

环境准备
方式1:基于Standalone Flink集群的SQL Client
启动Flink集群
[hadoop@node2 ~]$ start-cluster.sh [hadoop@node2 ~]$ sql-client.sh ... 省略若干日志输出 ... Flink SQL>
方式2:基于Yarn Session Flink集群的SQL Client
启动hadoop集群
[hadoop@node2 ~]$ myhadoop.sh start
使用Yarn Session启动Flink集群
[hadoop@node2 ~]$ yarn-session.sh -d
启动一个基于yarn-session的sql-client
[hadoop@node2 ~]$ sql-client.sh embedded -s yarn-session ... 省略若干日志输出 ... Flink SQL>
看到“Flink SQL>”提示符,说明成功开启了Flink的SQL客户端,此时就可以进行SQL相关操作了。
注意:以上选择其中一种方式进行后续操作。
数据库操作
Flink SQL> show databases; +------------------+ | database name | +------------------+ | default_database | +------------------+ 1 row in set Flink SQL> create database mydatabase; [INFO] Execute statement succeed. Flink SQL> show databases; +------------------+ | database name | +------------------+ | default_database | | mydatabase | +------------------+ 2 rows in set Flink SQL> show current database; +-----------------------+ | current database name | +-----------------------+ | default_database | +-----------------------+ 1 row in set 切换当前数据库 Flink SQL> use mydatabase; [INFO] Execute statement succeed. Flink SQL> show current database; +-----------------------+ | current database name | +-----------------------+ | mydatabase | +-----------------------+ 1 row in set Flink SQL> quit; ... ... ... [hadoop@node2 ~]$
表DDL操作
创建表
CREATE TABLE方式
创建test表
CREATE TABLE test(
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'print'
);
LIKE方式
基于test表创建test1,并添加value字段
CREATE TABLE test1 (
`value` STRING
)
LIKE test;
查看表
show tables;
查看test表结构
desc test;
查看test1表结构
desc test1;
操作过程
Flink SQL> CREATE TABLE test( > id INT, > ts BIGINT, > vc INT > ) WITH ( > 'connector' = 'print' > ); [INFO] Execute statement succeed. Flink SQL> CREATE TABLE test1 ( > `value` STRING > ) > LIKE test; [INFO] Execute statement succeed. Flink SQL> show tables; +------------+ | table name | +------------+ | test | | test1 | +------------+ 2 rows in set Flink SQL> desc test; +------+--------+------+-----+--------+-----------+ | name | type | null | key | extras | watermark | +------+--------+------+-----+--------+-----------+ | id | INT | TRUE | | | | | ts | BIGINT | TRUE | | | | | vc | INT | TRUE | | | | +------+--------+------+-----+--------+-----------+ 3 rows in set Flink SQL> desc test1; +-------+--------+------+-----+--------+-----------+ | name | type | null | key | extras | watermark | +-------+--------+------+-----+--------+-----------+ | id | INT | TRUE | | | | | ts | BIGINT | TRUE | | | | | vc | INT | TRUE | | | | | value | STRING | TRUE | | | | +-------+--------+------+-----+--------+-----------+ 4 rows in set
CTAS方式
CTAS:CREATE TABLE AS SELECT
create table test2 as select id, ts from test;
但这种方式不支持是print的连接器。因为print只能当作sink,不能当作source。
Flink SQL> create table test2 as select id, ts from test; [ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.ValidationException: Connector 'print' can only be used as a sink. It cannot be used as a source.
修改表
修改表名
alter table test1 rename to test11;
操作过程
Flink SQL> alter table test1 rename to test11; [INFO] Execute statement succeed. Flink SQL> show tables; +------------+ | table name | +------------+ | test | | test11 | +------------+ 2 rows in set
添加表字段
创建test2表
CREATE TABLE test2(
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'print'
);
查看test2表结构
desc test2;
添加表字段,并放在第一个字段
ALTER TABLE test2 ADD `status` INT COMMENT 'status descriptor' FIRST;
查看test2表结构
desc test2;
操作过程
Flink SQL> CREATE TABLE test2( > id INT, > ts BIGINT, > vc INT > ) WITH ( > 'connector' = 'print' > ); [INFO] Execute statement succeed. Flink SQL> desc test2; +------+--------+------+-----+--------+-----------+ | name | type | null | key | extras | watermark | +------+--------+------+-----+--------+-----------+ | id | INT | TRUE | | | | | ts | BIGINT | TRUE | | | | | vc | INT | TRUE | | | | +------+--------+------+-----+--------+-----------+ 3 rows in set Flink SQL> ALTER TABLE test2 ADD `status` INT COMMENT 'status descriptor' FIRST; [INFO] Execute statement succeed. Flink SQL> desc test2; +--------+--------+------+-----+--------+-----------+-------------------+ | name | type | null | key | extras | watermark | comment | +--------+--------+------+-----+--------+-----------+-------------------+ | status | INT | TRUE | | | | status descriptor | | id | INT | TRUE | | | | | | ts | BIGINT | TRUE | | | | | | vc | INT | TRUE | | | | | +--------+--------+------+-----+--------+-----------+-------------------+ 4 rows in set
修改表字段
修改表字段
ALTER TABLE test2 MODIFY (vc DOUBLE NOT NULL, status STRING COMMENT 'status desc');
查看表结构
desc test2;
操作过程
Flink SQL> ALTER TABLE test2 MODIFY (vc DOUBLE NOT NULL, status STRING COMMENT 'status desc'); [INFO] Execute statement succeed. Flink SQL> desc test2; +--------+--------+-------+-----+--------+-----------+-------------+ | name | type | null | key | extras | watermark | comment | +--------+--------+-------+-----+--------+-----------+-------------+ | status | STRING | TRUE | | | | status desc | | id | INT | TRUE | | | | | | ts | BIGINT | TRUE | | | | | | vc | DOUBLE | FALSE | | | | | +--------+--------+-------+-----+--------+-----------+-------------+ 4 rows in set
删除表字段
删除表字段
ALTER TABLE test2 DROP (ts, status);
查看表结构
desc test2;
操作过程
Flink SQL> ALTER TABLE test2 DROP (ts, status); [INFO] Execute statement succeed. Flink SQL> desc test2; +------+--------+-------+-----+--------+-----------+ | name | type | null | key | extras | watermark | +------+--------+-------+-----+--------+-----------+ | id | INT | TRUE | | | | | vc | DOUBLE | FALSE | | | | +------+--------+-------+-----+--------+-----------+ 2 rows in set
删除表
语法
DROP [TEMPORARY] TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
案例
drop table if exists test2;
操作过程
Flink SQL> drop table if exists test2; [INFO] Execute statement succeed.
表DML查询操作
Select
select
SELECT测试及结果显示模式设置
SELECT 'Hello World', 'It''s me';
注意:SELECT后面的字符串必须用单引号括起来,如果字符串里面包含有单引号,则再多用一个单引号(如:'It's me'写成'It''s me')。
结果如下:
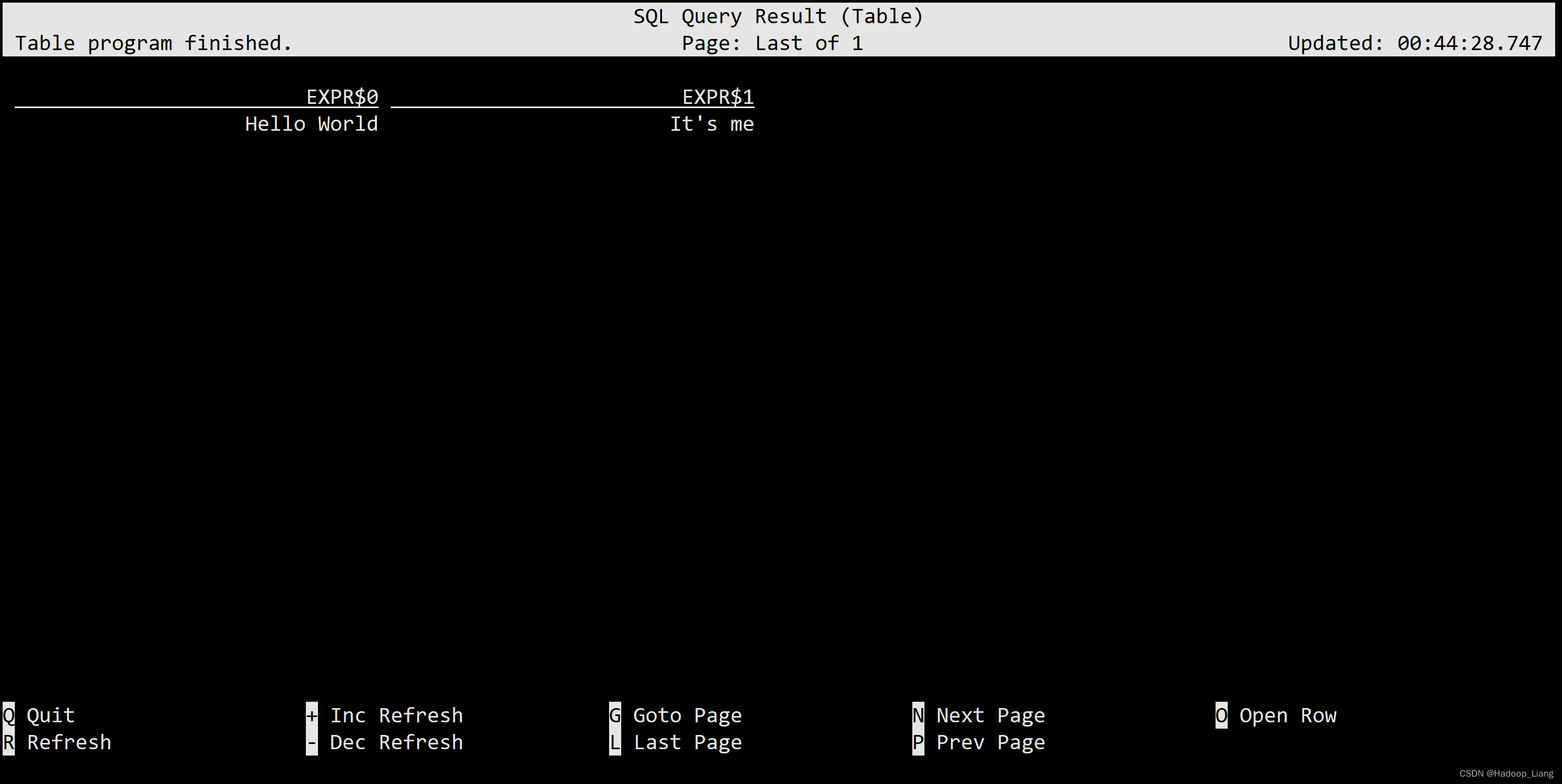
按q键返回命令行。
设置结果显示模式
可以看到,结果显示模式默认table,还可以设置为tableau、changelog。
- 结果显示模式设置为tableau
SET sql-client.execution.result-mode=tableau;
操作过程
Flink SQL> SET sql-client.execution.result-mode=tableau; [INFO] Execute statement succeed. Flink SQL> SELECT 'Hello World', 'It''s me'; ... 省略若干日志输出 ... +----+--------------------------------+--------------------------------+ | op | EXPR$0 | EXPR$1 | +----+--------------------------------+--------------------------------+ | +I | Hello World | It's me | +----+--------------------------------+--------------------------------+ Received a total of 1 row
效果如下

- 显示模式设置为changelog
SET sql-client.execution.result-mode=changelog;
操作过程
Flink SQL> SET sql-client.execution.result-mode=changelog; [INFO] Execute statement succeed. Flink SQL> SELECT 'Hello World', 'It''s me'; ... 省略若干日志输出 ...
显示结果如下:
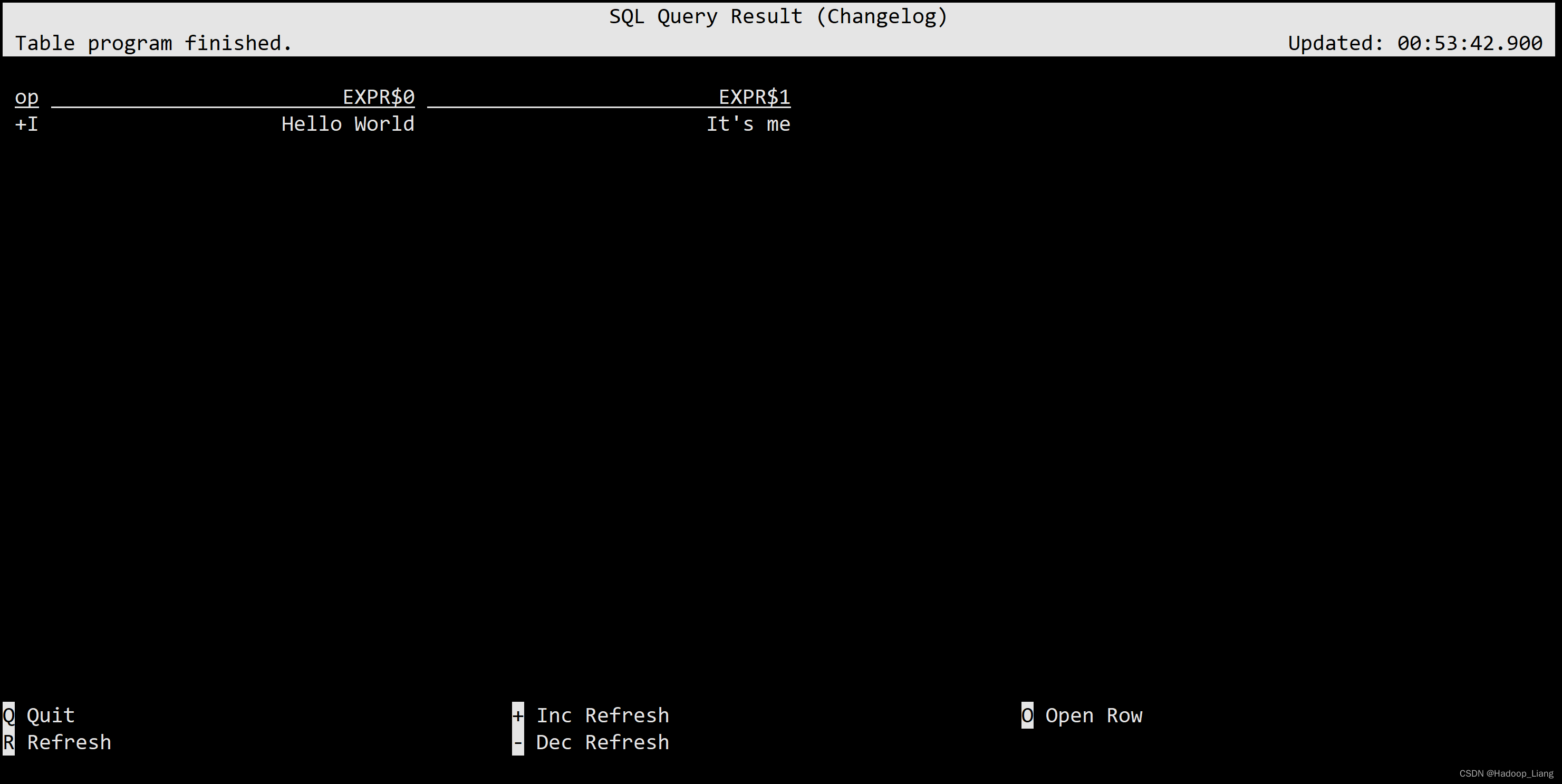
根据个人喜好,设置其中一种结果显示模式。
Source表
通过数据生成器创建source表
CREATE TABLE source ( id INT, ts BIGINT, vc INT ) WITH ( 'connector' = 'datagen', 'rows-per-second'='1', 'fields.id.kind'='random', 'fields.id.min'='1', 'fields.id.max'='10', 'fields.ts.kind'='sequence', 'fields.ts.start'='1', 'fields.ts.end'='1000000', 'fields.vc.kind'='random', 'fields.vc.min'='1', 'fields.vc.max'='100' );查询source表数据
select * from source;
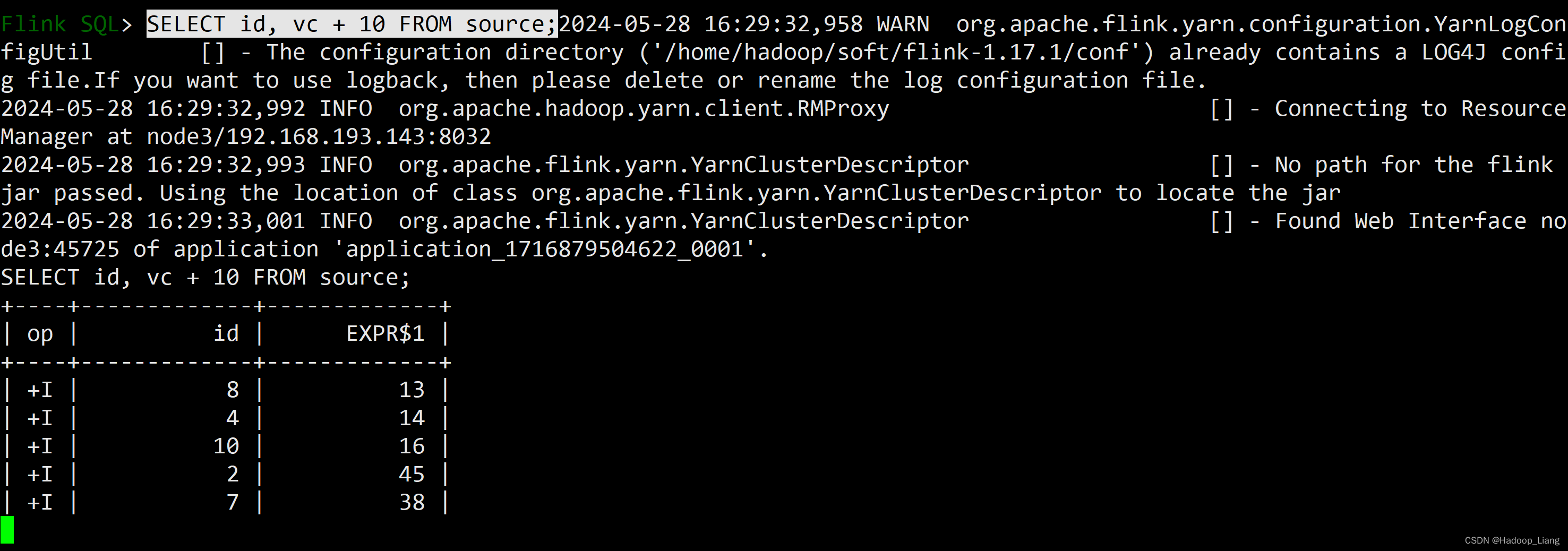
查询结果

按住ctrl + c 结束查询。
SELECT id, vc + 10 FROM source;
执行效果如下
Sink表
创建sink表
CREATE TABLE sink ( id INT, ts BIGINT, vc INT ) WITH ( 'connector' = 'print' );查询source表数据插入sink表
INSERT INTO sink select * from source;
直接查询sink表数据,报错如下:
Flink SQL> select * from sink; [ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.ValidationException: Connector 'print' can only be used as a sink. It cannot be used as a source.
正确查询方式,通过8088进入Application Master进入Web UI,看到一个Running Job
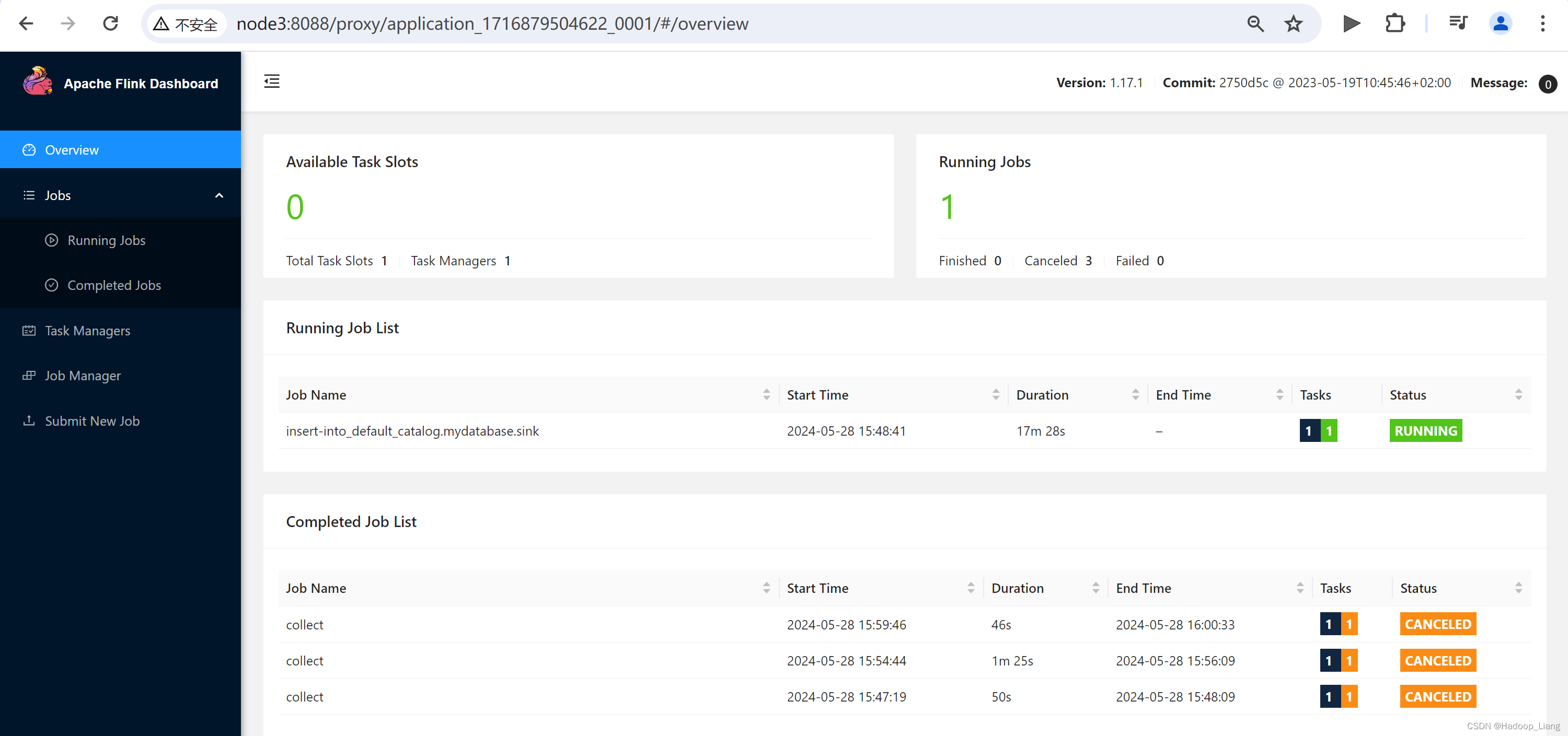
通过这个Runnig Job的Task Manager查看结果
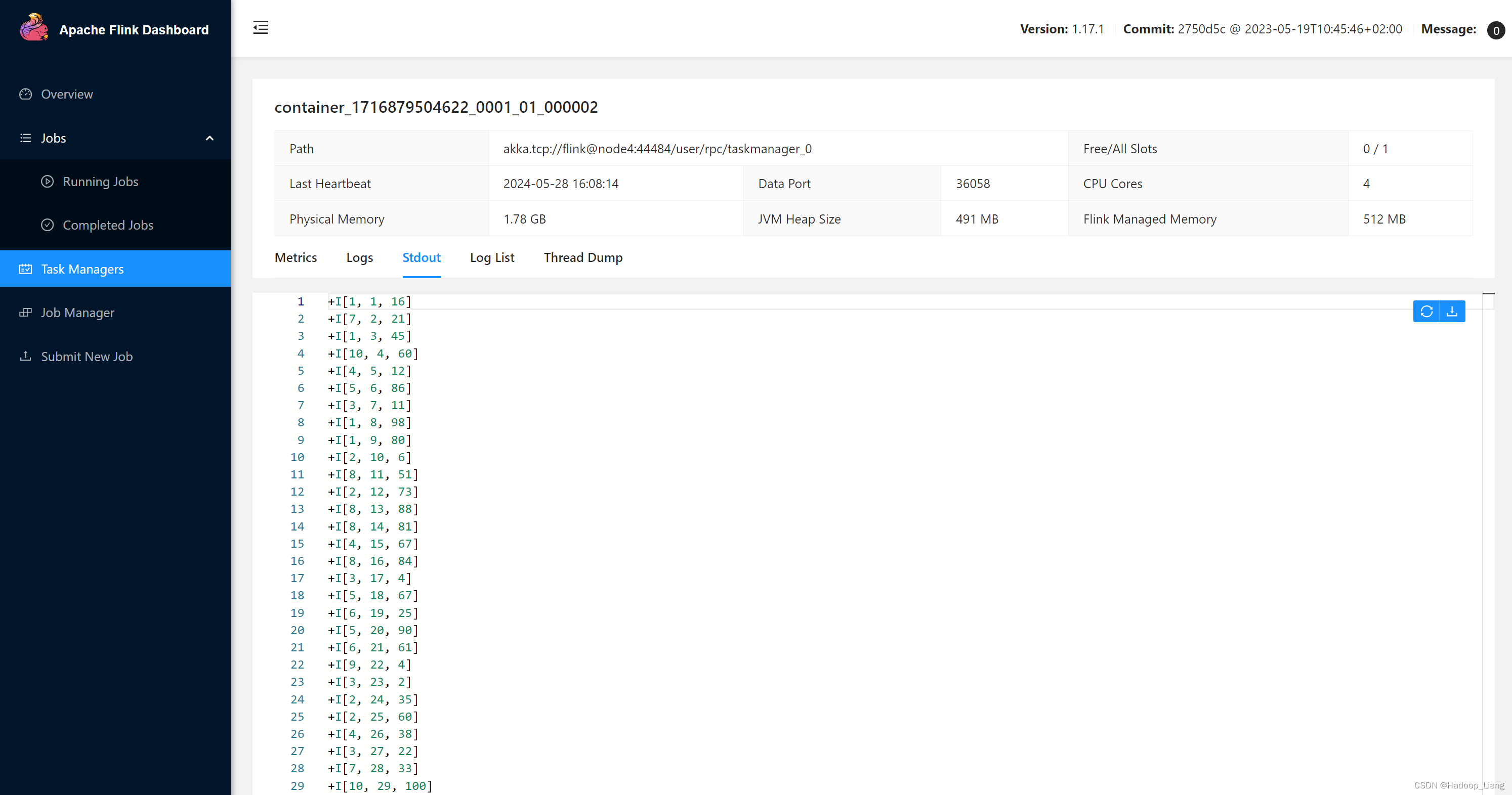
取消作业
select where
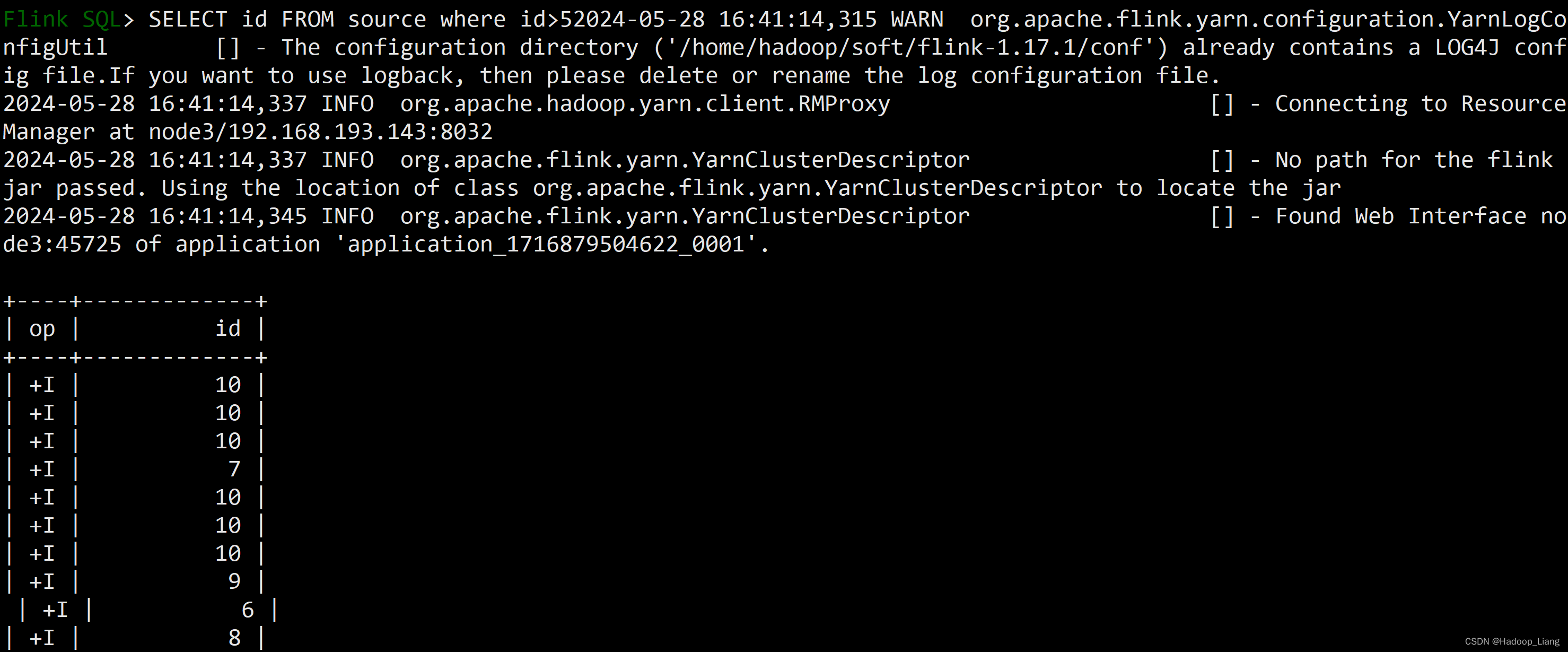
SELECT id FROM source WHERE id >5;
With子句
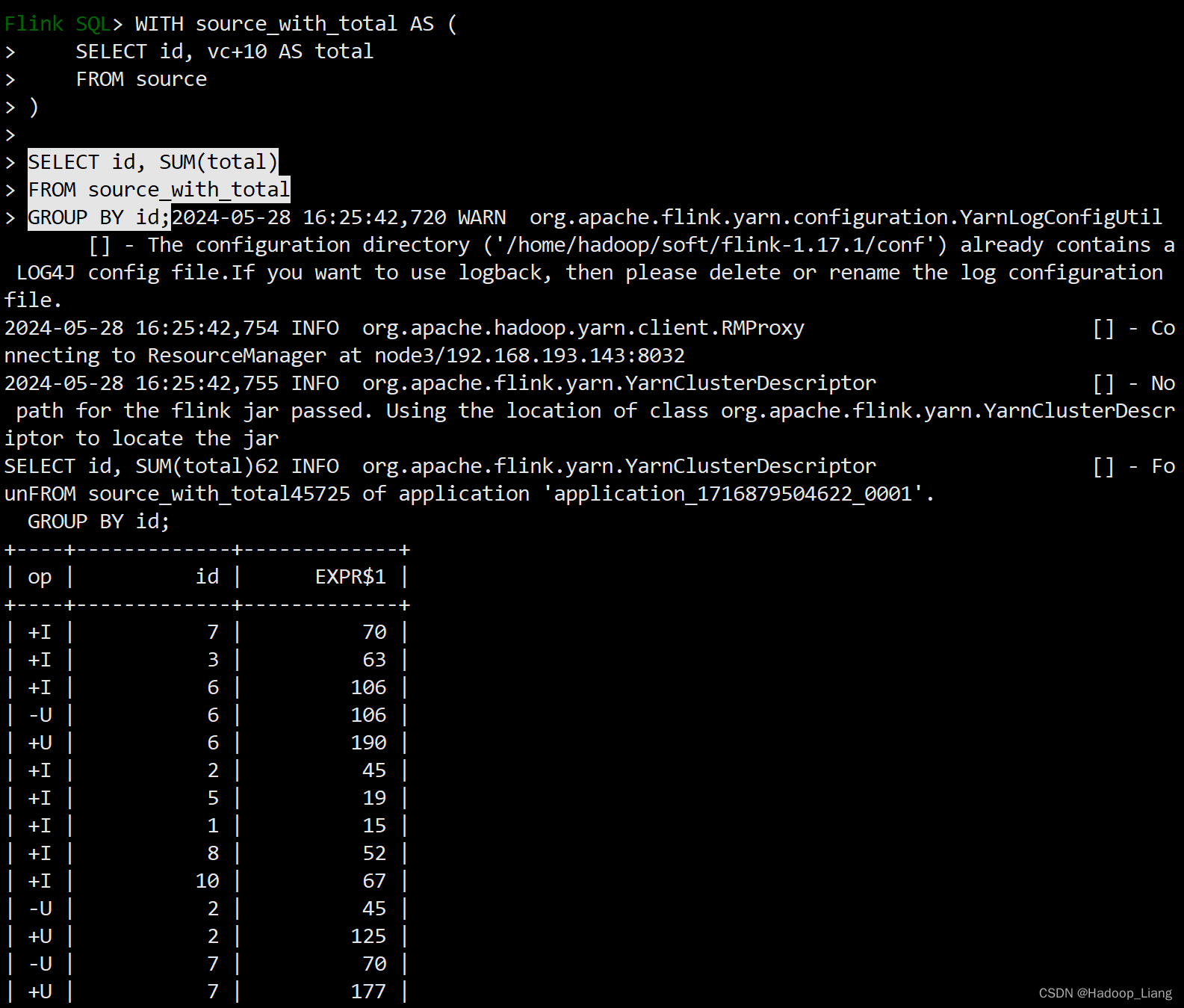
WITH提供了一种编写辅助语句的方法,以便在较大的查询中使用。这些语句通常被称为公共表表达式(Common Table Expression, CTE),可以认为它们定义了仅为一个查询而存在的临时视图。
WITH source_with_total AS ( SELECT id, vc+10 AS total FROM source ) SELECT id, SUM(total) FROM source_with_total GROUP BY id;执行效果如下
分组聚合
SELECT vc, COUNT(*) as cnt FROM source GROUP BY vc;

-U是撤回流
创建source1表
CREATE TABLE source1 ( dim STRING, user_id BIGINT, price BIGINT, row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)), WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.dim.length' = '1', 'fields.user_id.min' = '1', 'fields.user_id.max' = '100000', 'fields.price.min' = '1', 'fields.price.max' = '100000' );
创建sink1表
CREATE TABLE sink1 ( dim STRING, pv BIGINT, sum_price BIGINT, max_price BIGINT, min_price BIGINT, uv BIGINT, window_start bigint ) WITH ( 'connector' = 'print' );
查询对source1表进行分组聚合并插入到sink1表中
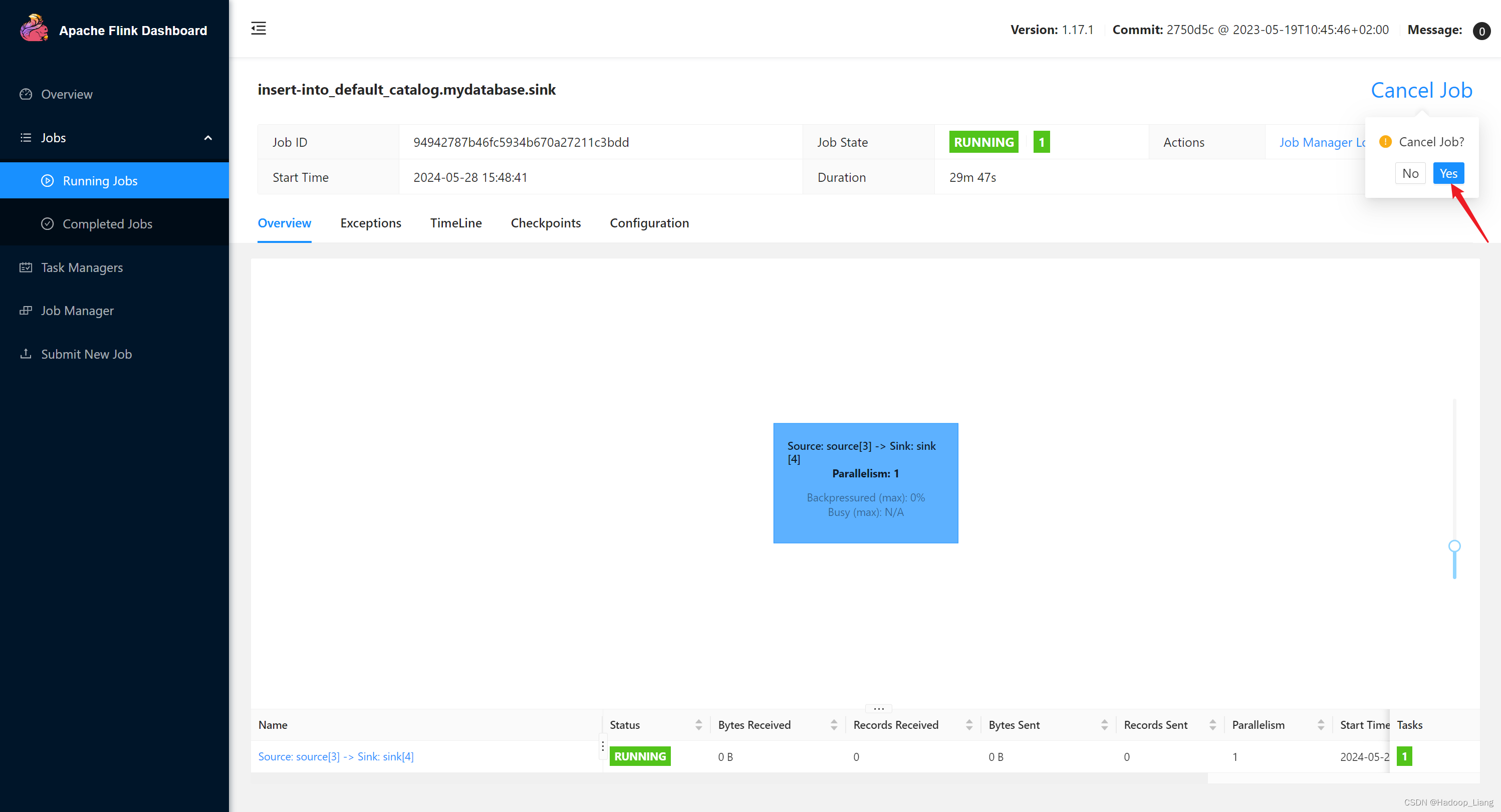
insert into sink1 select dim, count(*) as pv, sum(price) as sum_price, max(price) as max_price, min(price) as min_price, -- 计算 uv 数 count(distinct user_id) as uv, cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint) as window_start from source1 group by dim, -- UNIX_TIMESTAMP得到秒的时间戳,将秒级别时间戳 / 60 转化为 1min, cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint);
查看结果
在Web UI中取消作业。
多维分析
Group 聚合也支持 Grouping sets 、Rollup 、Cube,如下案例是Grouping sets:
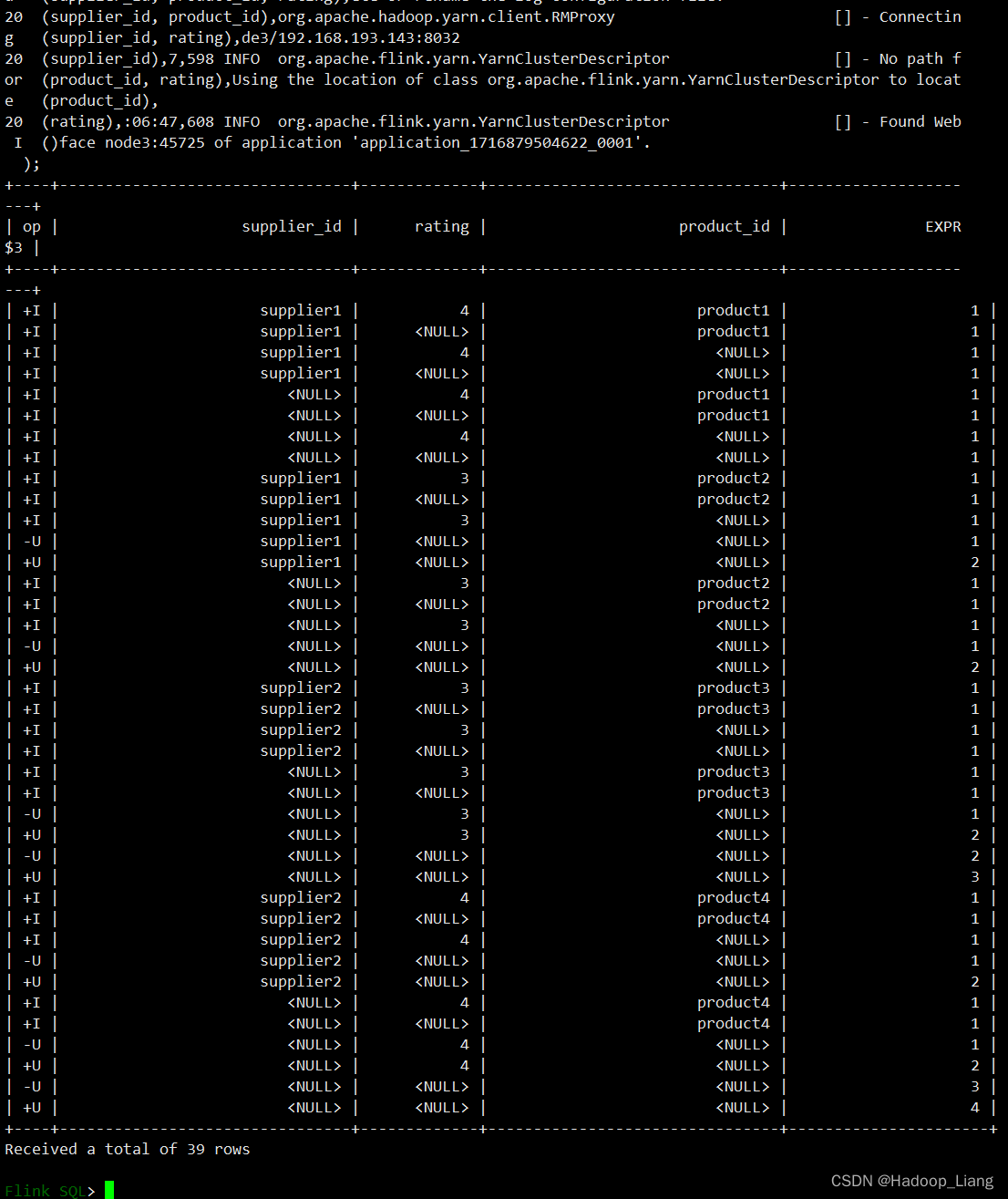
SELECT supplier_id , rating , product_id , COUNT(*) FROM ( VALUES ('supplier1', 'product1', 4), ('supplier1', 'product2', 3), ('supplier2', 'product3', 3), ('supplier2', 'product4', 4) ) -- 供应商id、产品id、评级 AS Products(supplier_id, product_id, rating) GROUP BY GROUPING SETS( (supplier_id, product_id, rating), (supplier_id, product_id), (supplier_id, rating), (supplier_id), (product_id, rating), (product_id), (rating), () );运行结果
分组窗口聚合
准备数据
CREATE TABLE ws ( id INT, vc INT, pt AS PROCTIME(), --处理时间 et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间 WATERMARK FOR et AS et - INTERVAL '5' SECOND --watermark ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.id.min' = '1', 'fields.id.max' = '3', 'fields.vc.min' = '1', 'fields.vc.max' = '100' );
滚动窗口
滚动窗口(时间属性字段,窗口长度)
select id, TUMBLE_START(et, INTERVAL '5' SECOND) wstart, TUMBLE_END(et, INTERVAL '5' SECOND) wend, sum(vc) sumVc from ws group by id, TUMBLE(et, INTERVAL '5' SECOND);
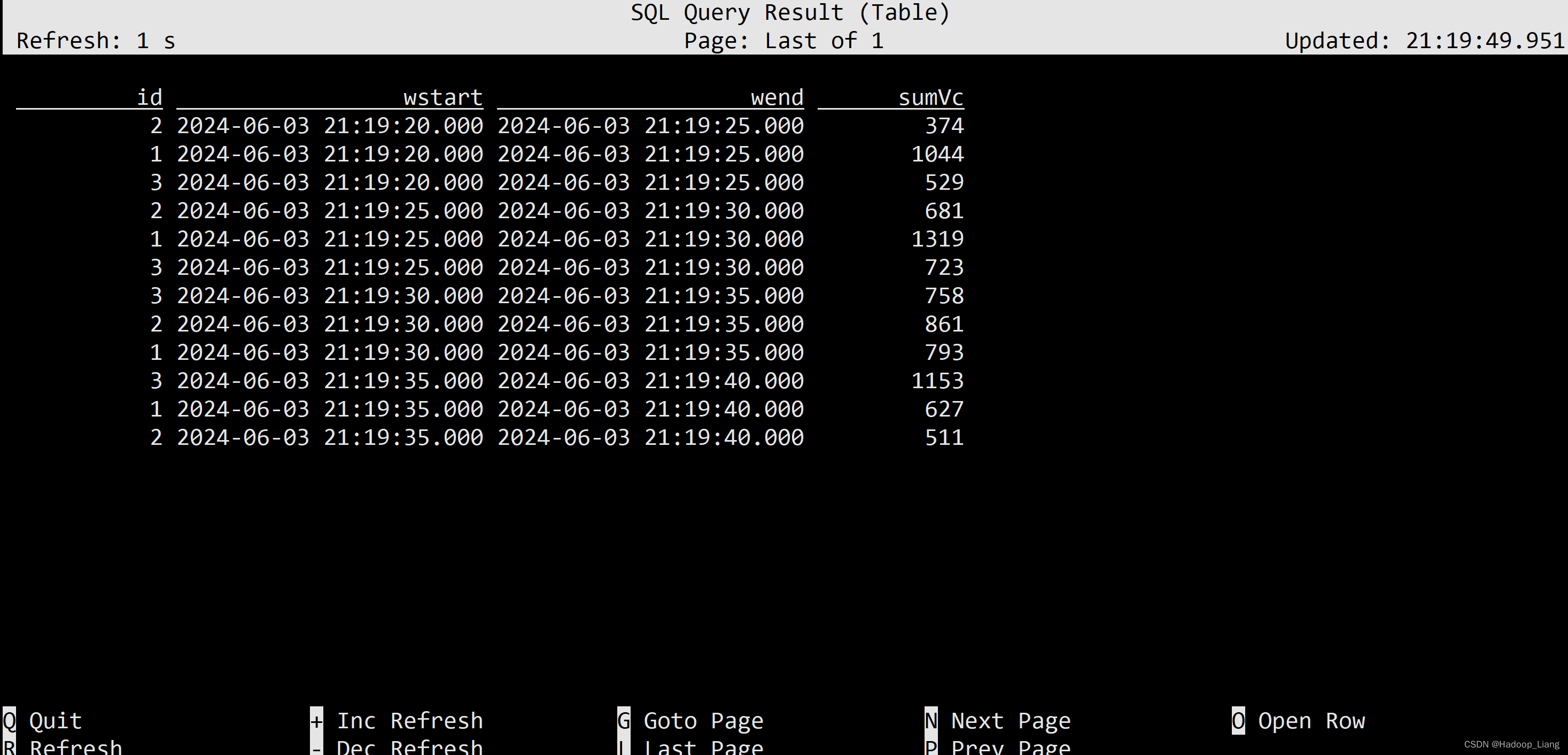
观察结果,可以看到按id分组进行统计,窗口长度(wend-wstart)为5秒,按Q退出查询。
滑动窗口
滑动窗口(时间属性字段,滑动步长,窗口长度)
select id, HOP_START(pt, INTERVAL '3' SECOND,INTERVAL '5' SECOND) wstart, HOP_END(pt, INTERVAL '3' SECOND,INTERVAL '5' SECOND) wend, sum(vc) sumVc from ws group by id, HOP(pt, INTERVAL '3' SECOND,INTERVAL '5' SECOND);
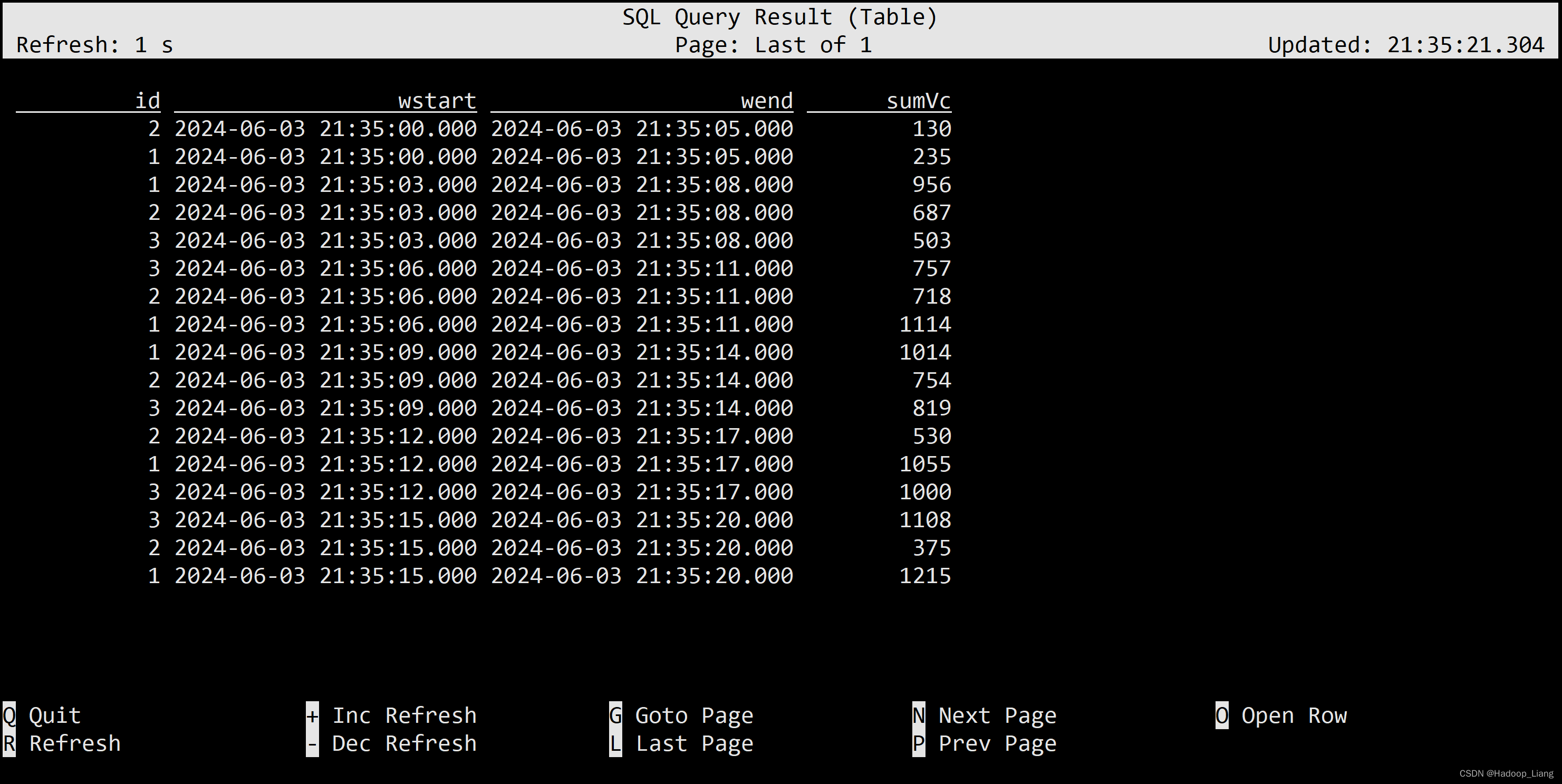
从结果中看到,窗口长度是5秒,同一id与上一个窗口滑动的步长为3秒。
会话窗口
会话窗口(时间属性字段,会话间隔)
select id, SESSION_START(et, INTERVAL '5' SECOND) wstart, SESSION_END(et, INTERVAL '5' SECOND) wend, sum(vc) sumVc from ws group by id, SESSION(et, INTERVAL '5' SECOND);
因为数据源源不断生成,所以不满足5s没有数据的会话间隔。
注意:分组窗口基本被更加强大的TVF窗口替代。
窗口表值函数(TVF)聚合
对比分组窗口(GroupWindow),TVF窗口更有效和强大。包括:
-
提供更多的性能优化手段
-
支持GroupingSets语法
-
可以在window聚合中使用TopN
-
提供累积窗口
对于窗口表值函数,窗口本身返回的是就是一个表,所以窗口会出现在FROM后面,GROUP BY后面的则是窗口新增的字段window_start和window_end
FROM TABLE( 窗口类型(TABLE 表名, DESCRIPTOR(时间字段),INTERVAL时间…) ) GROUP BY [window_start,][window_end,] --可选
滚动窗口
SELECT window_start, window_end, id , SUM(vc) sumVC FROM TABLE( TUMBLE(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS)) GROUP BY window_start, window_end, id;
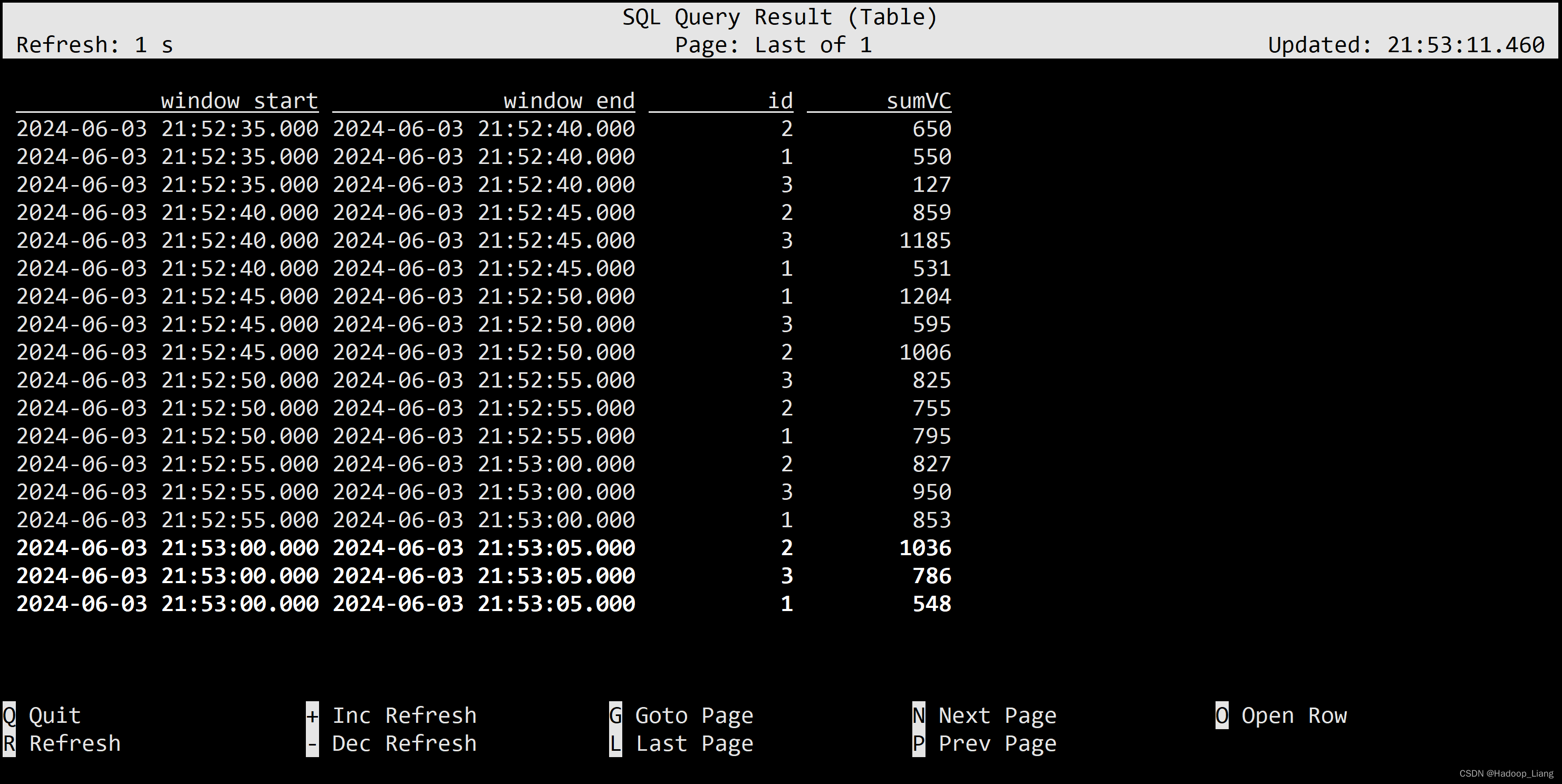
从结果来看,第一个id为2的窗口时间范围是[35,40),第二个id为2的窗口时间范围是[40,45),正是长度为5秒的滚动窗口。
滑动窗口
要求: 窗口长度=滑动步长的整数倍(底层会优化成多个小滚动窗口)
SELECT window_start, window_end, id , SUM(vc) sumVC FROM TABLE( HOP(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS , INTERVAL '10' SECONDS)) GROUP BY window_start, window_end, id;
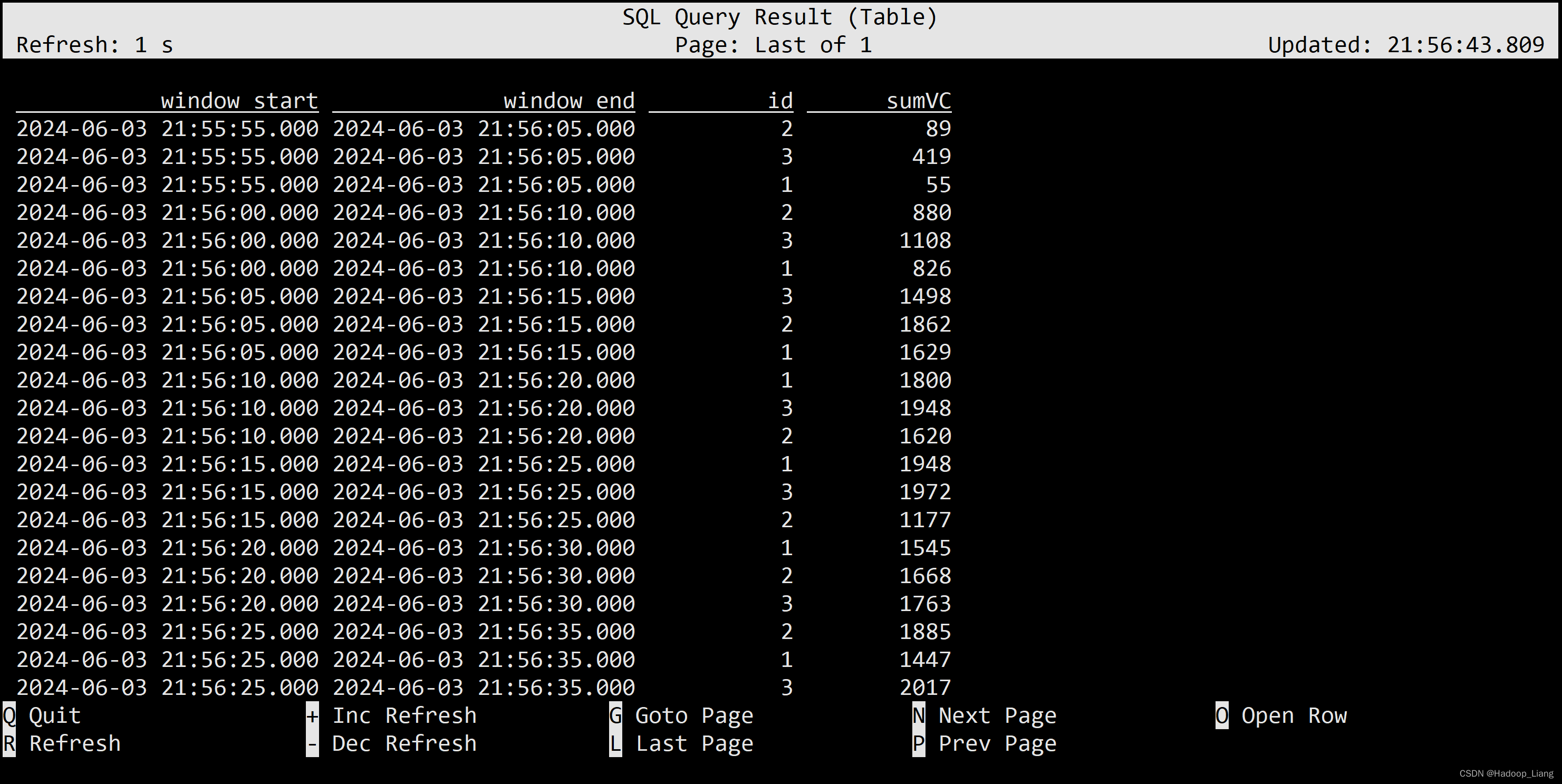
观察相同id的窗口数据,例如:id为2,时间范围[55,05),[00,10),...
数据符合窗口长度为10秒、滑动步长为5秒的滑动窗口。
累积窗口
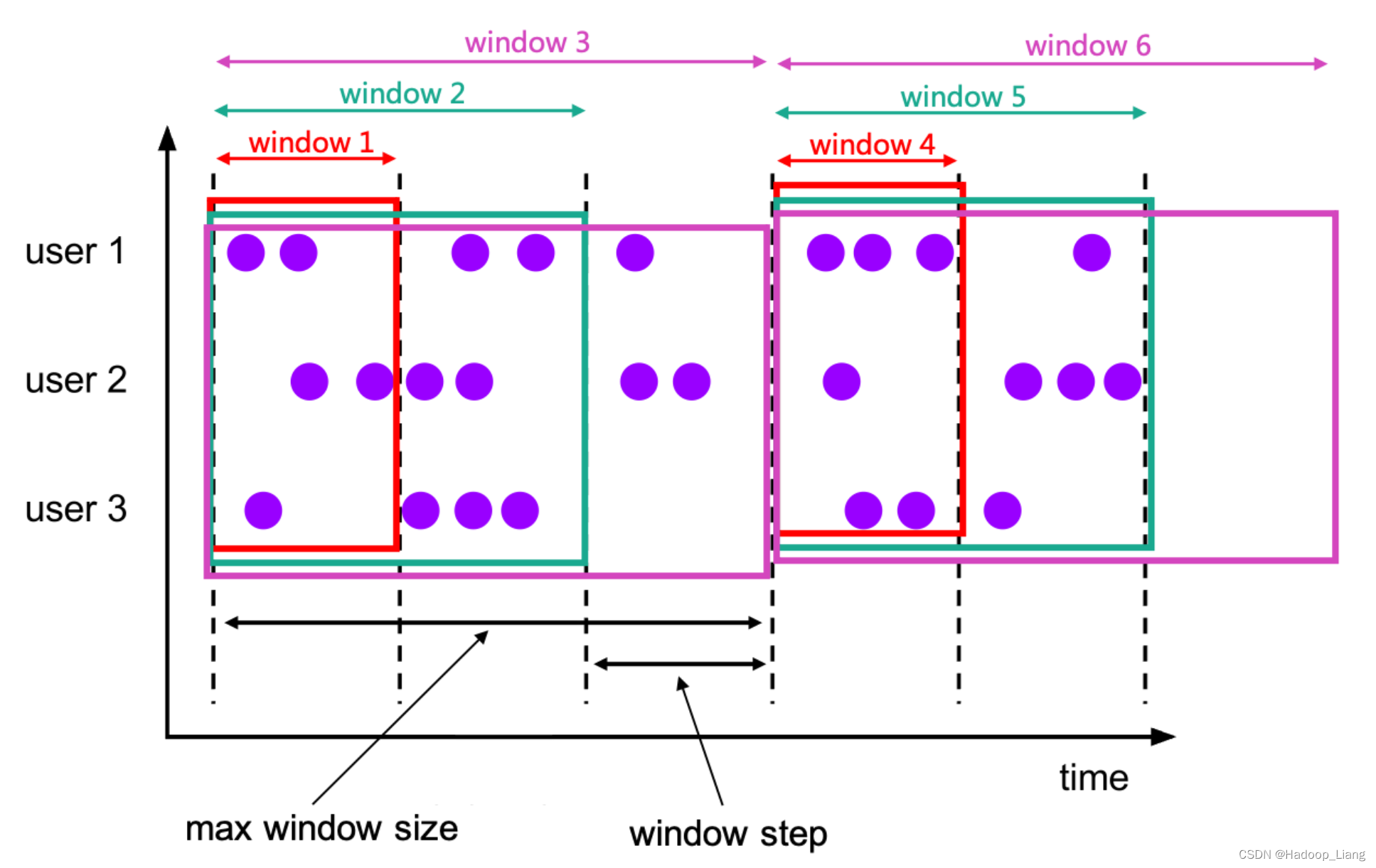
累积窗口会在一定的统计周期内进行累积计算。累积窗口中有两个核心的参数:最大窗口长度(max window size)和累积步长(step)。所谓的最大窗口长度其实就是我们所说的“统计周期”,最终目的就是统计这段时间内的数据。
注意: 窗口最大长度 = 累积步长的整数倍
SELECT window_start, window_end, id , SUM(vc) sumVC FROM TABLE( CUMULATE(TABLE ws, DESCRIPTOR(et), INTERVAL '2' SECONDS , INTERVAL '6' SECONDS)) GROUP BY window_start, window_end, id;

观察结果,id为1的窗口时间数据:[36,38),[36,40),[36,42),[42,44),...
符合累计窗口的特点。
多维分析
SELECT window_start, window_end, id , SUM(vc) sumVC FROM TABLE( TUMBLE(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS)) GROUP BY window_start, window_end, rollup( (id) ) -- cube( (id) ) -- grouping sets( (id),() ) ;
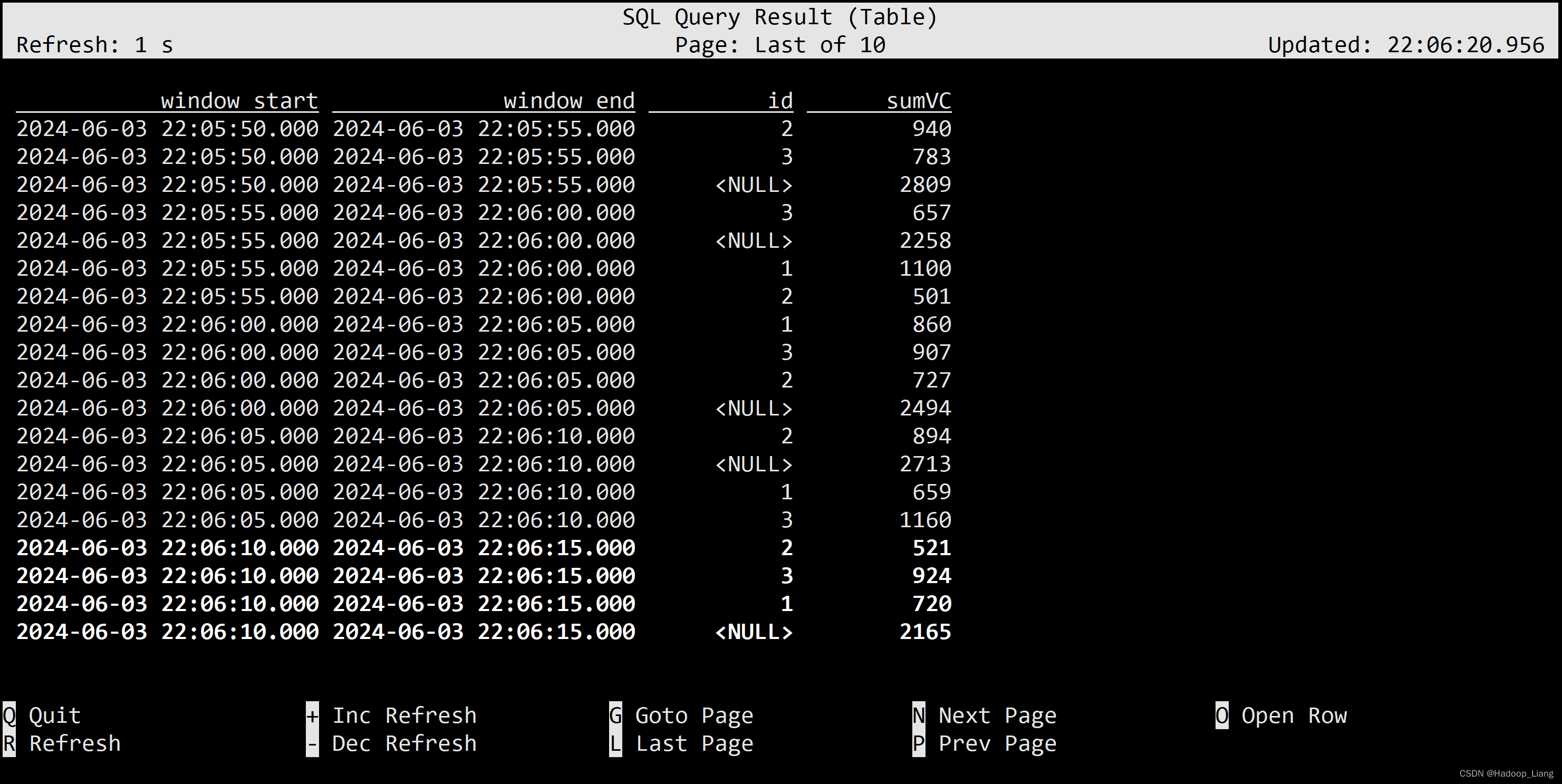
rollup在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合,获得更粗粒度的聚合数据。
从以上结果中,截取[00,05)的数据

可以看到基于id汇总,id=1 聚合值为860,id=2 聚合值为907,id=3 聚合值为727,上卷为更粗粒度(不区分id了,id在这里为NULL)的聚合数据得到2494(860+907+727=2494)。
Over 聚合
OVER聚合为一系列有序行的每个输入行计算一个聚合值。与GROUP BY聚合相比,OVER聚合不会将每个组的结果行数减少为一行。相反,OVER聚合为每个输入行生成一个聚合值。 可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义Over windows。
语法
SELECT agg_func(agg_col) OVER ( [PARTITION BY col1[, col2, ...]] ORDER BY time_col range_definition), ... FROM ...ORDER BY:必须是时间戳列,只能升序
range_definition:标识聚合窗口的聚合数据范围,有两种指定数据范围的方式,1.按照行数聚合,2.按照时间区间聚合
案例
按照时间区间聚合 统计每个传感器前10秒到现在收到的水位数据(vc)条数。
SELECT id, et, vc, count(vc) OVER ( PARTITION BY id ORDER BY et RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW ) AS cnt FROM ws;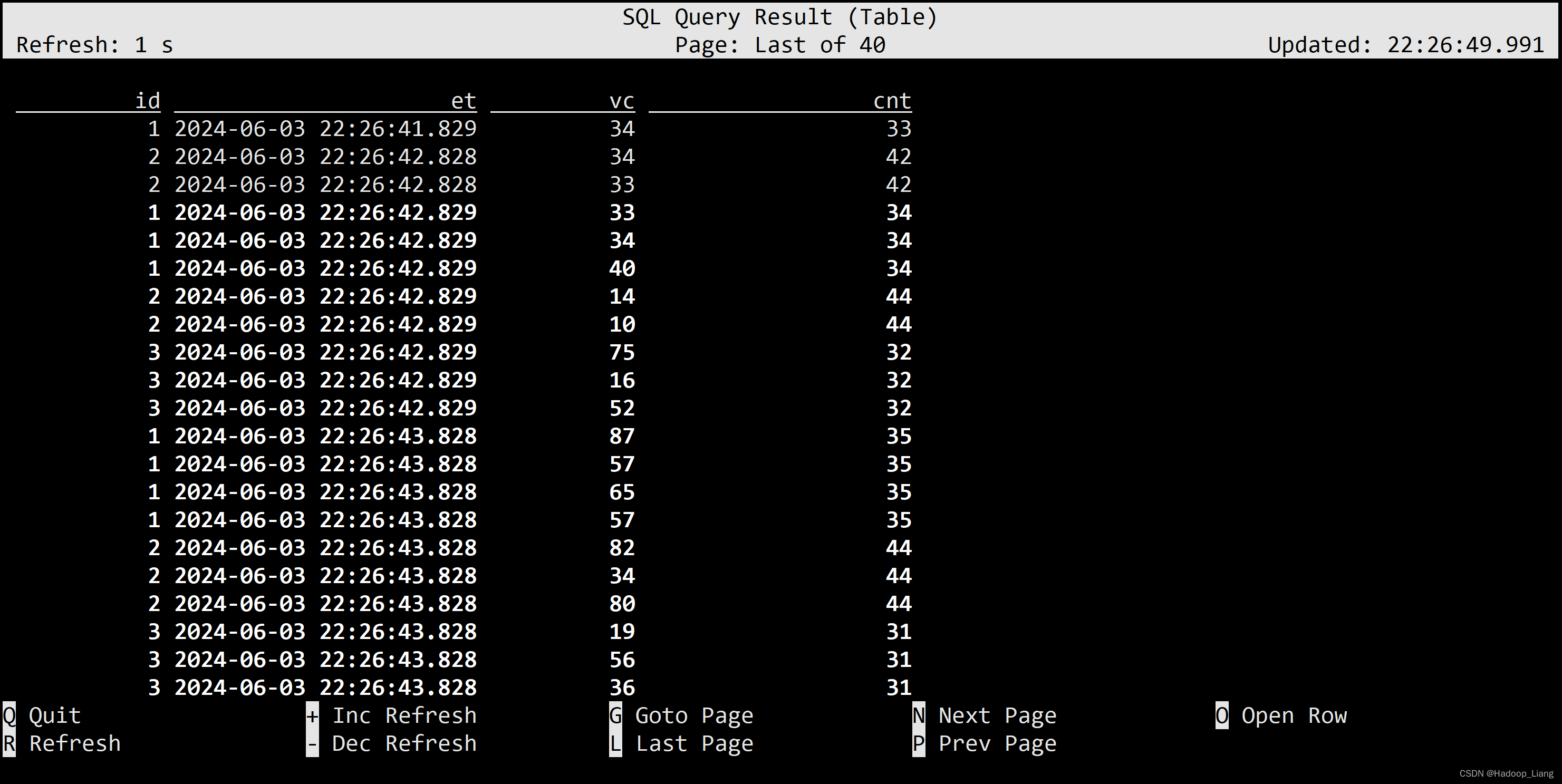
也可以用WINDOW子句来在SELECT外部单独定义一个OVER窗口,便于重复使用:
SELECT id, et, vc, count(vc) OVER w AS cnt, sum(vc) OVER w AS sumVC FROM ws WINDOW w AS ( PARTITION BY id ORDER BY et RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW );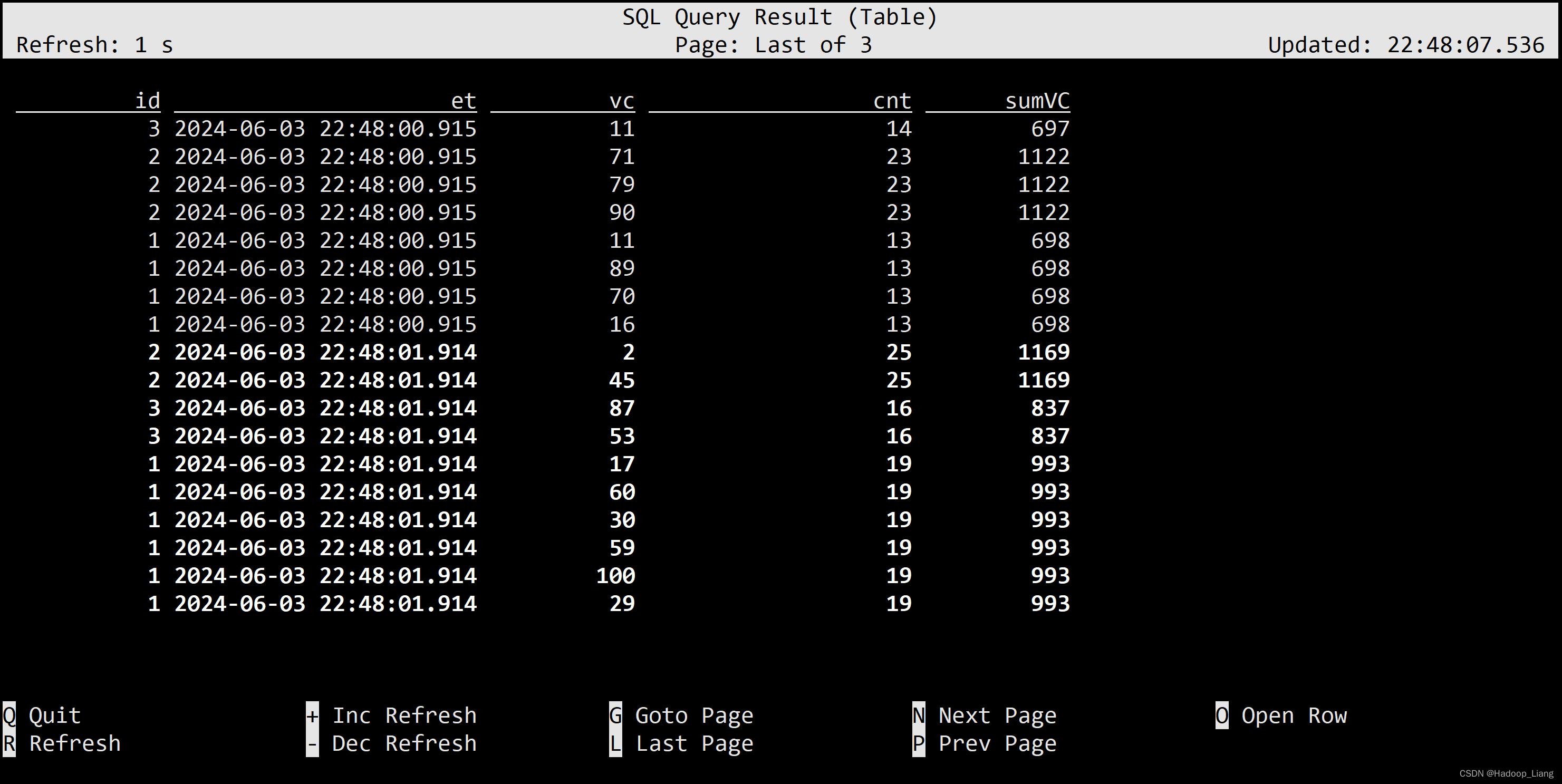
按照行数聚合 统计每个传感器前5条到现在数据的平均水位
SELECT id, et, vc, avg(vc) OVER ( PARTITION BY id ORDER BY et ROWS BETWEEN 5 PRECEDING AND CURRENT ROW ) AS avgVC FROM ws;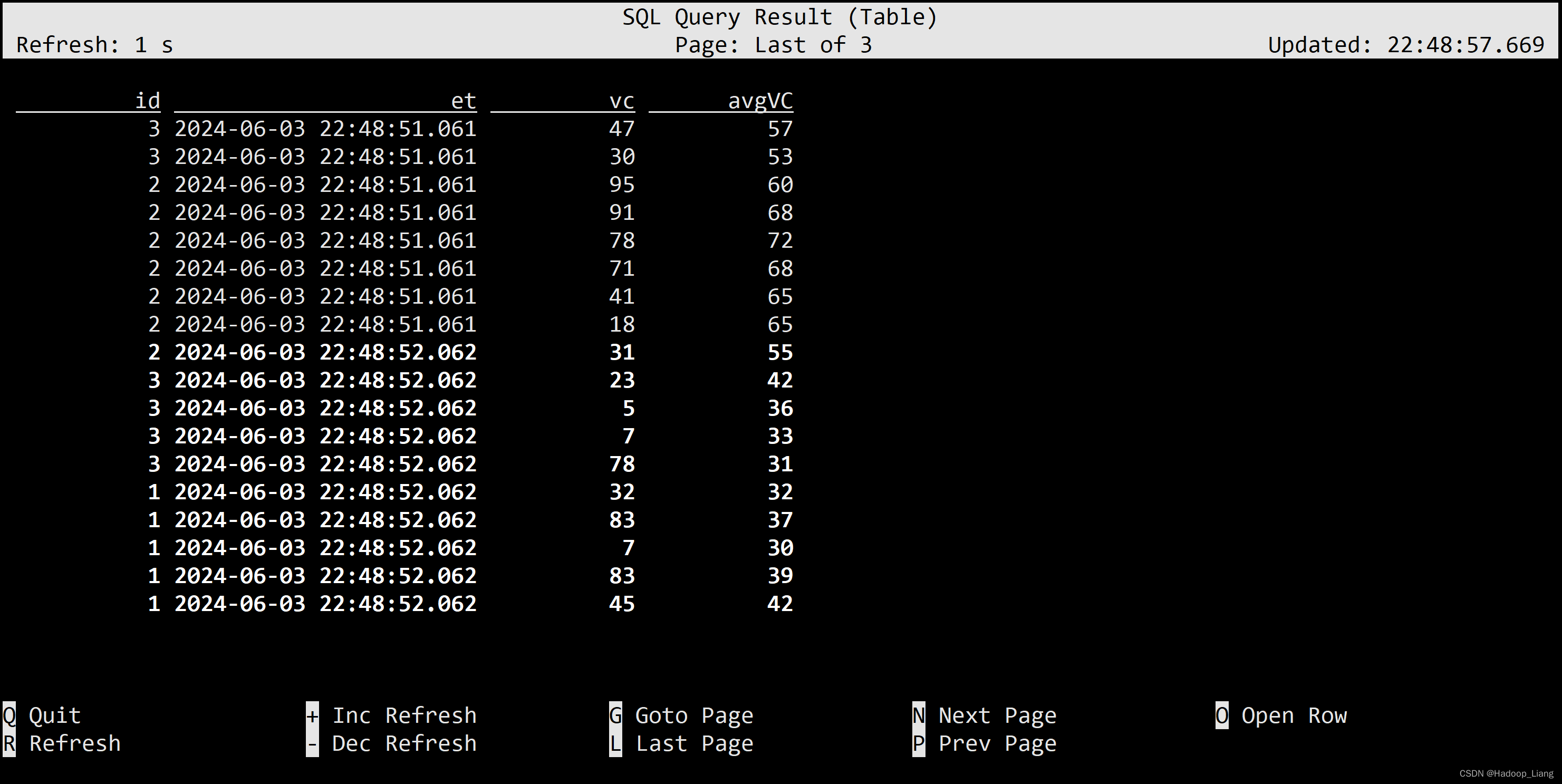
也可以用WINDOW子句来在SELECT外部单独定义一个OVER窗口:
SELECT id, et, vc, avg(vc) OVER w AS avgVC, count(vc) OVER w AS cnt FROM ws WINDOW w AS ( PARTITION BY id ORDER BY et ROWS BETWEEN 5 PRECEDING AND CURRENT ROW );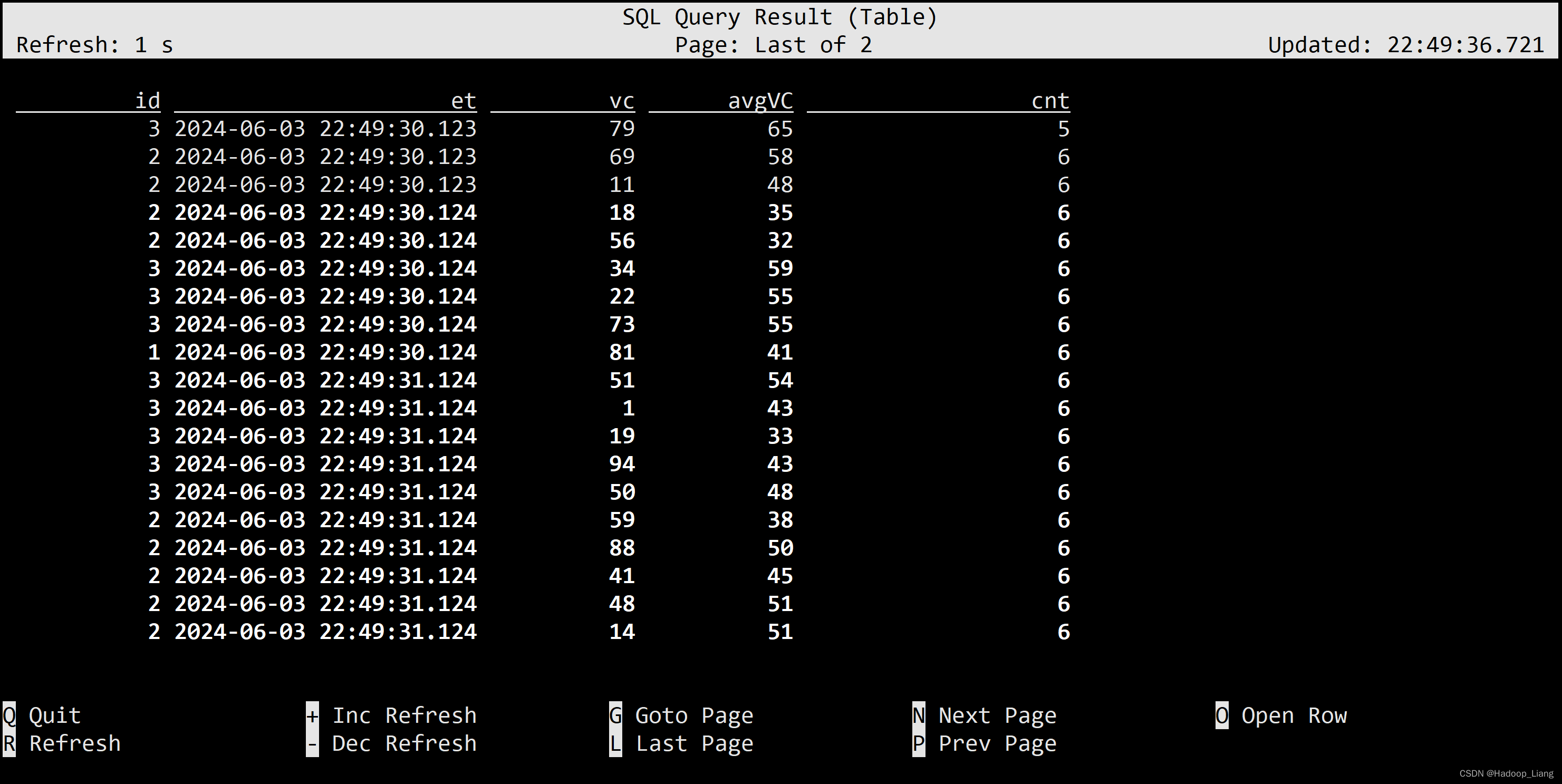
特殊语法TOP-N
ROW_NUMBER() :对数据进行排序标记,标记该行数据在排序后的编号
WHERE rownum <= N:TopN 的查询
select id, et, vc, rownum from ( select id, et, vc, row_number() over( partition by id order by vc desc ) as rownum from ws ) where rownum<=3;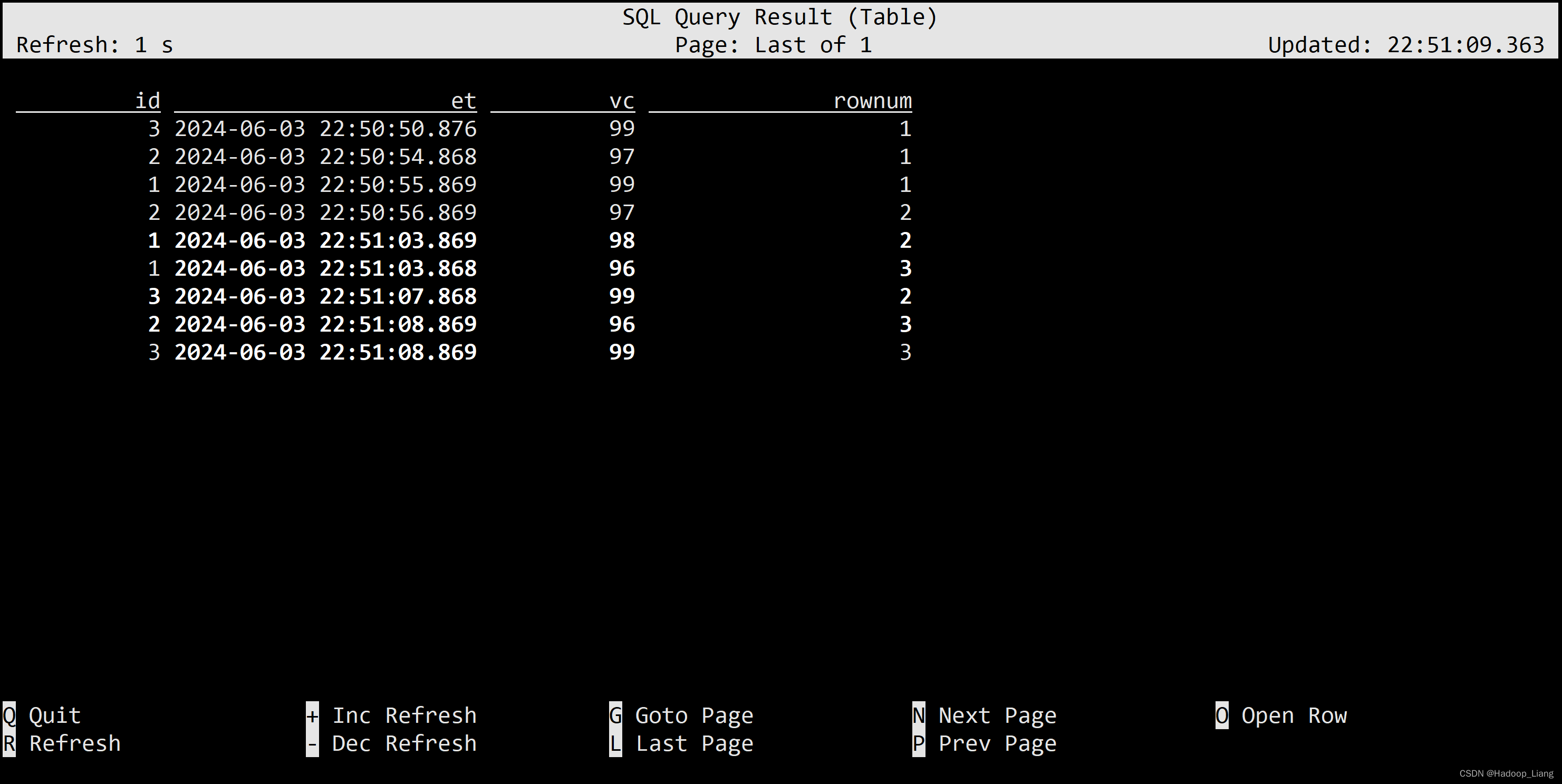
特殊语法Deduplication去重
去重,也即上文介绍到的TopN 中 row_number = 1 的场景,但排序列必须是时间属性的列。
对每个传感器的水位值去重
select id, et, vc, rownum from ( select id, et, vc, row_number() over( partition by id,vc order by et ) as rownum from ws ) where rownum=1;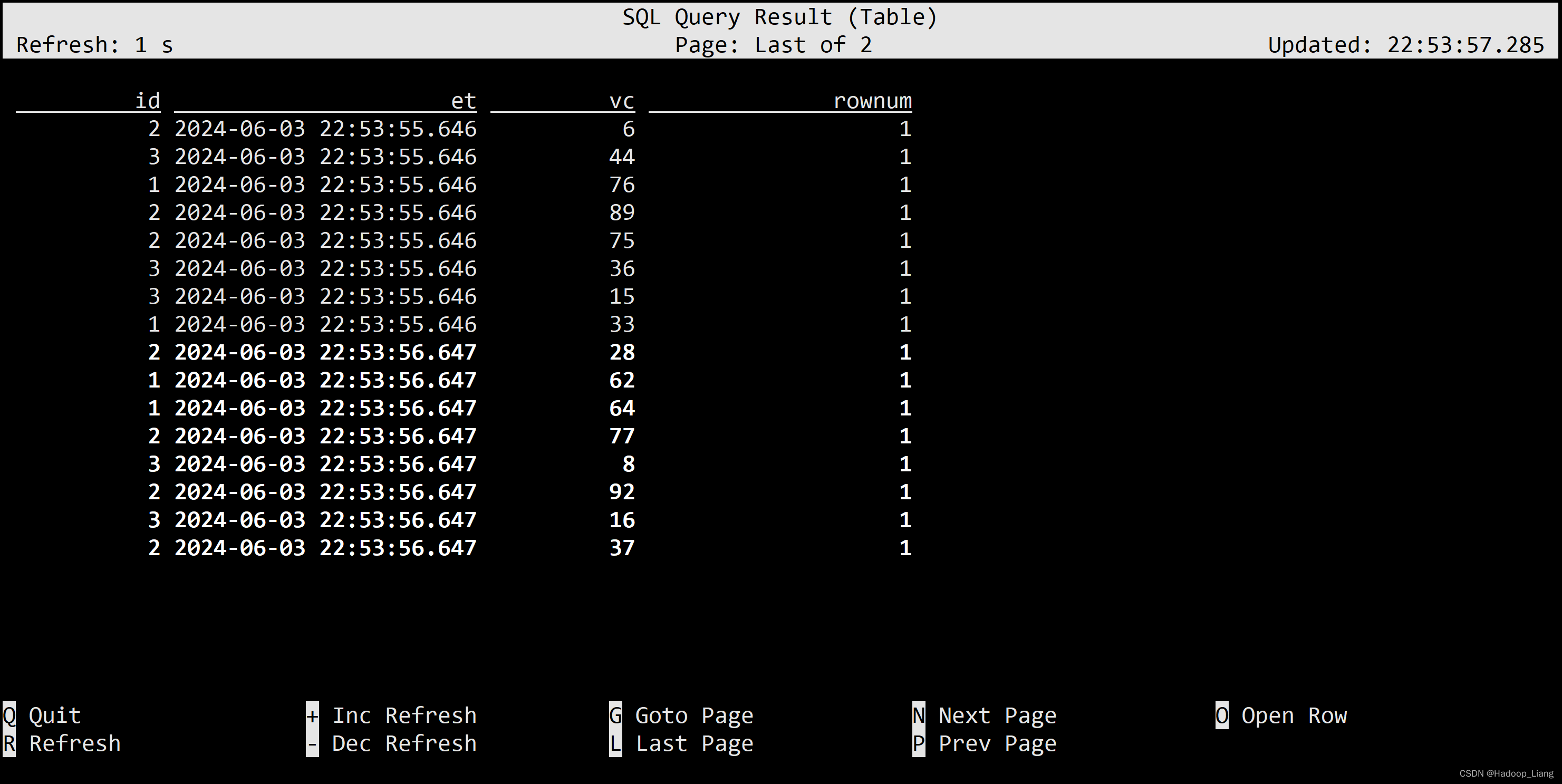
联结(Join)查询
常规联结查询
再准备一张表用于join
CREATE TABLE ws1 ( id INT, vc INT, pt AS PROCTIME(), --处理时间 et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间 WATERMARK FOR et AS et - INTERVAL '0.001' SECOND --watermark ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '1', 'fields.id.min' = '3', 'fields.id.max' = '5', 'fields.vc.min' = '1', 'fields.vc.max' = '100' );
等值内联结(INNER Equi-JOIN) 内联结用INNER JOIN来定义,会返回两表中符合联接条件的所有行的组合,也就是所谓的笛卡尔积(Cartesian product)。目前仅支持等值联结条件。
SELECT * FROM ws INNER JOIN ws1 ON ws.id = ws1.id;
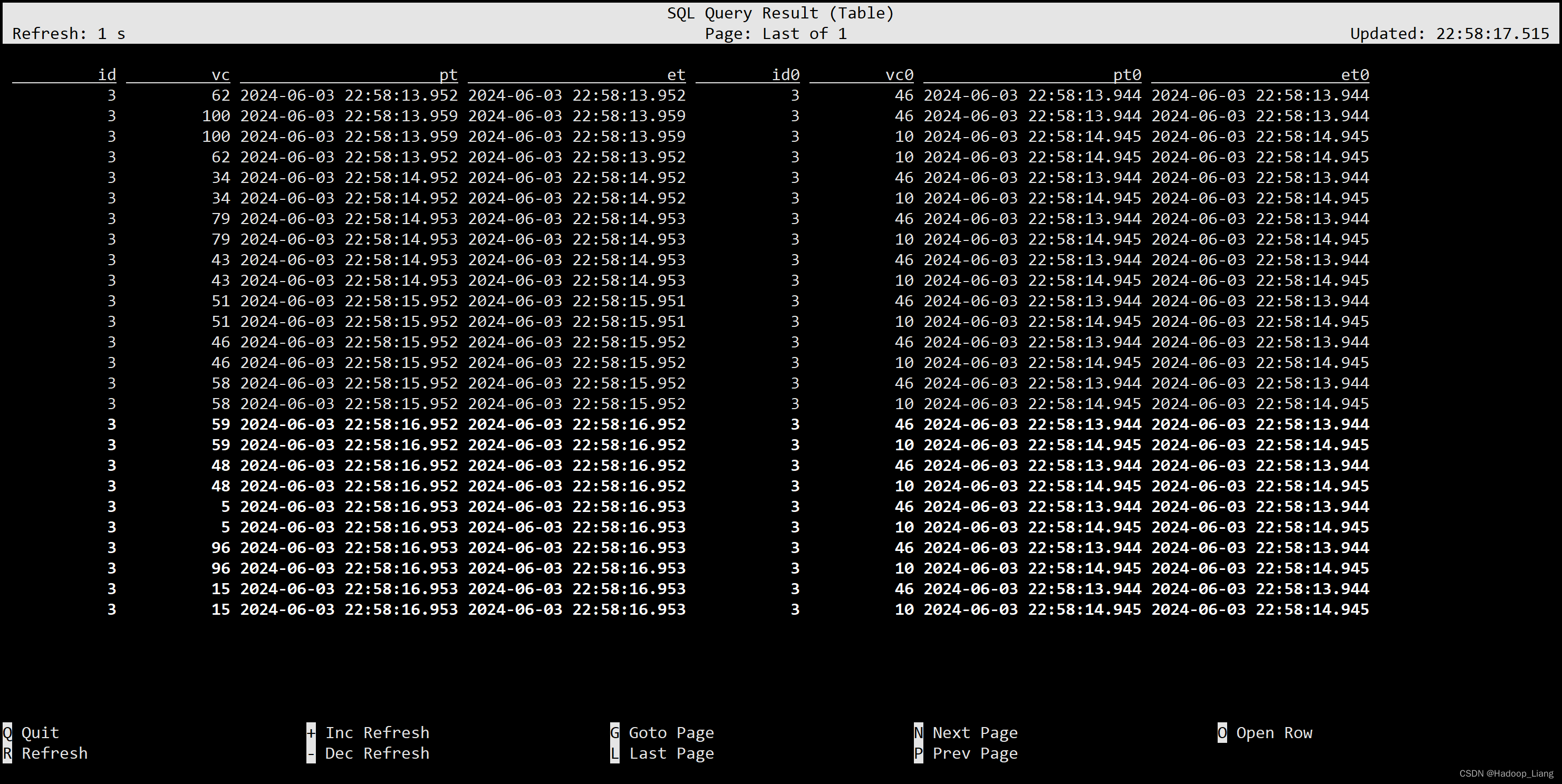
等值外联结(OUTER Equi-JOIN)
与内联结类似,外联结也会返回符合联结条件的所有行的笛卡尔积;另外,还可以将某一侧表中找不到任何匹配的行也单独返回。Flink SQL支持左外(LEFT JOIN)、右外(RIGHT JOIN)和全外(FULL OUTER JOIN),分别表示会将左侧表、右侧表以及双侧表中没有任何匹配的行返回。
SELECT * FROM ws LEFT JOIN ws1 ON ws.id = ws1.id;
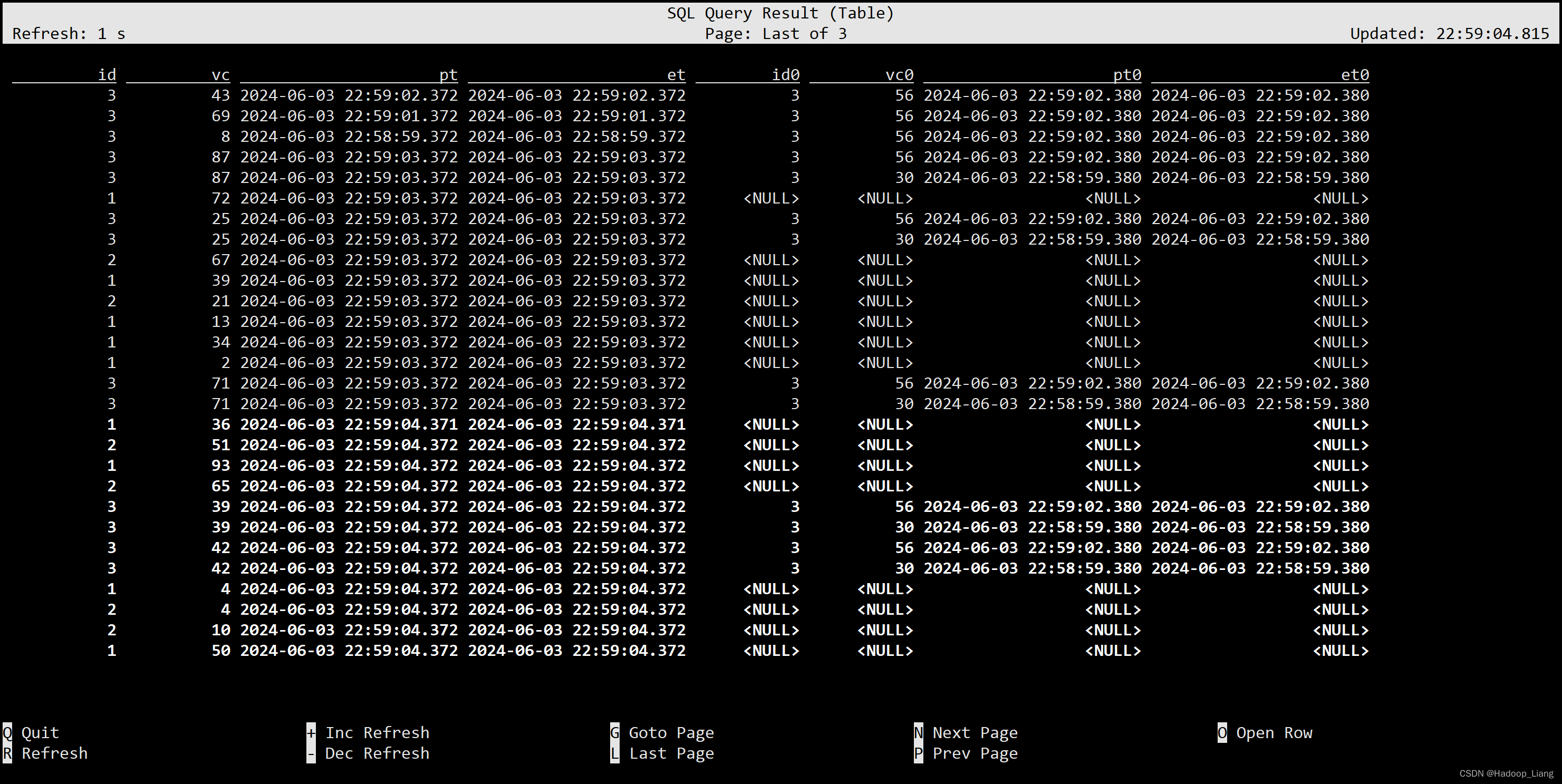
间隔联结查询
SELECT * FROM ws,ws1 WHERE ws.id = ws1. id AND ws.et BETWEEN ws1.et - INTERVAL '2' SECOND AND ws1.et + INTERVAL '2' SECOND;
查看Web UI Running Job

控制台结果

Order by 和 Limit
SELECT * FROM ws ORDER BY et, id desc;
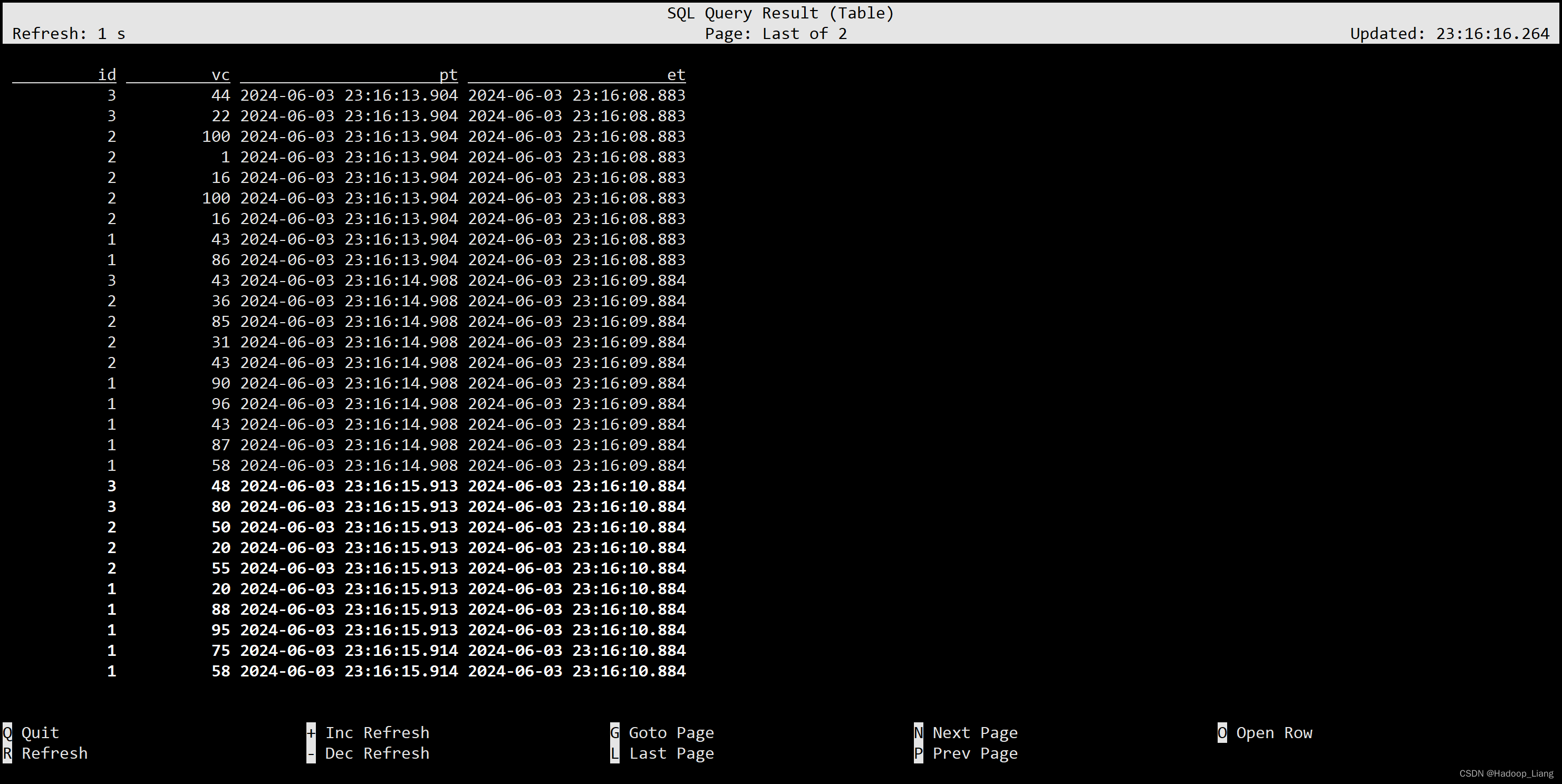
SELECT * FROM ws LIMIT 3;

SQL Hints
在执行查询时,可以在表名后面添加SQL Hints来临时修改表属性,对当前job生效。
select * from ws1/*+ OPTIONS('rows-per-second'='10')*/;集合操作
并集
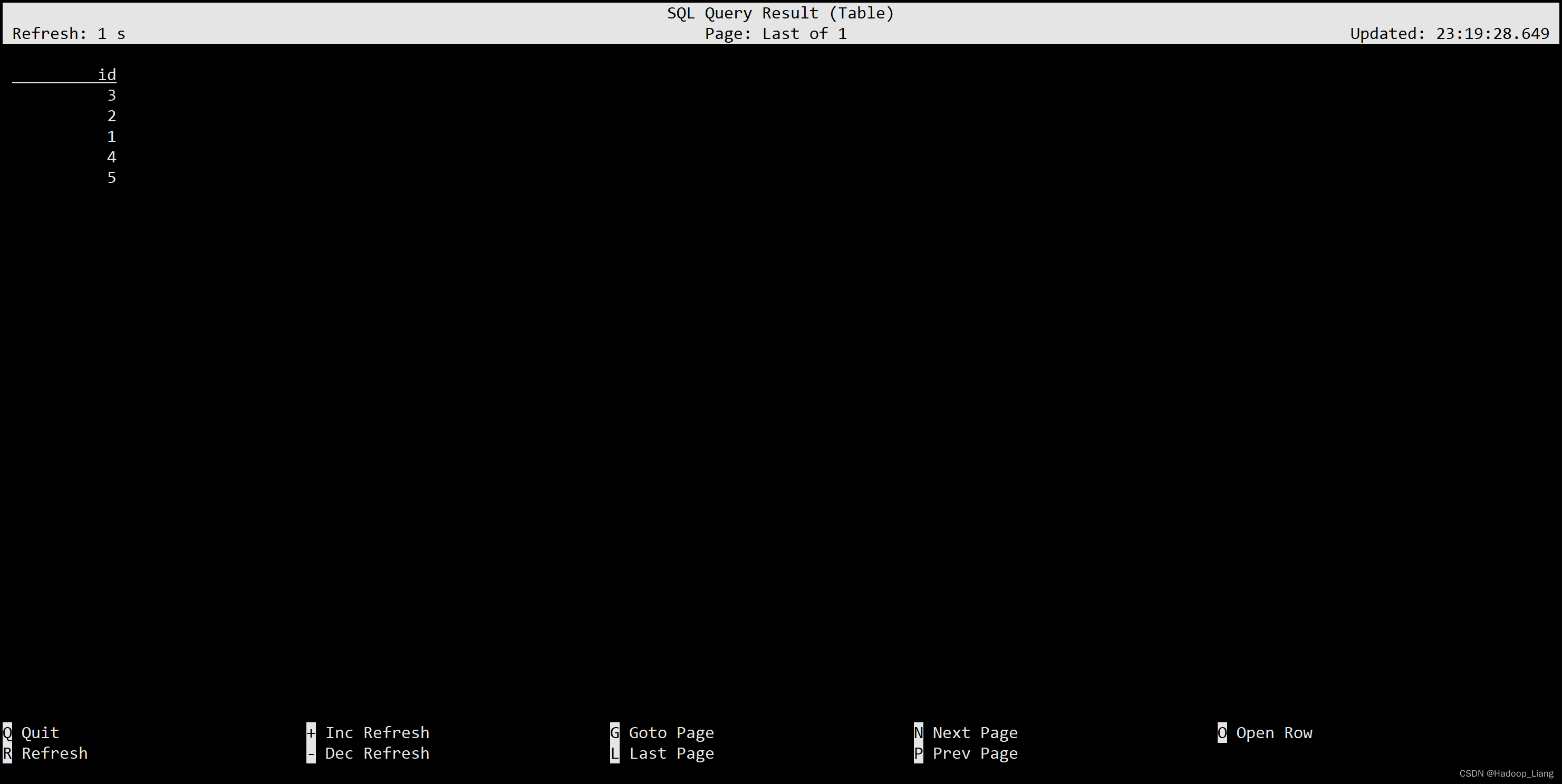
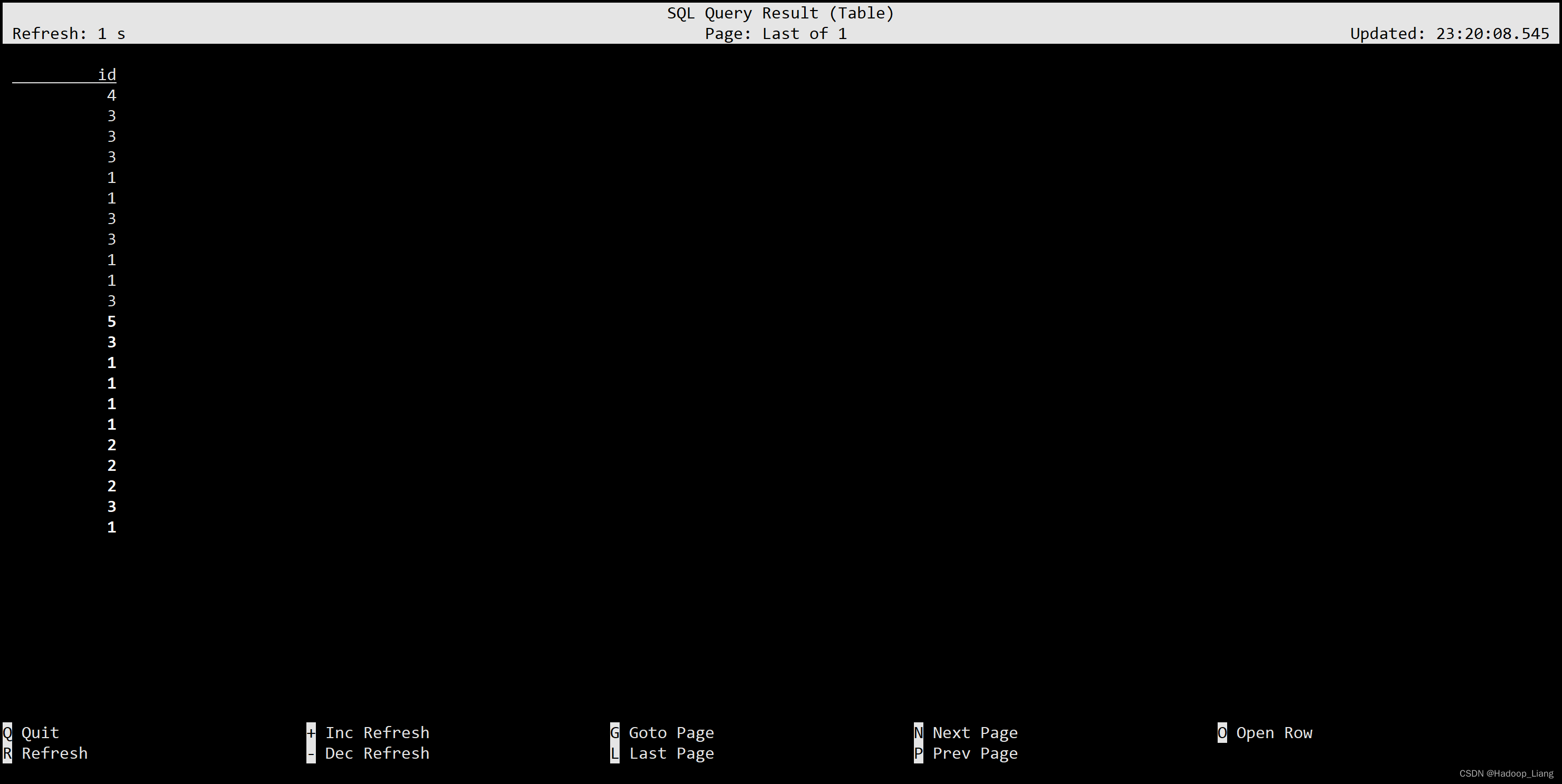
1)UNION 和 UNION ALL
UNION:将集合合并并且去重
UNION ALL:将集合合并,不做去重
(SELECT id FROM ws) UNION (SELECT id FROM ws1);
(SELECT id FROM ws) UNION ALL (SELECT id FROM ws1);
交集
Intersect 和 Intersect All
Intersect:交集并且去重
Intersect ALL:交集不做去重
(SELECT id FROM ws) INTERSECT (SELECT id FROM ws1);
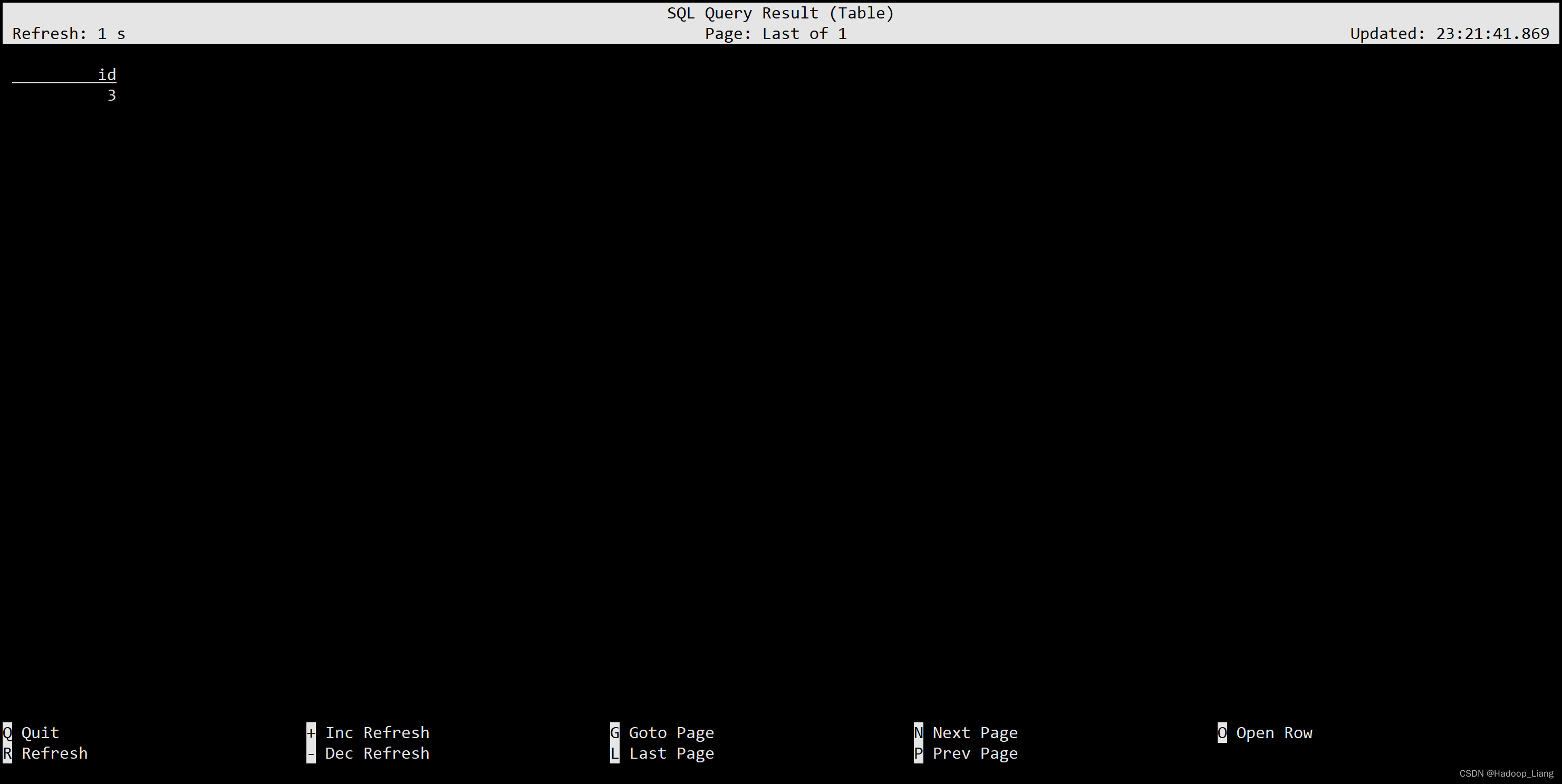
(SELECT id FROM ws) INTERSECT ALL (SELECT id FROM ws1);
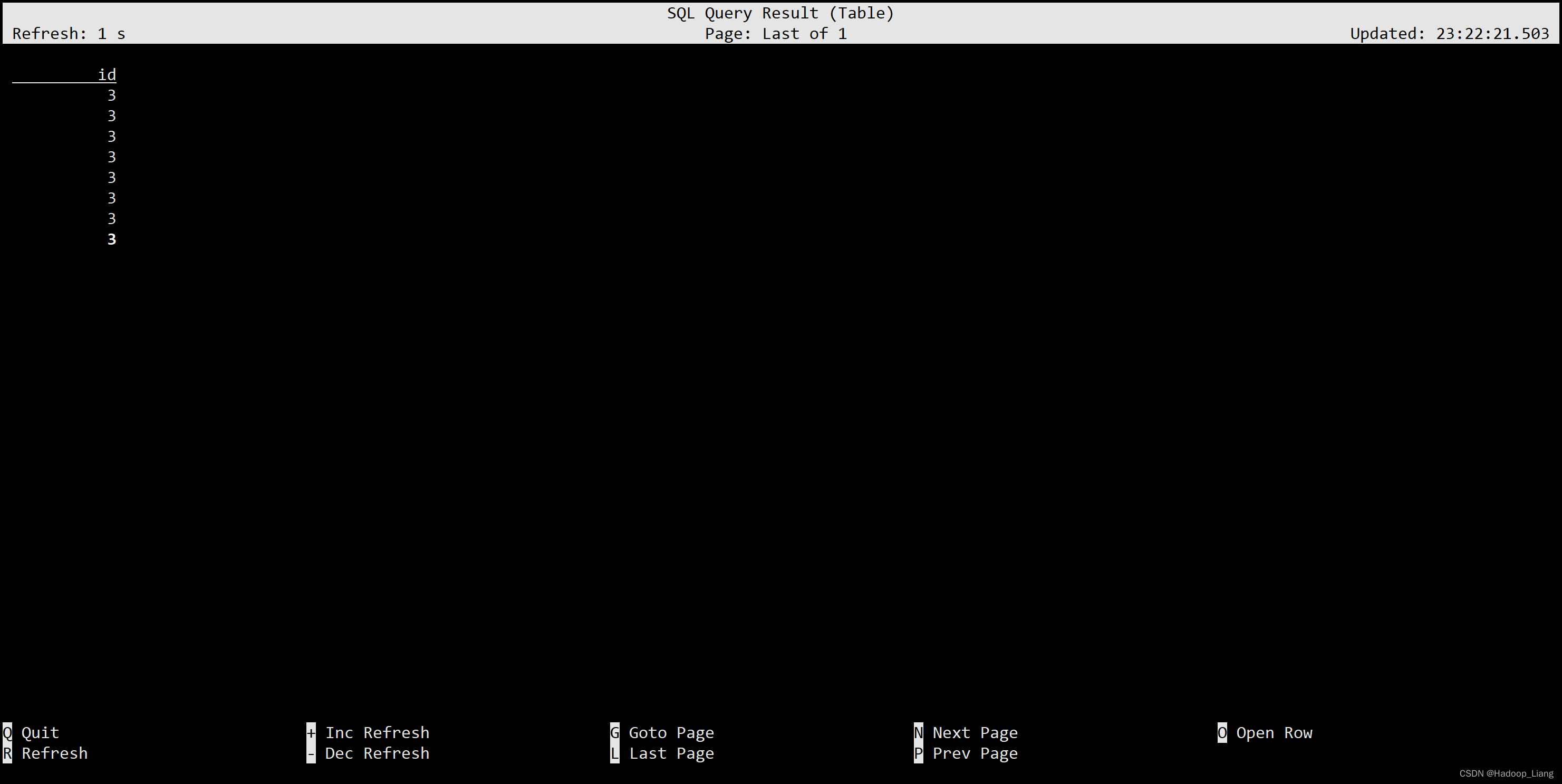
差集
Except 和 Except All
Except:差集并且去重
Except ALL:差集不做去重
(SELECT id FROM ws) EXCEPT (SELECT id FROM ws1);

(SELECT id FROM ws) EXCEPT ALL (SELECT id FROM ws1);
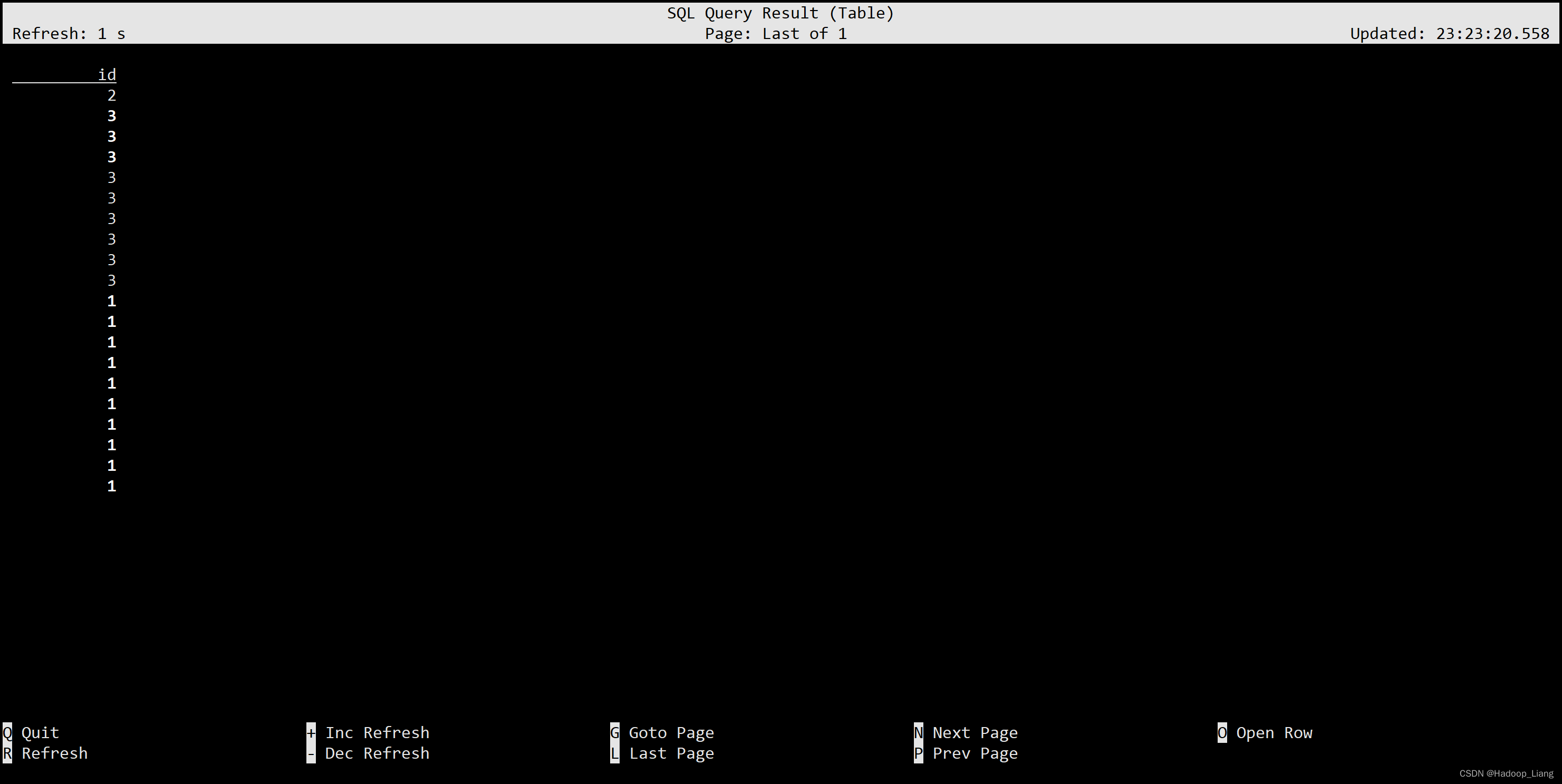
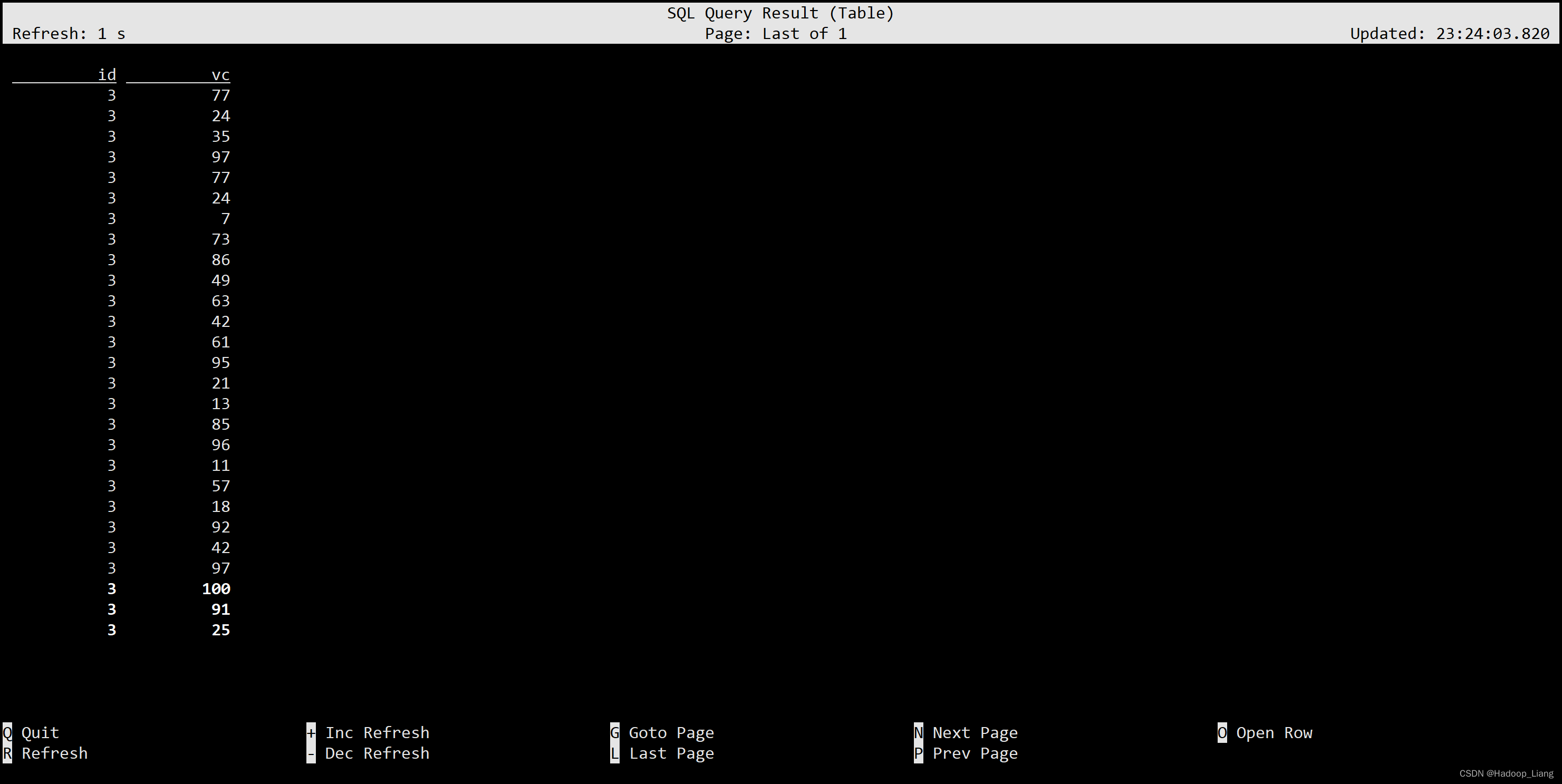
In 子查询
In 子查询的结果集只能有一列
SELECT id, vc FROM ws WHERE id IN ( SELECT id FROM ws1 );
系统函数
系统函数(System Functions)也叫内置函数(Built-in Functions),是在系统中预先实现好的功能模块。我们可以通过固定的函数名直接调用,实现想要的转换操作。Flink SQL提供了大量的系统函数,几乎支持所有的标准SQL中的操作,这为我们使用SQL编写流处理程序提供了极大的方便。
查看Flink有哪些内置函数。
show functions;
Flink SQL中的系统函数又主要可以分为两大类:标量函数(Scalar Functions)和聚合函数(Aggregate Functions)。
1)标量函数(Scalar Functions)
标量函数指的就是只对输入数据做转换操作、返回一个值的函数。 标量函数是最常见、也最简单的一类系统函数,数量非常庞大,很多在标准SQL中也有定义。所以我们这里只对一些常见类型列举部分函数,做一个简单概述,具体应用可以查看官网的完整函数列表。
比较函数(Comparison Functions) 比较函数其实就是一个比较表达式,用来判断两个值之间的关系,返回一个布尔类型的值。这个比较表达式可以是用 <、>、= 等符号连接两个值,也可以是用关键字定义的某种判断。例如:
(1)value1 = value2 判断两个值相等; (2)value1 <> value2 判断两个值不相等 (3)value IS NOT NULL 判断value不为空
逻辑函数(Logical Functions)
逻辑函数就是一个逻辑表达式,也就是用与(AND)、或(OR)、非(NOT)将布尔类型的值连接起来,也可以用判断语句(IS、IS NOT)进行真值判断;返回的还是一个布尔类型的值。例如: (1)boolean1 OR boolean2 布尔值boolean1与布尔值boolean2取逻辑或 (2)boolean IS FALSE 判断布尔值boolean是否为false (3)NOT boolean 布尔值boolean取逻辑非
算术函数(Arithmetic Functions)
进行算术计算的函数,包括用算术符号连接的运算,和复杂的数学运算。例如:
(1)numeric1 + numeric2 两数相加 (2)POWER(numeric1, numeric2) 幂运算,取数numeric1的numeric2次方 (3)RAND() 返回(0.0, 1.0)区间内的一个double类型的伪随机数
字符串函数(String Functions)
进行字符串处理的函数。例如: (1)string1 || string2 两个字符串的连接 (2)UPPER(string) 将字符串string转为全部大写 (3)CHAR_LENGTH(string) 计算字符串string的长度
时间函数(Temporal Functions)
进行与时间相关操作的函数。例如: (1)DATE string 按格式"yyyy-MM-dd"解析字符串string,返回类型为SQL Date (2)TIMESTAMP string 按格式"yyyy-MM-dd HH:mm:ss[.SSS]"解析,返回类型为SQL timestamp (3)CURRENT_TIME 返回本地时区的当前时间,类型为SQL time(与LOCALTIME等价) (4)INTERVAL string range 返回一个时间间隔。
2)聚合函数(Aggregate Functions)
聚合函数是以表中多个行作为输入,提取字段进行聚合操作的函数,会将唯一的聚合值作为结果返回。聚合函数应用非常广泛,不论分组聚合、窗口聚合还是开窗(Over)聚合,对数据的聚合操作都可以用相同的函数来定义。 标准SQL中常见的聚合函数Flink SQL都是支持的,目前也在不断扩展,为流处理应用提供更强大的功能。例如:
(1)COUNT(*) 返回所有行的数量,统计个数。 (2)SUM([ ALL | DISTINCT ] expression) 对某个字段进行求和操作。默认情况下省略了关键字ALL,表示对所有行求和;如果指定DISTINCT,则会对数据进行去重,每个值只叠加一次。 (3)RANK() 返回当前值在一组值中的排名。 (4)ROW_NUMBER() 对一组值排序后,返回当前值的行号。 其中,RANK()和ROW_NUMBER()一般用在OVER窗口中。
具体可以参考:
Flink官网系统函数
Module操作
Module 允许 Flink 扩展函数能力。它是可插拔的,Flink 官方本身已经提供了一些 Module,用户也可以编写自己的 Module。
目前 Flink 包含了以下三种 Module:
- CoreModule:CoreModule 是 Flink 内置的 Module,其包含了目前 Flink 内置的所有 UDF,Flink 默认开启的 Module 就是 CoreModule,我们可以直接使用其中的 UDF
- HiveModule:HiveModule 可以将 Hive 内置函数作为 Flink 的系统函数提供给 SQL\Table API 用户进行使用,比如 get_json_object 这类 Hive 内置函数(Flink 默认的 CoreModule 是没有的)
- 用户自定义 Module:用户可以实现 Module 接口实现自己的 UDF 扩展 Module 使用 LOAD 子句去加载 Flink SQL 体系内置的或者用户自定义的 Module,UNLOAD 子句去卸载 Flink SQL 体系内置的或者用户自定义的 Module。
1)语法
-- 加载 LOAD MODULE module_name [WITH ('key1' = 'val1', 'key2' = 'val2', ...)] -- 卸载 UNLOAD MODULE module_name -- 查看 SHOW MODULES; SHOW FULL MODULES;在 Flink 中,Module 可以被 加载、启用 、禁用 、卸载 Module,当加载Module 之后,默认就是开启的。同时支持多个 Module 的,并且根据加载 Module 的顺序去按顺序查找和解析 UDF,先查到的先解析使用。
此外,Flink 只会解析已经启用了的 Module。那么当两个 Module 中出现两个同名的函数且都启用时, Flink 会根据加载 Module 的顺序进行解析,结果就是会使用顺序为第一个的 Module 的 UDF,可以使用下面语法更改顺序:
USE MODULE hive,core;
USE是启用module,没有被use的为禁用(禁用不是卸载),除此之外还可以实现调整顺序的效果。上面的语句会将 Hive Module 设为第一个使用及解析的 Module。
操作
到mvn中央仓库,下载flink-sql连接hive的jar包,下载地址
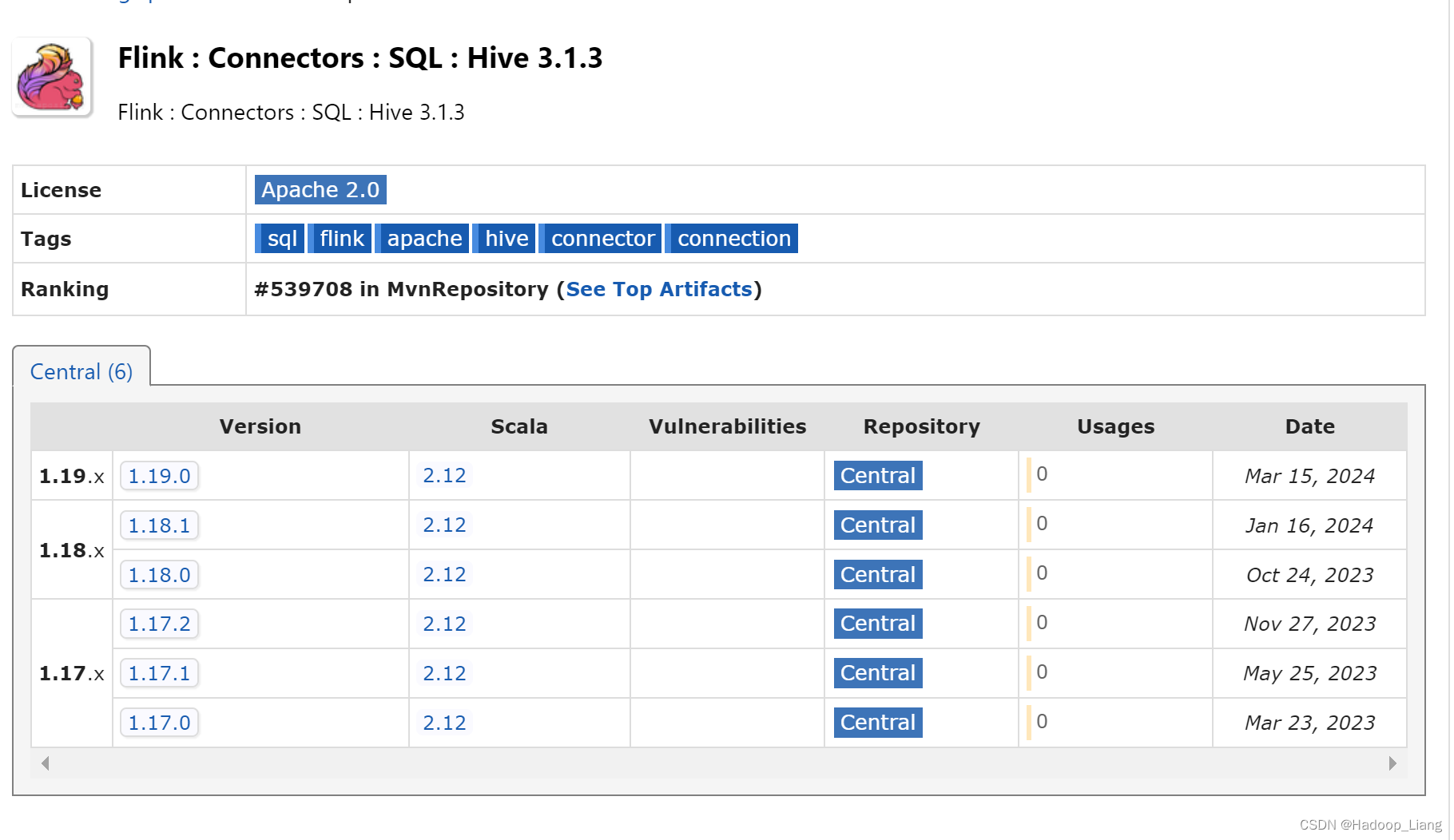
选择flink对应版本的下载,例如:1.17.1
(1)上传jar包到flink的lib中
上传hive connector
[hadoop@node2 ~]$ cp flink-sql-connector-hive-3.1.3_2.12-1.17.1.jar $FLINK_HOME/lib
注意:拷贝hadoop的包,解决依赖冲突问题
[hadoop@node2 ~]$ cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.3.jar $FLINK_HOME/lib
(2)重启flink集群和sql-client
关闭sql-client
Flink SQL> quit;
关闭flink集群(这里用的yarn session)
启动yarn session
[hadoop@node2 ~]$ yarn-session.sh -d
启动sql-client
[hadoop@node2 ~]$ sql-client.sh embedded -s yarn-session
(3)加载hive module
Flink SQL> load module hive with ('hive-version'='3.1.3'); [INFO] Execute statement succeed. Flink SQL> show modules; +-------------+ | module name | +-------------+ | core | | hive | +-------------+ 2 rows in set Flink SQL> show functions; 发现查到的函数数量变多了,说明加载到了hive的函数 测试使用hive的内置函数
select split('a:b', ':');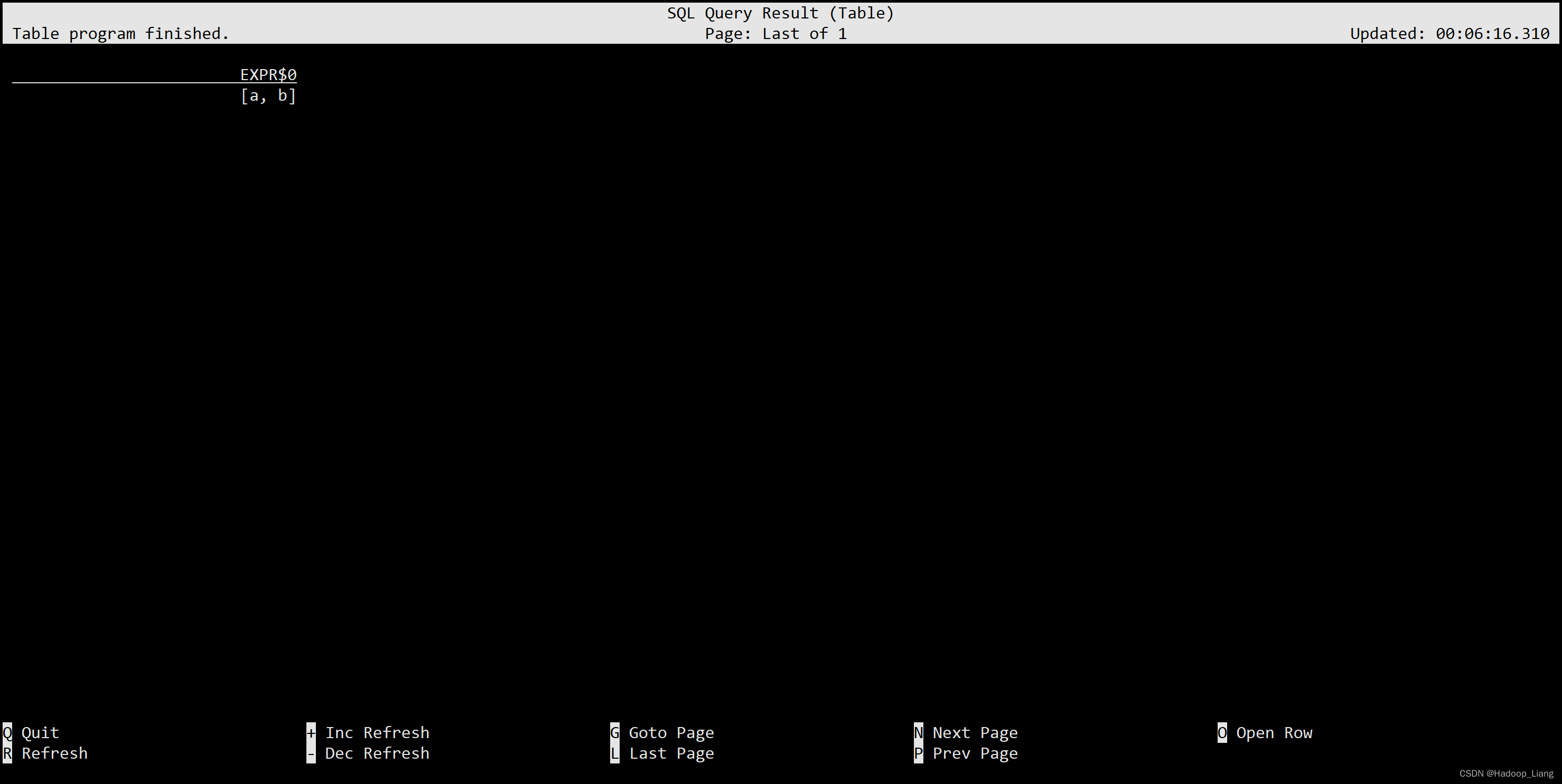
常用 Connector 读写
kafka
file
jdbc
代码中使用FlinkSQL
我们想要在代码中使用Table API,必须引入相关的依赖。
org.apache.flink flink-table-api-java-bridge${flink.version} 这里的依赖是一个Java的“桥接器”(bridge),主要就是负责Table API和下层DataStream API的连接支持,按照不同的语言分为Java版和Scala版。
如果我们希望在本地的集成开发环境(IDE)里运行Table API和SQL,还需要引入以下依赖:
org.apache.flink flink-table-planner-loader${flink.version} org.apache.flink flink-table-runtime${flink.version} org.apache.flink flink-connector-files${flink.version} 案例1
新建一个名为sql的包(package)来存放Flink SQL相关Java代码,代码所在的包,例如:org.example.sql
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import static org.apache.flink.table.api.Expressions.$; public class SqlDemo { public static void main(String[] args) { // 创建流执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 创建表环境 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 创建表 tableEnv.executeSql("CREATE TABLE source(\n" + "id INT, \n" + "ts BIGINT, \n"+ "vc INT\n"+ ")WITH(\n" + " 'connector' = 'datagen', \n" + " 'rows-per-second'='1', \n" + " 'fields.id.kind'='random', \n" + " 'fields.id.min'='1', \n" + " 'fields.id.max'='10', \n" + " 'fields.ts.kind'='sequence', \n" + " 'fields.ts.start'='1', \n" + " 'fields.ts.end'='1000000', \n" + " 'fields.vc.kind'='random', \n" + " 'fields.vc.min'='1', \n" + " 'fields.vc.max'='100'\n" + ");\n"); tableEnv.executeSql("CREATE TABLE sink (\n" + " id INT, \n" + " sumVC INT \n" + ") WITH (\n" + "'connector' = 'print'\n" + ");\n"); // 执行查询 // 1.使用sql查询 Table table = tableEnv.sqlQuery("select id, sum(vc) as sumVC from source where id>5 group by id;"); // 把table对象注册成表名 tableEnv.createTemporaryView("tmp", table); tableEnv.sqlQuery("select * from tmp where id>7"); // 2.使用table api查询 // Table source = tableEnv.from("source"); // Table result = source // .where($("id").isGreater(5)) // .groupBy($("id")) // .aggregate($("vc").sum().as("sumVC")) // .select($("id"), $("sumVC")); // 输出表 // sql写法 tableEnv.executeSql("insert into sink select * from tmp"); // table api写法 // result.executeInsert("sink"); } }在IDEA运行程序,部分运行结果如下
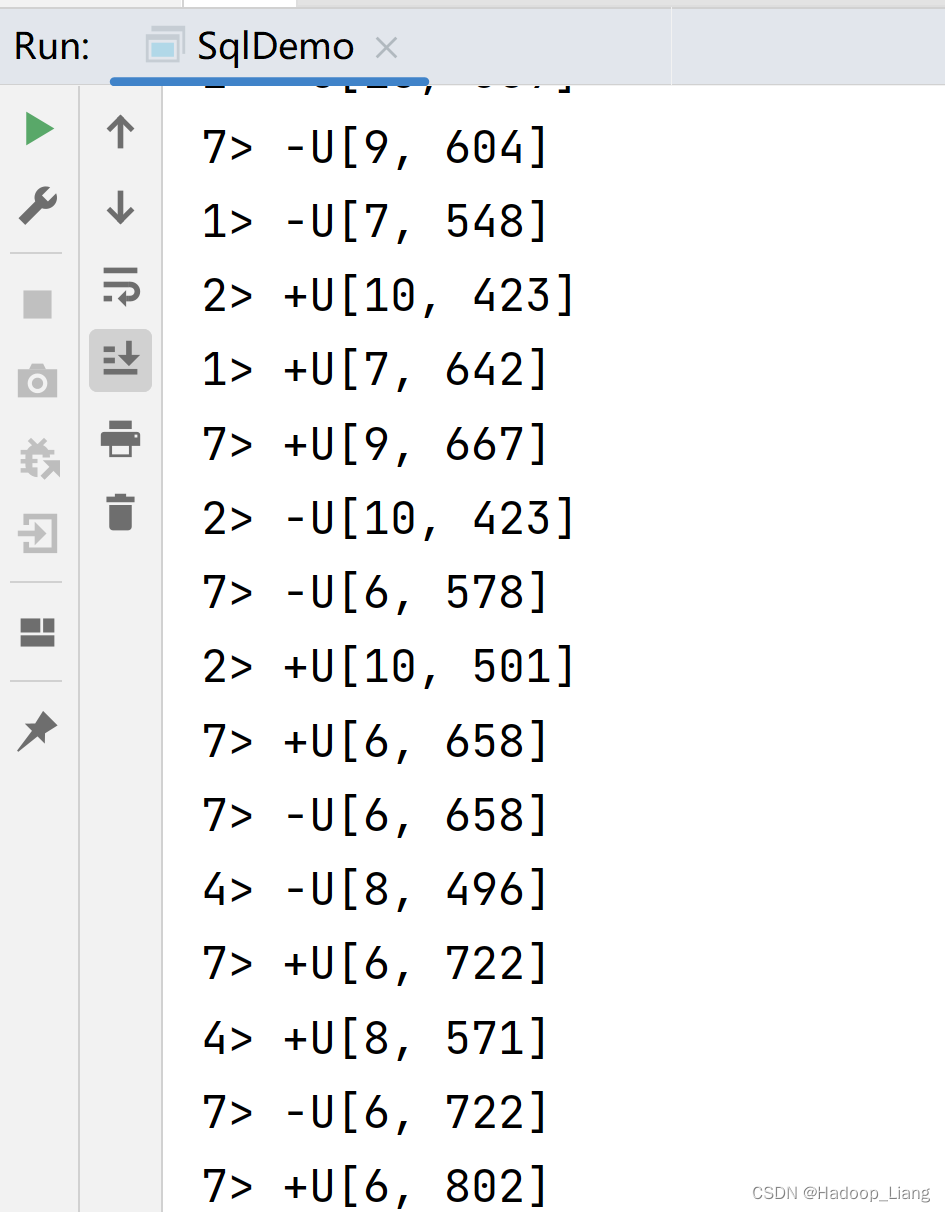
经过分析验证,发现输出结果是由tableEnv.executeSql("insert into sink select * from tmp")输出的。
案例2
import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.example.sgg.bean.WaterSensor; public class TableStreamDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSourcesensorDS = env.fromElements( new WaterSensor("s1", 1L, 1), new WaterSensor("s1", 2L, 2), new WaterSensor("s2", 2L, 2), new WaterSensor("s3", 3L, 3), new WaterSensor("s3", 4L, 4) ); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // TODO 1. 流转表 Table sensorTable = tableEnv.fromDataStream(sensorDS); tableEnv.createTemporaryView("sensor", sensorTable); Table filterTable = tableEnv.sqlQuery("select id,ts,vc from sensor where ts>2"); Table sumTable = tableEnv.sqlQuery("select id,sum(vc) from sensor group by id"); // TODO 2. 表转流 // 2.1 追加流 tableEnv.toDataStream(filterTable, WaterSensor.class).print("filter"); // 2.2 changelog流(结果需要更新) tableEnv.toChangelogStream(sumTable ).print("sum"); // 只要代码中调用了 DataStreamAPI,就需要 execute,否则不需要 env.execute(); } } 运行结果

案例3
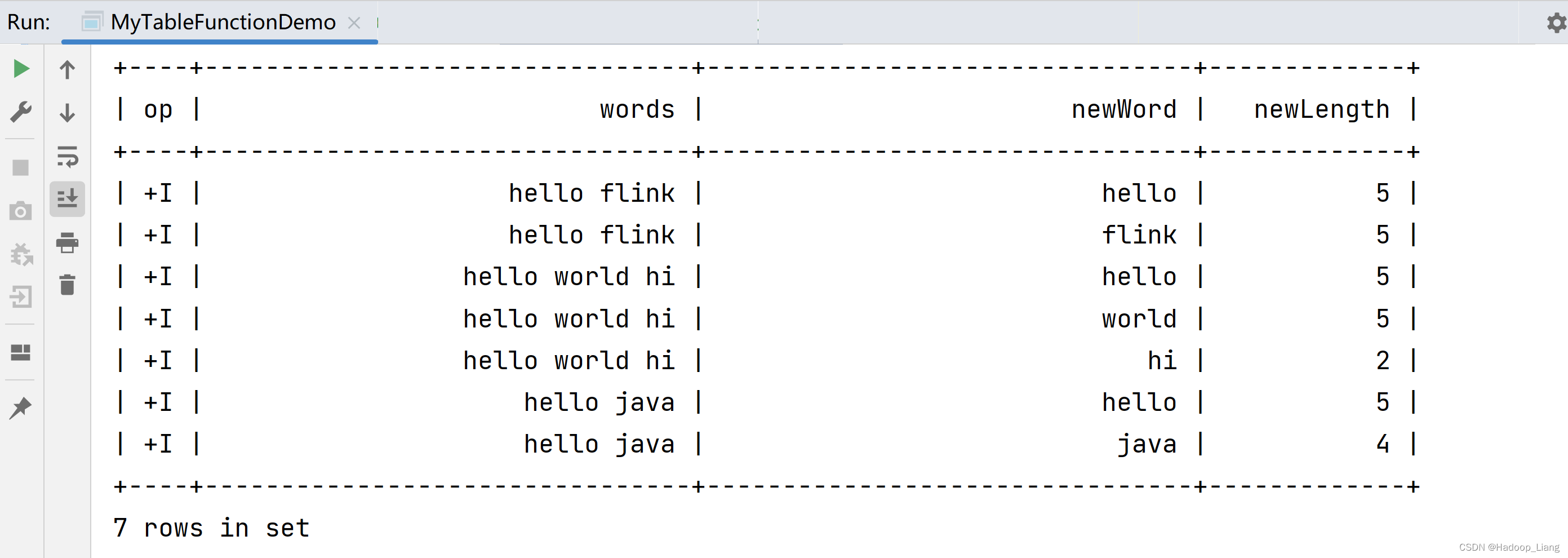
import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.annotation.DataTypeHint; import org.apache.flink.table.annotation.FunctionHint; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.table.functions.TableFunction; import org.apache.flink.types.Row; import static org.apache.flink.table.api.Expressions.$; public class MyTableFunctionDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSourcestrDS = env.fromElements( "hello flink", "hello world hi", "hello java" ); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); Table sensorTable = tableEnv.fromDataStream(strDS, $("words")); tableEnv.createTemporaryView("str", sensorTable); // TODO 2.注册函数 tableEnv.createTemporaryFunction("SplitFunction", SplitFunction.class); // TODO 3.调用 自定义函数 // 3.1 交叉联结 tableEnv // 3.1 交叉联结(笛卡尔积) // .sqlQuery("select words,word,length from str,lateral table(SplitFunction(words))") // 3.2 带 on true 条件的 左联结 // .sqlQuery("select words,word,length from str left join lateral table(SplitFunction(words)) on true") // 重命名侧向表中的字段 .sqlQuery("select words,newWord,newLength from str left join lateral table(SplitFunction(words)) as T(newWord,newLength) on true") .execute() .print(); } // TODO 1.继承 TableFunction<返回的类型> // 类型标注: Row包含两个字段:word和length @FunctionHint(output = @DataTypeHint("ROW ")) public static class SplitFunction extends TableFunction { // 返回是 void,用 collect方法输出 public void eval(String str) { for (String word : str.split(" ")) { collect(Row.of(word, word.length())); } } } }
运行结果
案例4
从学生的分数表ScoreTable中计算每个学生的加权平均分。
import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.table.functions.AggregateFunction; import static org.apache.flink.table.api.Expressions.$; public class MyAggregateFunctionDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 姓名,分数,权重 DataStreamSource运行结果

案例5
表聚合函数
用户自定义表聚合函数(UDTAGG)可以把一行或多行数据(也就是一个表)聚合成另一张表,结果表中可以有多行多列。很明显,这就像表函数和聚合函数的结合体,是一个“多对多”的转换。
import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.table.functions.TableAggregateFunction; import org.apache.flink.util.Collector; import static org.apache.flink.table.api.Expressions.$; import static org.apache.flink.table.api.Expressions.call; public class MyTableAggregateFunctionDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 姓名,分数,权重 DataStreamSourcenumDS = env.fromElements(3, 6, 12, 5, 8, 9, 4); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); Table numTable = tableEnv.fromDataStream(numDS, $("num")); // TODO 2.注册函数 tableEnv.createTemporaryFunction("Top2", Top2.class); // TODO 3.调用 自定义函数: 只能用 Table API numTable .flatAggregate(call("Top2", $("num")).as("value", "rank")) .select( $("value"), $("rank")) .execute().print(); } // TODO 1.继承 TableAggregateFunction< 返回类型,累加器类型<加权总和,权重总和> > // 返回类型 (数值,排名) =》 (12,1) (9,2) // 累加器类型 (第一大的数,第二大的数) ===》 (12,9) public static class Top2 extends TableAggregateFunction 运行结果
+----+-------------+-------------+ | op | value | rank | +----+-------------+-------------+ | +I | 3 | 1 | | -D | 3 | 1 | | +I | 6 | 1 | | +I | 3 | 2 | | -D | 6 | 1 | | -D | 3 | 2 | | +I | 12 | 1 | | +I | 6 | 2 | | -D | 12 | 1 | | -D | 6 | 2 | | +I | 12 | 1 | | +I | 6 | 2 | | -D | 12 | 1 | | -D | 6 | 2 | | +I | 12 | 1 | | +I | 8 | 2 | | -D | 12 | 1 | | -D | 8 | 2 | | +I | 12 | 1 | | +I | 9 | 2 | | -D | 12 | 1 | | -D | 9 | 2 | | +I | 12 | 1 | | +I | 9 | 2 | +----+-------------+-------------+ 24 rows in set
完成!enjoy it!
-
- 显示模式设置为changelog

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...