

目录
- 1. 拿到要抓取的数据
- 2. 封装item类
- 3. 修改一些常用的设置
- 4. 代码运行程序生成csv
- 小结
- 总结
欢迎关注 『scrapy爬虫』 专栏,持续更新中
欢迎关注 『scrapy爬虫』 专栏,持续更新中
1. 拿到要抓取的数据
仿照前面的百度,新建豆瓣的spider
scrapy genspider 爬虫文件名 爬虫的url scrapy genspider douban movie.douban.com
我们的目标网页是https://movie.douban.com/top250,分析网页结构,一个li代表一个电影,用选择器来定位元素,右键电影,审查元素,然后对着li右键复制Selector定位属性

在我们前面的每个li中,找到span,拿到class为title的span的text属性.
douban.py内容如下
import scrapy from scrapy import Selector class DoubanSpider(scrapy.Spider): name = "douban" allowed_domains = ["movie.douban.com"]# 限制或允许访问的域名列表 start_urls = ["https://movie.douban.com/top250"] # 起始url def parse(self, response): myselector=Selector(text=response.text) # 拿到了所有的li,也就是所有的电影,每一个li代表一个电影,list_items是由250个电影li组成的list list_items=myselector.css("#content > div > div.article > ol > li") for list_item in list_items: # 电影标题的 Selector # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1) list_item.css("span.title::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 # 电影评分 # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > div > span.rating_num list_item.css("span.rating_num::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 # 电影影评 # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > p.quote > span list_item.css("span.inq::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
2. 封装item类
前面拿到了数据,但是太零散了,封装类方便后续操作.
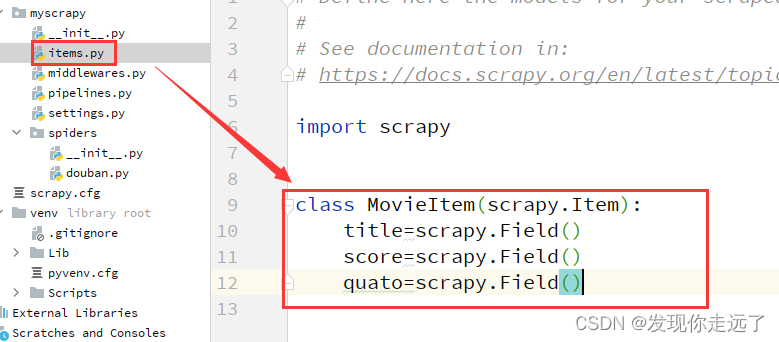
item.py内容如下
import scrapy class MovieItem(scrapy.Item): title=scrapy.Field() score=scrapy.Field() quato=scrapy.Field()同时,douban.py内容相互对应
import scrapy from scrapy import Selector from myscrapy.items import MovieItem class DoubanSpider(scrapy.Spider): name = "douban" allowed_domains = ["movie.douban.com"]# 限制或允许访问的域名列表 start_urls = ["https://movie.douban.com/top250"] # 起始url def parse(self, response): myselector=Selector(text=response.text) # 拿到了所有的li,也就是所有的电影,每一个li代表一个电影,list_items是由250个电影li组成的list list_items=myselector.css("#content > div > div.article > ol > li") for list_item in list_items: movie_item=MovieItem()#新建类的对象 # 电影标题的 Selector # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1) movie_item['title']=list_item.css("span.title::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 # 电影评分 # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > div > span.rating_num movie_item['score']=list_item.css("span.rating_num::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 # # 电影影评 # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > p.quote > span movie_item['quato']=list_item.css("span.inq::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 yield movie_item#把整理得到的数据给管道
3. 修改一些常用的设置
包括浏览器头,并发数量,下载延迟,日志配置.
# USER_AGENT = "myscrapy (+http://www.yourdomain.com)"#告诉网站 我是爬虫,马上被枪毙~ USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36" #我是好人,浏览器头 # 是否遵守爬虫协议 ROBOTSTXT_OBEY = True #设置 Scrapy 引擎同时处理的并发请求数量。 少设置一点不要给网站太大压力! (default: 16) CONCURRENT_REQUESTS = 8 # 随机下载延迟 RANDOMIZE_DOWNLOAD_DELAY = True #随机延时 3秒 DOWNLOAD_DELAY = 3 #配置日志 LOG_ENABLED = False #开启日志 LOG_LEVEL = 'DEBUG'#设置日志级别。例如,要将日志级别设置为输出所有信息,可以这样配置:通过将日志级别设置为 DEBUG,你可以获取爬虫程序执行过程中的所有详细信息,包括请求、响应、数据处理等各个环节的日志输出。当然,如果你只想获取部分信息,比如只关注警告和错误信息,也可以将日志级别设置为 WARNING 或 ERROR。在运行爬虫时,Scrapy 默认会将日志输出到控制台。如果你希望将日志保存到文件中,还可以设置 LOG_FILE 配置选项,例如: LOG_FILE = 'scrapy.log'#设置日志文件名字 上述配置会将日志输出到名为 scrapy.log 的文件中。 FEED_EXPORT_ENCODING = "utf-8"#通用编码 FEED_EXPORT_ENCODING = "gbk"#中文编码 FEED_OVERWRITE = True # 是否覆盖上次的数据,如果为false每次都是默认的在上次的csv文件后继续写入新的数据
查看日志文件
4. 代码运行程序生成csv
在pycharm的中断teiminal中,爬取数据并存放到csv
scrapy crawl douban -o douban.csv csv可以改成下面任意参数 ('json', 'jsonlines', 'jsonl', 'jl', 'csv', 'xml', 'marshal', 'pickle') 比如说 scrapy crawl douban -o douban.json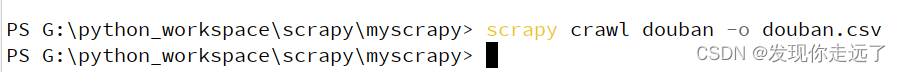
生成成功

pycharm中打开csv看到的是中文,因为默认utf8,如果你在外面用excel打开是乱码,因为你中文系统,默认用的gbk编码.
FEED_EXPORT_ENCODING = "gbk"#中文编码,可以让你外面excel打开时也是正常的
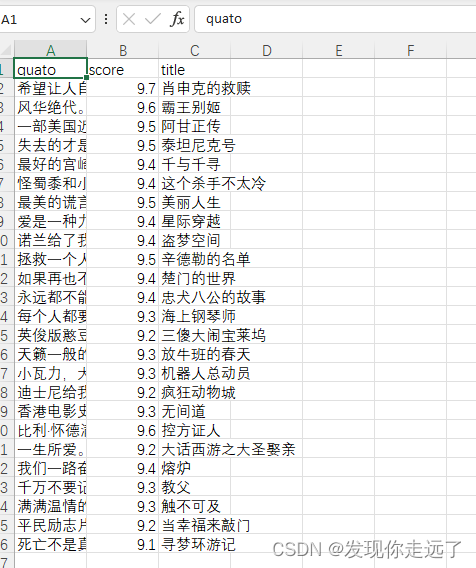
小结
scrapy最大优势就是你只需要负责专注数据爬取,剩下的其他下载多线程并发,数据持久化保存都交给了已经造好的轮子框架,减少工作量.
总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2024 mzh
Crated:2024-3-1
欢迎关注 『scrapy爬虫』 专栏,持续更新中
欢迎关注 『scrapy爬虫』 专栏,持续更新中
『未完待续』

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)





还没有评论,来说两句吧...