

文章目录
- 1 引言
- 2 项目背景
- 3 技术栈和工具选择
- 4 数据爬取
- 4.1 爬虫设计
- 4.2 代码实现
- 4.3 数据保存
- 4.4 关键点分析
- 5 数据处理与分析
- 5.1 数据清洗
- 5.2 数据分析
- 5.3 关键点分析
- 6 完整代码以及结果展示
- 7 小分享

1 引言
本文将指导你如何通过Python从高德地图爬取中国城市地铁站数据,并使用Pandas及Matplotlib进行数据分析和可视化。我们将深入探讨爬虫代码的设计与实现,着重讲解数据获取、处理和分析的关键步骤。从技术细节到实际应用,本文旨在提供一个实战示例,展示如何利用编程技能解锁城市地铁数据的潜力,为进一步的城市规划和交通管理研究提供数据支持。
2 项目背景
城市地铁作为公共交通的重要组成部分,其数据反映了城市的交通动脉和发展蓝图。随着数据分析技术的发展,从地铁数据中提取信息,不仅可以优化日常出行,还能为城市规划和公共资源分配提供决策支持。尽管如此,地铁数据通常不易直接获取,需要通过特定手段进行采集。
选择高德地图作为数据源,是因为它提供了详尽的城市地铁信息,包括站点名称、位置坐标等,适合进行此类分析。本项目通过编写Python爬虫,自动化地从高德地图API获取数据,然后利用Pandas进行数据清洗和整理,最终通过Matplotlib和Seaborn进行数据的可视化分析,旨在揭示城市地铁网络的基本特征和潜在价值。此过程不仅展示了数据科学在城市交通领域的应用,也提供了一个实用的技术示例,供同领域研究者或爱好者参考。
3 技术栈和工具选择
本项目的实现主要依赖于Python,一个在数据科学和自动化领域广泛应用的编程语言。Python凭借其强大的库支持和简洁的语法,成为本项目的首选。下面是项目中关键技术和工具的概览及选择理由:
- Requests库:用于发起HTTP请求。选择Requests是因为它简单易用,可以快速从网络上获取数据。
- Pandas库:负责数据处理和分析。Pandas提供了DataFrame对象,非常适合于处理表格数据,易于数据筛选、清洗和处理。
- Matplotlib和Seaborn库:用于数据可视化。这两个库能够生成高质量的图表,帮助我们从视觉上理解数据模式和趋势。
- JSON库:处理JSON数据格式。高德地图API返回的数据格式为JSON,使用Python内置的JSON库可以方便地解析这些数据。
4 数据爬取
为了分析城市地铁网络,首先需要从高德地图API获取相关数据。本部分将详细介绍爬虫的设计与实现过程,包括如何构造请求、解析数据,并将数据保存为可用格式。
4.1 爬虫设计
爬虫的核心任务是自动化地发送请求到高德地图的API,并处理返回的数据。高德地图提供了一个接口,通过城市的ID和名称可以返回该城市地铁的详细信息,包括站点名称、位置坐标等。
4.2 代码实现
使用Python的requests库发送HTTP GET请求,获取地铁数据。然后,利用json库解析这些数据。以下是一个简化的示例代码:
import requests import json import pandas as pd def get_metro_data(cityid, cityname): url = f'http://map.amap.com/service/subway?1469083453978&srhdata={cityid}_drw_{cityname}.json' response = requests.get(url) data = json.loads(response.text) # 解析数据 metro_info = [] for line in data['l']: for station in line['st']: metro_info.append({ '城市名称': data['s'][:-2], '线路名称': line['kn'], '站点名称': station['n'], '经度': float(station['sl'].split(',')[0]), '纬度': float(station['sl'].split(',')[1]) }) return pd.DataFrame(metro_info) # 示例:获取某城市地铁数据 df = get_metro_data('010', '北京') print(df.head())4.3 数据保存
获取的数据以DataFrame形式组织,并使用pandas的to_excel方法保存为Excel文件,方便后续分析。
df.to_excel('北京市地铁站数据.xls', index=False)4.4 关键点分析
- 请求构造:利用城市ID和名称构造请求URL,这是获取数据的关键步骤。
- 数据解析:解析返回的JSON数据,提取所需的站点信息。
- 数据存储:将解析后的数据保存为Excel文件,便于后续处理和分析。
5 数据处理与分析
拥有了原始的城市地铁数据后,下一步是通过数据处理和分析来揭示地铁网络的特征。这部分主要介绍如何使用Pandas进行数据清洗、处理,以及如何进行基础的数据分析。
5.1 数据清洗
首先,需要对爬取的数据进行清洗,确保数据的质量和可用性。主要步骤包括检查和处理缺失值、去重,以及数据类型转换:
import pandas as pd # 加载数据 df = pd.read_excel('地铁站数据.xls') # 检查缺失值 print(df.isnull().sum()) # 去除缺失值 df.dropna(inplace=True) # 去重 df.drop_duplicates(inplace=True) # 数据类型转换示例 # df['经度'] = df['经度'].astype(float) # df['纬度'] = df['纬度'].astype(float)5.2 数据分析
数据清洗后,我们可以开始对数据进行分析,以探索各城市地铁站的分布、地铁线路的数量等信息。以下是一些基本的数据分析示例:
# 统计每个城市的地铁站数量 station_count = df.groupby('城市名称')['站点名称'].count() # 统计每条线路的站点数量 line_station_count = df.groupby(['城市名称', '线路名称'])['站点名称'].count() print(station_count) print(line_station_count)5.3 关键点分析
- 数据清洗是数据分析的前提,确保了分析结果的准确性。
- 分组统计操作是Pandas中非常强大的功能,可以轻松实现对数据的聚合操作,为我们提供了地铁数据的多维度视角。
- 通过简单的统计和分组,我们能够快速获取到每个城市地铁站的数量和每条线路的站点数量等关键信息,为后续的深入分析打下基础。
6 完整代码以及结果展示
import requests import json import pandas as pd import requests import pandas as pd
def get_metro_data(cityid,cityname): url ='http://map.amap.com/service/subway?1469083453978&srhdata='+cityid+'_drw_'+cityname+'.json' response = requests.get(url) html = response.text hjson = json.loads(html) city = hjson['s'][:-2] #城市名称 cityid = hjson['i'] #城市编码 ln = [] #线路名称 ls = [] #线路编码 station = [] #站点名称 sid = [] #站点编码 lon = [] #经度 lat = [] #纬度 poiid = [] #POI编码 sp = [] #站点拼音 for i in range(len(hjson['l'])): for j in range(len(hjson['l'][i]['st'])): ln.append(hjson['l'][i]['kn']) ls.append(hjson['l'][i]['ls']) station.append(hjson['l'][i]['st'][j]['n']) sid.append(hjson['l'][i]['st'][j]['sid']) lon.append(float(hjson['l'][i]['st'][j]['sl'].split(',')[0])) lat.append(float(hjson['l'][i]['st'][j]['sl'].split(',')[1])) poiid.append(hjson['l'][i]['st'][j]['poiid']) sp.append(hjson['l'][i]['st'][j]['sp']) dict = {'城市名称':city, '城市编码':cityid, '线路名称':ln, '线路编码':ls, '站点名称':station, '站点编码':sid, '经度':lon, '纬度':lat, 'POI编码':poiid, '拼音':sp } df = pd.DataFrame(dict) df.to_excel(city + '地铁站数据.xls',index=False) print(city + '地铁数据已获取')f = open('metro.txt',encoding='utf-8') cityid = [] cityname = [] for line in f.readlines(): cityid.append(line.split()[1]) cityname.append(line.split()[2])metro.txt下载链接
print(cityname)

for i in range(len(cityid)): get_metro_data(cityid[i],cityname[i])
df = pd.read_excel('上海市地铁站数据.xls') df
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns # 步骤1: 加载数据 # 假设'上海市地铁站数据.xls'已经被替换为实际的文件路径 df = pd.read_excel('上海市地铁站数据.xls') # 步骤2: 数据清洗 # 检查数据中的缺失值 print(df.isnull().sum()) # 根据需要进行缺失值处理,这里假设简单地去除包含缺失值的行 df.dropna(inplace=True) # 步骤3: 数据分析 # 例如,计算每条线路的站点数量 stations_per_line = df.groupby('线路名称')['站点名称'].nunique().sort_values(ascending=False) # 步骤4: 数据可视化 # 配置Matplotlib以支持中文显示 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用于正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用于正常显示负号 plt.figure(figsize=(10, 8)) stations_per_line.plot(kind='bar') plt.title('各线路站点数量') plt.xlabel('线路名称') plt.ylabel('站点数量') plt.xticks(rotation=45) # 旋转X轴标签,以便更好地展示长名称 plt.tight_layout() plt.show()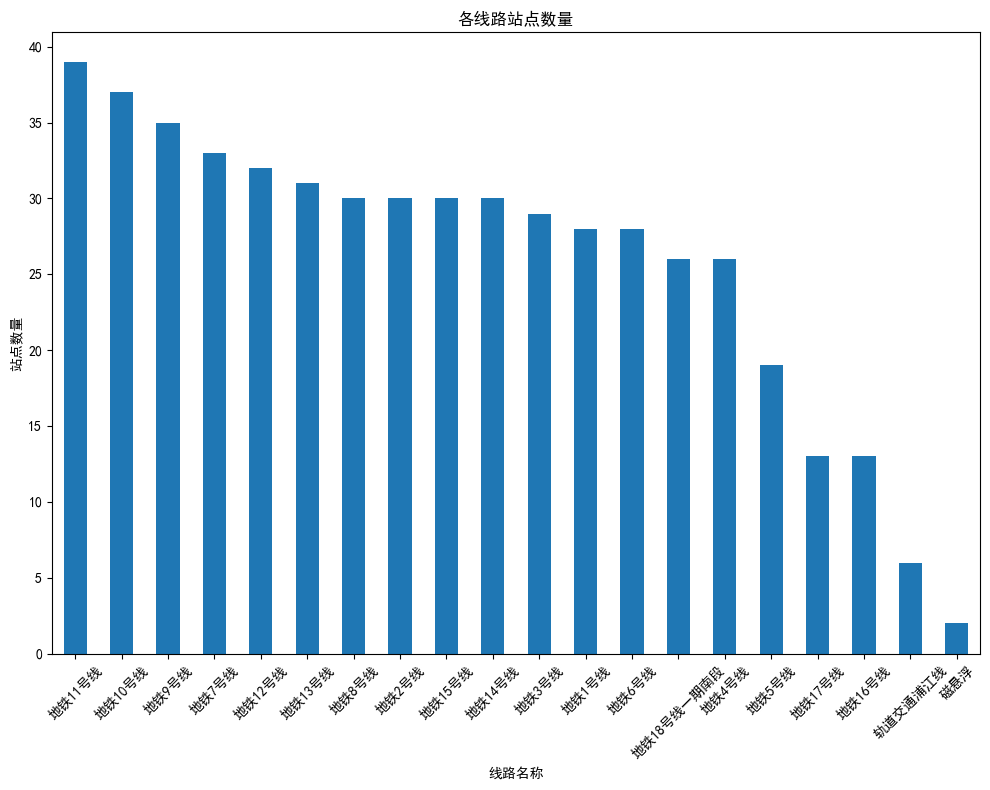
7 小分享



![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)





还没有评论,来说两句吧...