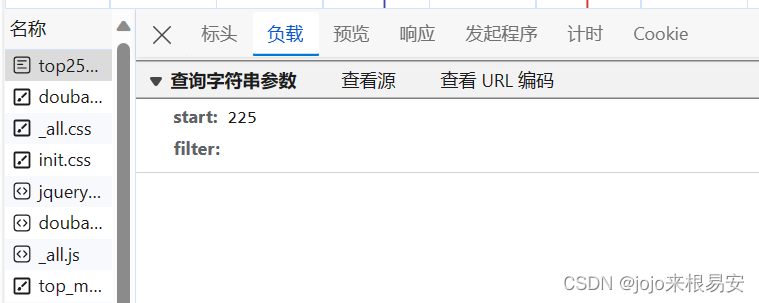
在响应数据包的“负载”中可以看到参数start和filter。它们俩都是URL中的参数,可以将它们封装到字典中作为GET请求方法的data参数。
二、进行网页爬虫
初步获取信息之后,我们可以对网页发起请求,获取响应,并用xpath解析网页响应数据。
2.1 准备get请求方法的参数
- 指定URL:
url = 'https://movie.douban.com/top250'
- UA伪装
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.41'}- 将URL中的参数封装到字典中
# 将URL中的参数封装到字典中 data = { 'start':'0', 'filter':'', }2.2 发起网页请求,获取响应
通过requests库的get方法对网页发起请求。
# 发起请求,获取网页响应 response = requests.get(url,headers=headers,data=data) print(response.status_code) # 查看响应状态码,200 print(response.encoding) # 查看编码格式 print(response.text) # 查看响应内容
输出的响应内容如下,其类型是txt/html,其中包含我们需要的数据。
2.3 通过xpath方法解析网页响应数据
2.3.1 定位到数据所在标签
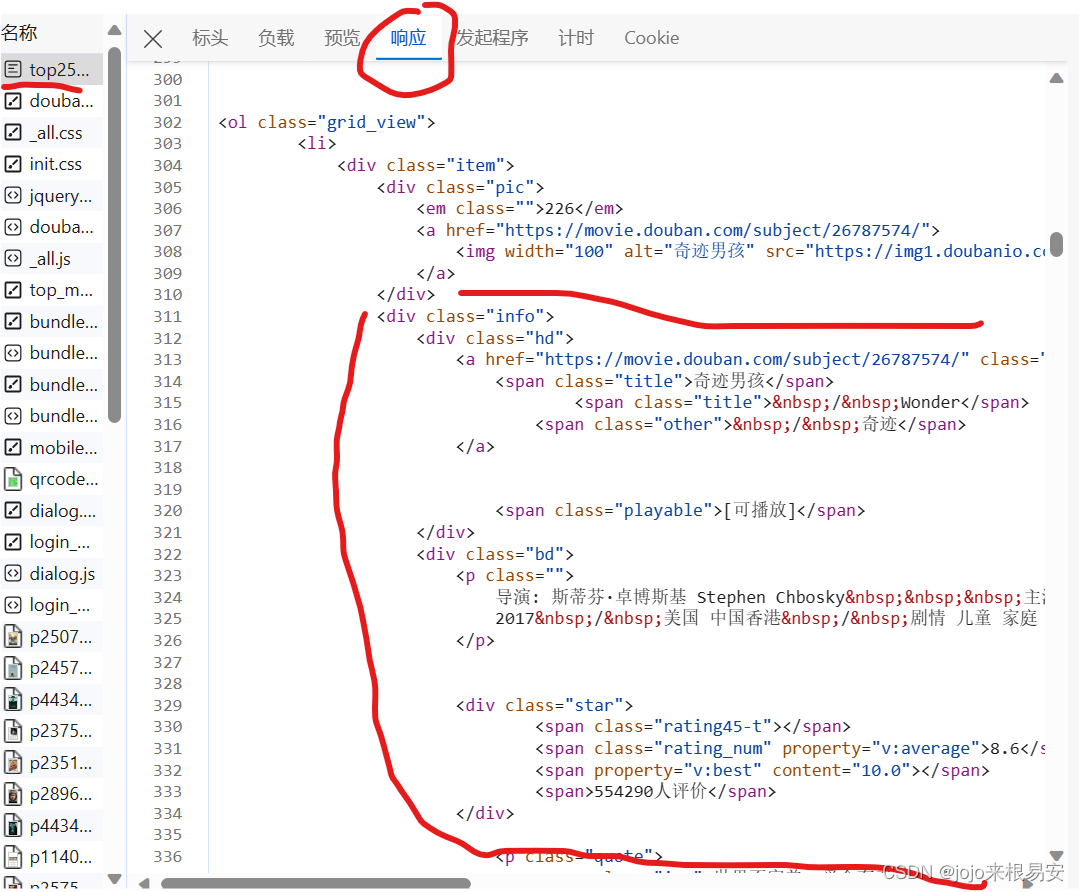
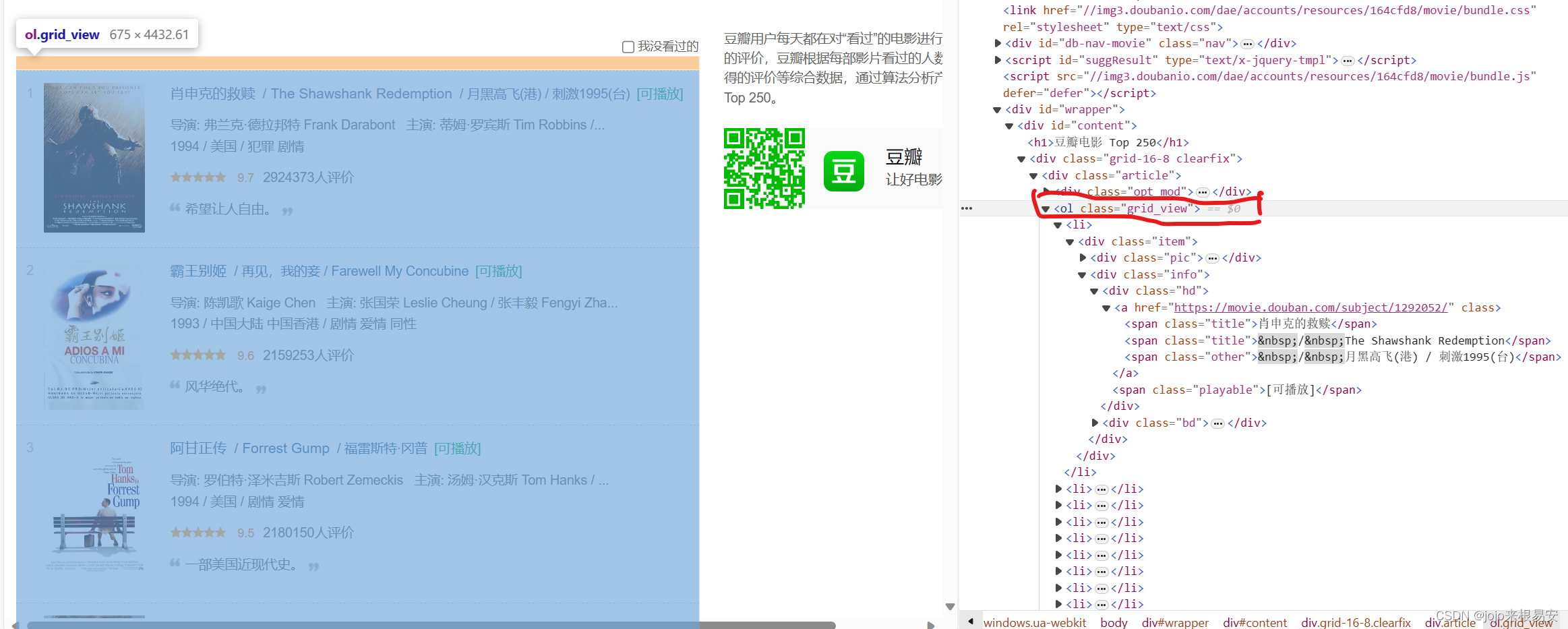
我们先打开网页源码,看看所需输出存放在哪些标签中。选中该页面所有的电影,定位到
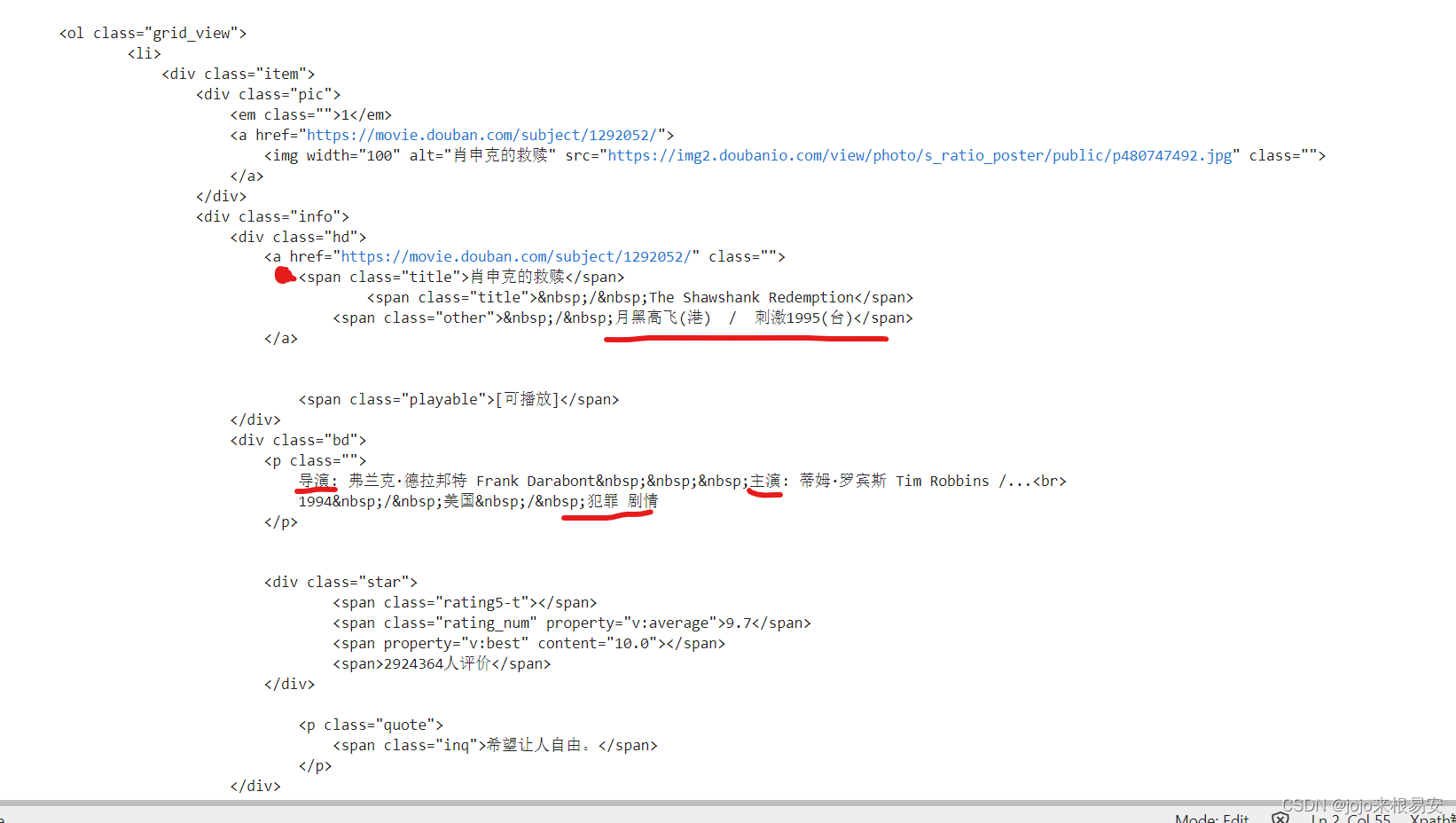
- 标签,说明该页面中所有的电影数据都包含在该标签中。该标签中的子标签li标签都对应着每一部电影的数据
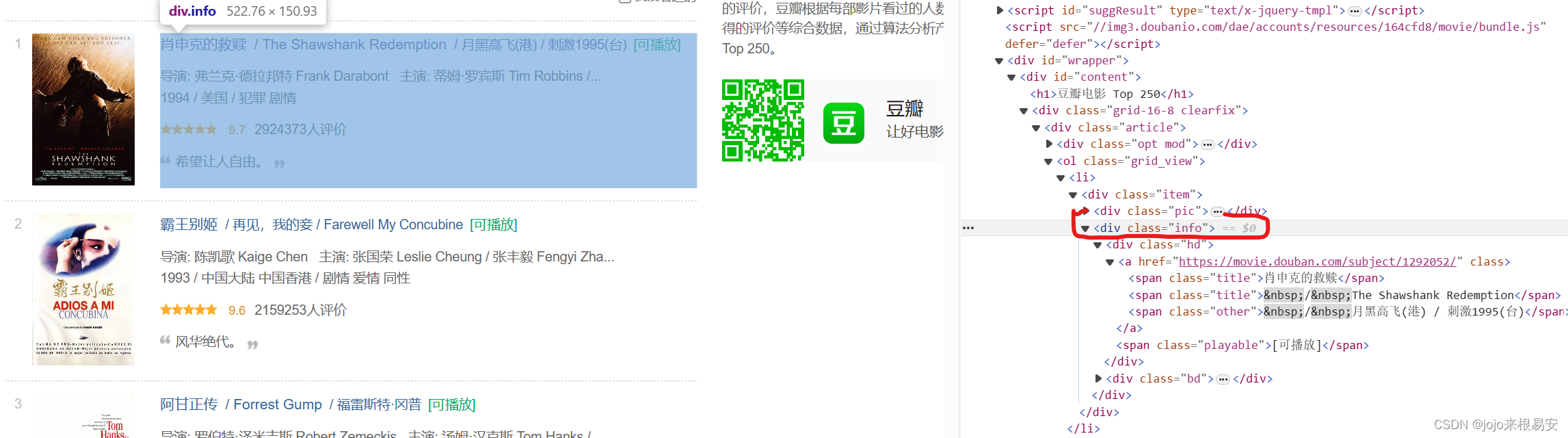
而每一部电影的所有信息都在li标签的下一级标签中的第二个div子标签中。标签下的第一个div子标签中的a标签中包含电影详情页的链接和电影中英文标题;标签下的第二个div子标签下则包含了其他全部信息。
2.3.2 通过xpath方法按层级查找数据
定位好之后,我们就可以用etree对象的xpath方法解析xpath表达式,查找到相应的数据。
定位到电影的标题所在标签,右键复制它的xpath:
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
中文标题就在a标签下的第1个span标签中span[1],然后我们通过/text()获取该标签中的文本信息。
# 获取中文电影标题 title_cn = data.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]/text()')而在a标签下的第二个span标签中包含的文本内容是电影的英文标题,所以我们只需要将span[1]改成span[2]就可以获取到电影的英文标题。
# 获取英文电影标题 title_en = data.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[2]/text()')
接下来获取电影详情页的链接,链接就在a标签中,是a标签的属性href的属性值,我们复制a标签的xpath。
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a
定位到a标签,要取其属性href的值需要在该路径后加上/@href 即可。
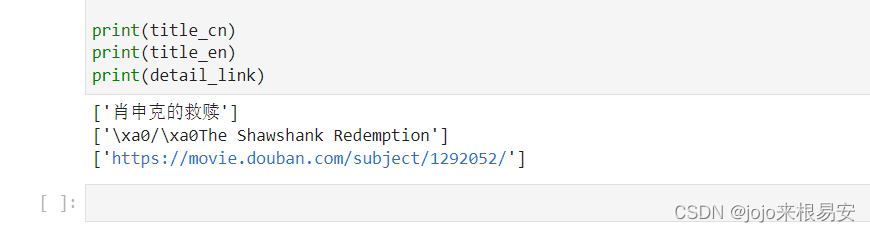
# 获取电影详情页链接 detail_link = data.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/@href')将这些信息打印看一下是否获取到正确信息:
我们已经获取到了第一部电影的中英文标题和详情页链接,它们都各自存放在一个列表中。
接下来我们可以用同样的方法获取电影的导演、主演、上映年份、国籍、类型和评分。
# 获取电影的导演和主演 people = data.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/p[1]/text()[1]') # 获取电影的年份、国籍和类型 info = data.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/p[1]/text()[2]') # 获取电影的评分 score = data.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[2]/text()')打印数据:

可以发现,我们确实获取到了电影的数据,但是有些数据在存放在一起的并且有乱码,下面再进行数据处理。以上就是我们获取一部电影数据的过程,接下来要获取一个页面的全部电影信息,然后通过循环翻页,获取不同页面的电影信息。
2.4 获取一个页面中所有电影的信息
我们通过xpath已经获取了页面中一部电影的数据,想要获得页面中所有电影的数据就要扩大查找范围,即减少xpath表达式中的标签数量。前面说过,每个li标签下都是一部电影的信息,一个页面有25部电影,那么就应该有25个li标签,我们可以通过li标签的下标定位获取到不同的li标签。如,下面这个路径中li[1]代表第一个li标签。我们可以先定位到所有包含电影信息的li标签,在通过循环遍历每一个li标签获取电影数据。
注意:xpath中标签的下标索引是从1开始,而不是从0开始。
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a
由于每一次取到的值存放到一个列表中,所以我们可以通过列表的下标索引取值。
# 取出所有电影的中文标题 titles_cn = data.xpath('//*[@id="content"]/div/div[1]/ol/li') # 创建空列表用于存放所有标题 title_cn = [] for each in titles_cn: title = each.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0] # 每次获取到的数据存在一个列表中,通过下标索引取列表的值 title_cn.append(title) print(title_cn)输出结果:
输出结果表明我们已经取到一个页面中的25部电影的中文标题。

然后,我们用同样的方法获取电影的其他信息。
# 取出所有电影的英文标题 titles_en = data.xpath('//*[@id="content"]/div/div[1]/ol/li') # 创建空列表用于存放所有标题 title_en = [] for each in titles_en: # 每次获取到的数据存在一个列表中,通过下标索引取列表的值 # 通过字符串的strip()方法去除字符串首尾的指定字符串 title = each.xpath('./div/div[2]/div[1]/a/span[2]/text()')[0].strip('\xa0/\xa0') title_en.append(title) print(title_en)获取该页面全部电影的英文标题:

# 获取电影详情页链接 detail_link = data.xpath('//*[@id="content"]/div/div[1]/ol/li') # 创建空列表用于存放所有标题 links = [] for each in detail_link : link = each.xpath('./div/div[2]/div[1]/a/@href')[0] links.append(link) print(links) # print(len(links))获取该页面全部电影的详情页链接:

2.5 通过循环获取所有页面的电影数据
需要嵌套循环,第一层循环通过改变data参数中的start的值来实现翻页,第二层循环则是遍历每个页面中的li标签,获取该页面每一部电影的数据。
第一层循环,第一页的start=0,第二页的start=25……第十页的start=225,因此for循环range中的start=0,stop=226,step=25,即range(0:226:25)。
第二层循环就是遍历li标签,与2.4中一样。
三、将数据存储到本地CSV文件
需要导入CSV模块
import csv
打开CSV文件,写入每一列的列名,注意,写入的每一行数据都要封装到一个列表中。
fp = open('./douban_top250.csv','w',encoding='utf-8') # 以写入模式打开文件 writer = csv.writer(fp) # 实例化对象 # 写入每一列的列名 # 注意,写入的每一行数据都要封装到一个列表中 writer.writerow(['电影中文名', '电影英文名','电影详情页链接','导演','演员','上映年份','国籍','类型','评分','评分人数'])通过循环获取数据,将每一部电影的数据作为一行写入文件中,写入的每一行数据都要封装到一个列表中。
# 将每一部电影的数据作为一行写入文件中 writer.writerow([title1,title2,link,dirt,ac,year,nation,ftype,score,num])
四、本次程序的全部代码
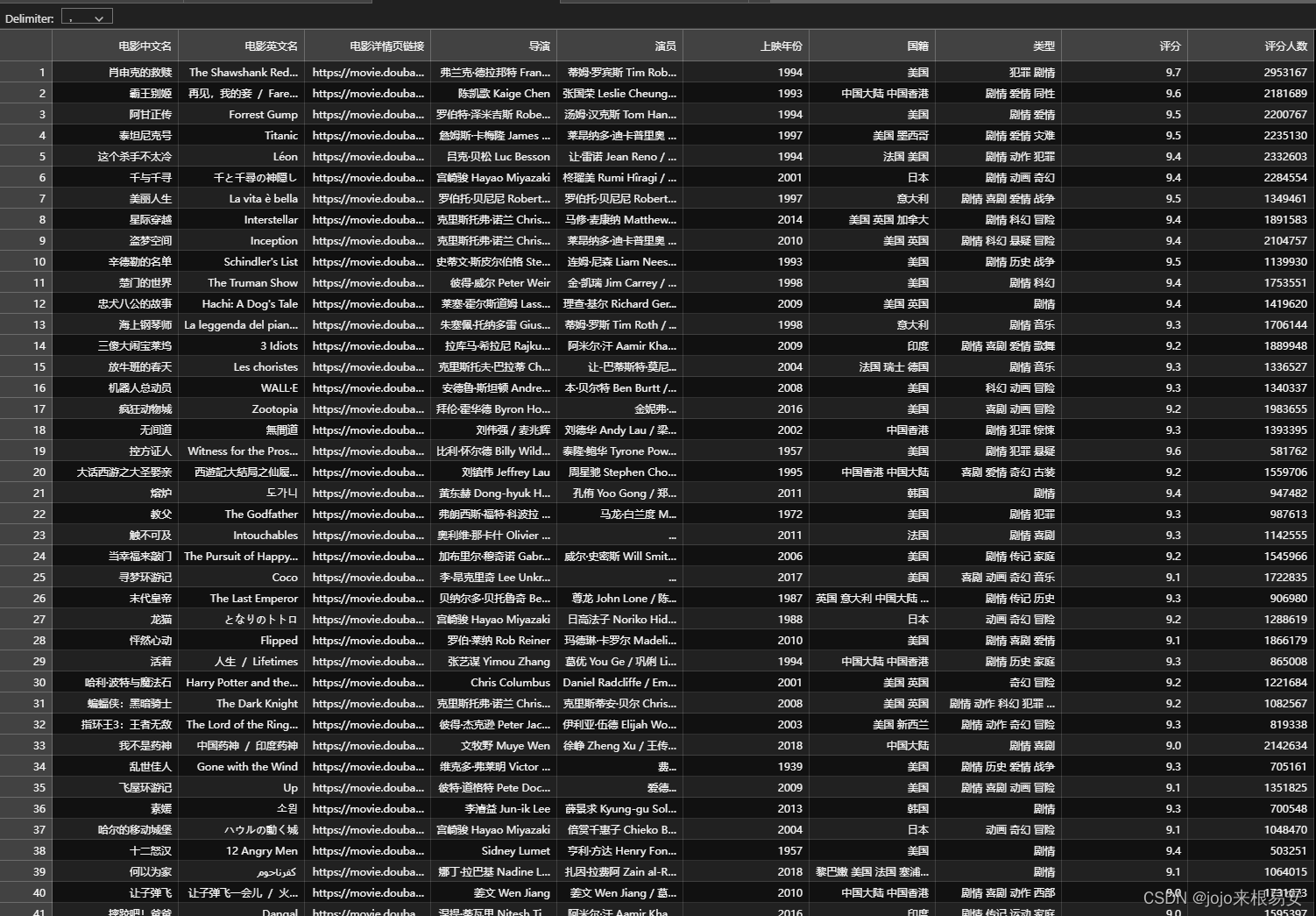
# 导包 import requests from lxml import etree # 用lxml解析器生成的对象中的xpath方法 from time import sleep import csv import numpy as np # 指定URL # url = 'https://movie.douban.com/top250' # 进行UA伪装 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.41'} # 定义空列表存放电影数据 tiltes_cn = [] # 中文标题 titles_en = [] # 英文标题 links = [] # 详情页链接 director = [] # 导演 actors = [] # 演员 years = [] # 上映年份 nations = [] # 国籍 types = [] # 类型 scores = [] # 评分 rating_nums = [] # 评分人数 fp = open('./douban_top250.csv','w',encoding='utf-8') writer = csv.writer(fp) writer.writerow(['电影中文名', '电影英文名','电影详情页链接','导演','演员','上映年份','国籍','类型','评分','评分人数']) for i in range(0,226,25): url = f'https://movie.douban.com/top250?start={i}&filter=' # 将URL中的参数封装到字典中 # data = { # 'start':i, # 设置start参数 # 'filter':'', # } # 发起请求,获取网页响应 response = requests.get(url,headers=headers # ,data=data ) sleep(1) # print(response.status_code) # print(response.encoding) # print(response.text) # 获取响应内容 html = response.text # 实例化一个etree对象 data = etree.HTML(html) # 所有电影信息都在li标签下,所以我们可以先定位到li标签,在通过循环获取每一个li标签中的信息 li_list = data.xpath('//*[@id="content"]/div/div[1]/ol/li') # 通过循环遍历每一页中的所有li标签,获取该页面所有电影的数据 for each in li_list: # 中文标题 title1 = each.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0] tiltes_cn.append(title1) # 英文标题 # 每次获取到的数据存在一个列表中,通过下标索引取列表的值 # 通过字符串的strip()方法去除字符串首尾的指定字符串 title2 = each.xpath('./div/div[2]/div[1]/a/span[2]/text()')[0].strip('\xa0/\xa0') titles_en.append(title2) # 链接 link = each.xpath('./div/div[2]/div[1]/a/@href')[0] links.append(link) # 导演、主演 info1 = each.xpath('./div/div[2]/div[2]/p[1]/text()[1]')[0].strip() # 通过strip方法去除字符串的前后空格 split_info1 = info1.split('\xa0\xa0\xa0') # 通过指定字符串分割字符串 dirt = split_info1[0].strip('导演: ') director.append(dirt) # 有些电影的主演为空,所以需要进行条件判断 # 如果导演和主演信息都有,则获取主演信息 if len(split_info1) == 2: ac = split_info1[1].strip('主演: ') actors.append(ac) # 如果没有主演信息,则将其信息设置为空 else: actors.append(np.nan) # 年份、国籍、类型 info2 = each.xpath('./div/div[2]/div[2]/p[1]/text()[2]')[0].strip() # 去除字符串首尾的空格 split_info2 = info2.split('\xa0/\xa0') # 通过字符串分割获取字符串中的年份、国籍和类型 # print(split_info) year = split_info2[0] nation = split_info2[1] ftype = split_info2[2] years.append(year) nations.append(nation) types.append(ftype) # 电影评分 score = each.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0] scores.append(score) # 获取电影打分人数 num = each.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0].strip('人评价') rating_nums.append(num) writer.writerow([title1,title2,link,dirt,ac,year,nation,ftype,score,num]) print(f'————————————第{int((i/25)+1)}页爬取完毕!——————————————') fp.close() # 写入完成后,关闭文件 print('——————————————————————————————————爬虫结束!!!!!————————————————————————————————————————————————')CSV文件中保存的数据:
总结
本次程序只爬取了豆瓣top250电影的展示页面的数据,没有爬取电影详情页的数据。在前面我们已经获取了每一部电影详情页的链接links,如果想要爬取电影的详情页,可以通过for循环遍历列表links,对每一个详情页发起请求,从而获取电影详情页的数据并进行解析。
- 将URL中的参数封装到字典中
- UA伪装

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...