

1.Java的安装
使用命令行工具安装(需要公网ip为60.205.163.33的实例提前启动nginx服务)
# 使用wget命令从指定的IP地址下载JDK安装包到/home/jdk目录 # -P 参数用于指定下载文件的保存路径,这里是 /home/jdk # 请注意,如果IP地址发生变化,需要相应地更新命令中的IP地址部分 wget http://60.205.163.33/download/jdk/jdk-8u261-linux-x64.tar.gz -P /home/jdk
1.3 解压jdk、配置、检验
step1:在云实例中创建一个存放jdk解压后的目录,
mkdir -p /opt/jdk1.8.0
step2:将 jre-8u261-linux-x64.tar.gz 解压到 /opt/jdk1.8.0 目录下
#将文件 jdk-8u261-linux-x64.tar.gz 从 /home/jdk/ 目录解压到 /opt/jdk1.8.0 目录 tar -zxvf /home/jdk/jdk-8u261-linux-x64.tar.gz -C /opt/jdk1.8.0
step3:勾选上显示/隐藏实例菜单栏:
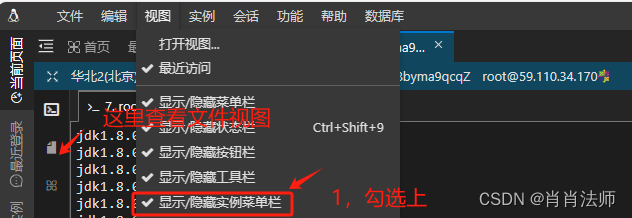
step4:
检验是否解压成功:左侧查看 /opt/jdk1.8.0 目录,是否和图片中的目录一致。
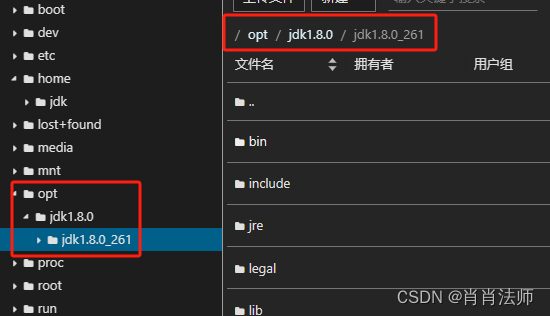
step5:修改环境变量
vim /etc/profile
在profile文件中添加以下内容:(第一行路径需根据自己的存放路径修改)
# 设置环境变量 JAVA_HOME 指向 JDK 的安装路径 # 这里假设 JDK 安装在 /opt/jdk1.8.0/jdk1.8.0_261 export JAVA_HOME=/opt/jdk1.8.0/jdk1.8.0_261 # 设置环境变量 JRE_HOME 指向 JAVA_HOME 下的 jre 目录 # 这通常是 JDK 的一部分,包含 Java 运行时环境 export JRE_HOME=$JAVA_HOME/jre # 设置 CLASSPATH 环境变量,它告诉 Java 程序在哪里查找类和库 # . 表示当前目录,$JAVA_HOME/lib 和 $JRE_HOME/lib 包含 Java 核心库 # 使用 : 分隔不同的路径 export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH # 更新 PATH 环境变量,添加 Java 的 bin 目录到系统路径中 # 这样可以在命令行中直接运行 java 和 javac 等命令,无需指定完整路径 # $JAVA_HOME/bin 和 $JRE_HOME/bin 包含 Java 的命令行工具 # $PATH 是系统原有的路径,确保其他程序仍然可以正常访问 export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
保存并退出。
step6:继续输入以下命令,使profile文件的修改生效:
source /etc/profile
step7:测试Java的安装是否成功?
java -version
输出结果如下图所示,表示Java安装成功

2.Hadoop的安装
2.1 修改主机名
(1)在安装之前先修改一下每个人的主机名,修改的名称要求如下:主机(hadoop-master-“姓名拼音首字母")、从机1(hadoop-slave1-“姓名拼音首字母")、从机2(hadoop-slave2-“姓名拼音首字母"),下面涉及到的主机名需都保持一致。
修改方式如下:
#新主机名按照要求命名 sudo echo 新主机名 > /etc/hostname #检验是否修改成功,若一下命令返回新主机名,则代表成功 cat /etc/hostname #若永久性修改,则需要使用以下命令重新启动,重新启动的过程需要等一会 reboot
再次判断,修改成功左侧提示命令行则显示新主机名
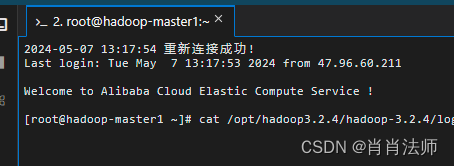
(2)配置主机名到 IP 地址的映射:配置文件中通常使用主机名而不是 IP 地址。为了确保集群中的节点可以通过主机名相互通信,您需要:在每个节点的 /etc/hosts 文件中配置主机名到 IP 地址的映射。具体方式如下:
vim /etc/hosts
在这个 /etc/hosts 文件中,您可以添加或修改主机名到 IP 地址(选择私网ip,更安全)的映射。(每个节点都需要修改)
# 127.0.0.1 是本地主机的回环地址,用于访问本地主机上的服务。 # 172.22.196.64、172.22.196.65 和 172.22.196.66 是集群中节点的 IP 地址,分别对应 hadoop-master、hadoop-slave1 和 hadoop-slave2 主机名。 127.0.0.1 localhost 172.22.196.64 hadoop-master 172.22.196.65 hadoop-slave1 172.22.196.66 hadoop-slave2
- 在云实例中/home目录下新建一个hadoop文件夹(命令方式和图标方式均可),存放hadoop安装包。命令方式如下:mkdir -p /home/hadoop
- 同Java的安装方式,将hadoop安装包从本地上传至云实例/home/hadoop目录中
wget http://60.205.163.33/download/hadoop/hadoop-3.2.4.tar.gz -P /home/hadoop
-
返回上一层目录,再创建一个存放hadoop解压后的目录
cd mkdir -p /opt/hadoop3.2.4
-
解压:
tar -zxvf /home/hadoop/hadoop-3.2.4.tar.gz -C /opt/hadoop3.2.4
-
配置hadoop环境
vim /etc/profile
-
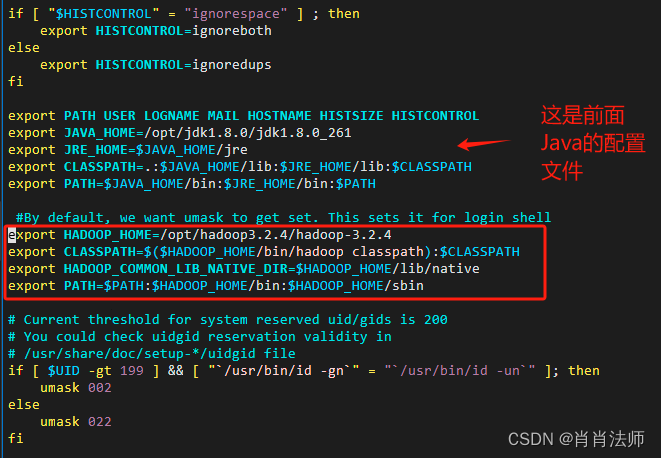
在profile文件中添加以下内容:(原理同java)
export HADOOP_HOME=/opt/hadoop3.2.4/hadoop-3.2.4 export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 添加后的效果如下图所示:
-
保存退出使profile文件生效
source /etc/profile
-
查看是否安装成功,命令及输出结果如下:
hadoop version

-
配置HDFS集群,执行以下命令,修改配置文件yarn-env.sh和hadoop-env.sh。(更方面)
echo "export JAVA_HOME=/opt/jdk1.8.0/jdk1.8.0_261" >> /opt/hadoop3.2.4/hadoop-3.2.4/etc/hadoop/yarn-env.sh echo "export JAVA_HOME=/opt/jdk1.8.0/jdk1.8.0_261" >> /opt/hadoop3.2.4/hadoop-3.2.4/etc/hadoop/hadoop-env.sh
-
将Hadoop守护进程的用户设置为root,具体修改方式如下:
cd /opt/hadoop3.2.4/hadoop-3.2.4/etc/hadoop vim hadoop-env.sh # 在hadoop-env.sh文件最下面添加如下内容 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
-
修改hadoop的配置信息,主要是在/opt/hadoop3.2.4/hadoop-3.2.4/etc/hadoop文件夹中的几个,具体修改内容如下(目录部分需要根据自己的安装位置进行修改):
#在 /opt/hadoop3.2.4/hadoop-3.2.4目录下新建一个tmp文件夹 cd /opt/hadoop3.2.4/hadoop-3.2.4/etc/hadoop mkdir tmp
vim workers
在workers文件中添加如下内容:(对照你的主机名修改)
hadoop-master hadoop-slave1 hadoop-slave2
同上,在core-site.xml文件中添加如下内容:(注意
不要重复添加),(此处hadoop-master需要修改为你们组的主节点主机名) hadoop.tmp.dir file:/opt/hadoop3.2.4/hadoop-3.2.4/tmp fs.defaultFS hdfs://hadoop-master:9000 同上,在hdfs-site.xml文件中添加如下内容:(注意
不要重复添加)(此处hadoop-master需要修改为你们组的主节点主机名) dfs.replication 2 dfs.namenode.secondary.http-address hadoop-master:50090 dfs.namenode.name.dir file:/opt/hadoop3.2.4/hadoop-3.2.4/tmp/dfs/name dfs.datanode.data.dir file:/opt/hadoop3.2.4/hadoop-3.2.4/tmp/dfs/data 同上,在mapred-site.xml文件中添加如下内容:(注意
不要重复添加)(此处hadoop-master需要修改为你们组的主节点主机名) mapreduce.framework.name yarn mapreduce.jobhistory.address hadoop-master:10020 mapreduce.jobhistory.webapp.address hadoop-master:19888 同上,在yarn-site.xml文件中添加如下内容:(注意
不要重复添加)(此处hadoop-master需要修改为你们组的主节点主机名) yarn.resourcemanager.hostname hadoop-master yarn.nodemanager.aux-services mapreduce_shuffle yarn.log-aggregation-enable true yarn.nodemanager.log-dirs ${yarn.log.dir}/userlogs - 其他两台也需要进行以上Java、Hadoop所有的安装配置工作。
3.Hadoop的ssh连接、测试与启动
-
【更新】建立同区域(例如:同杭州)不同账号下不同vpc(虚拟共有私网)私网ip的对等连接,具体方式参考:通过VPC对等连接方式,实现阿里云不同账号下的VPC内网网络互通。
-
在master主机上生成SSH公钥和私钥(其他两台从节点主机不用)
在终端中执行以下命令:
ssh-keygen -t rsa
这将在你的用户主目录下的.ssh文件夹(如~/.ssh)中创建id_rsa(私钥)和id_rsa.pub(公钥)两个文件。
-
将公钥复制到远程机器
使用ssh-copy-id命令将公钥添加到主机master和远程机器slave1和slave2(该命令需执行三遍)。这将添加你的公钥到远程主机的~/.ssh/authorized_keys文件中。
ssh-copy-id username@remote-host
请将username替换为你的远程主机上的用户名,将remote-host替换为远程主机的IP地址或主机名。
-
测试SSH连接
通过执行以下命令来测试你的SSH连接:
ssh username@remote-host
如果配置正确,你将能够在不需要密码的情况下登录到远程主机。
-
Hadoop的启动
4.网页形式的查看方式
-
HDFS集群的网页查看方式:
访问地址: 公网ip:9870(Hadoop安装版本不一致,访问端口也不一致)
能成功访问到的界面如下:
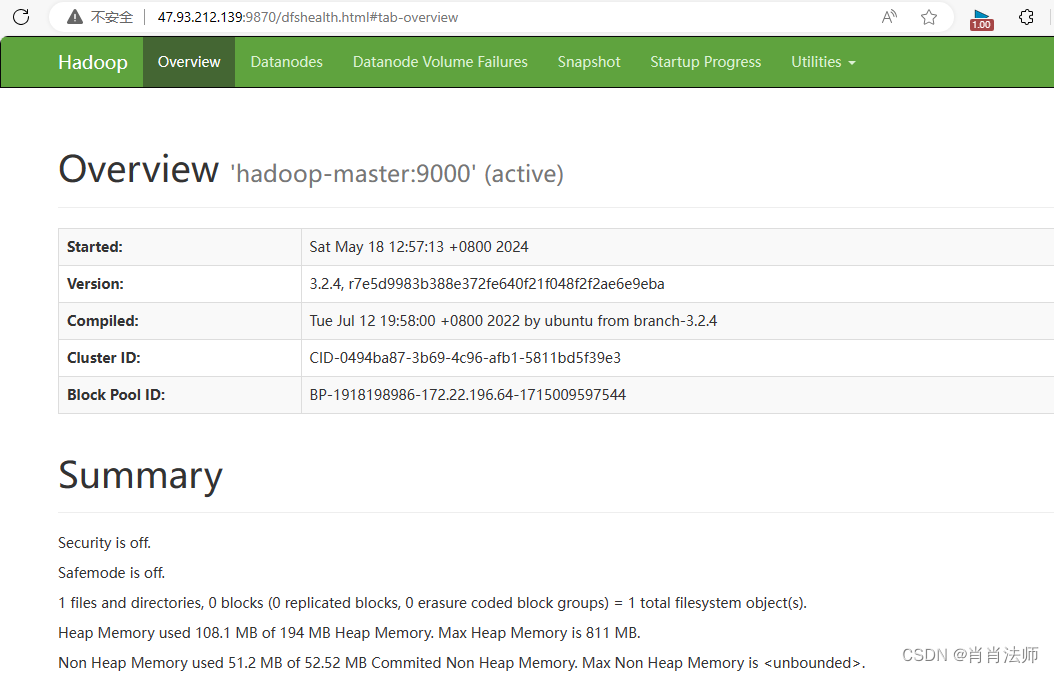
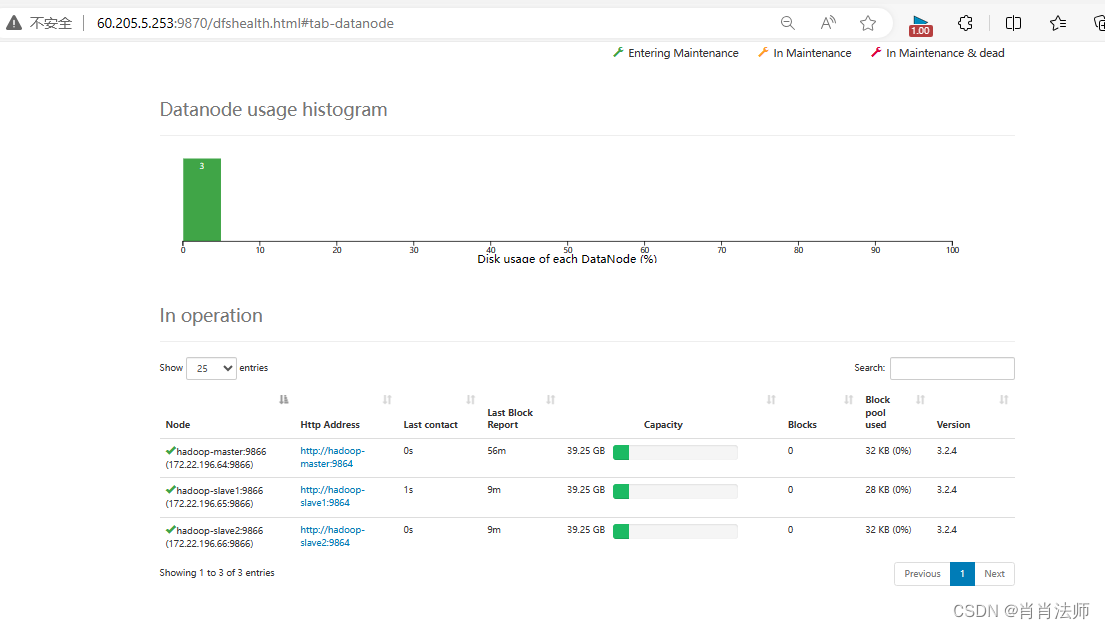
-
YARN网页查看方式:
访问地址: 公网ip:8088
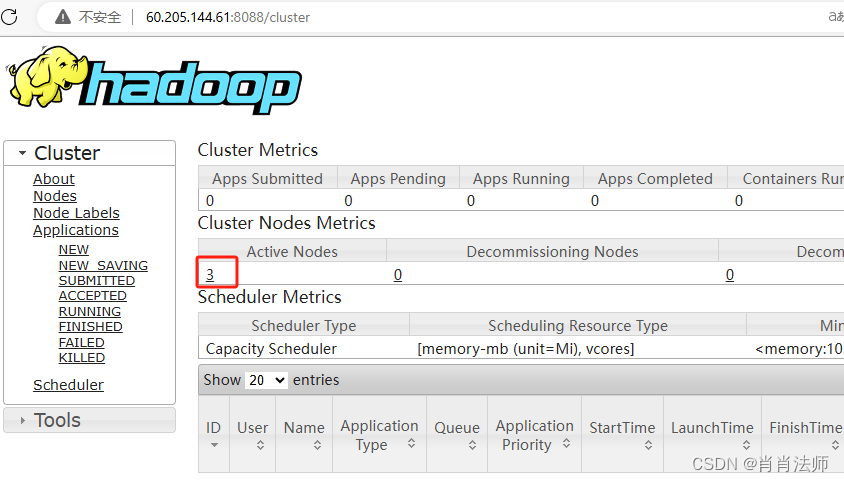
5.出现的问题及解决方式:
(1)安全组访问端口需提前添加,有9000,50090、10020等实验中涉及的端口,或者直接打开所有的端口(这种方式便于做实践,但不安全),如下图所示:

(2)访问页面没响应,需关闭防火墙。命令如下:
systemctl stop firewalld

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...