

MySQL的数据插入总结(不存在就插入,存在就更新)
1. on duplicate key update
当在insert语句后面带上ON DUPLICATE KEY UPDATE 子句,而要插入的行与表中现有记录的惟一索引或主键中产生重复值,那么就会发生旧行的更新;如果插入的行数据与现有表中记录的唯一索引或者主键不重复,则执行新纪录插入操作。
sql命令示例:
表名:test123,字段名:id, name, phone
.
.
情况1
初始表,name设定为唯一索引,表中存在2条数据:
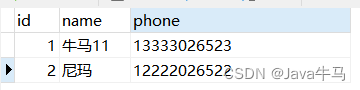
执行sql:
INSERT INTO `test123` (`id`,`name`,`phone`) VALUES (1,'牛马11','13333026523'), (3,'牛马11','144444026524') ON DUPLICATE KEY UPDATE `name` = "牛马22";
执行结果:
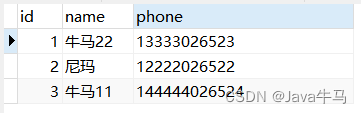
结论: 将数据库中已存在的第一条name重复的值修改为 “牛马22”,然后第三条正常插入;
.
.
情况2
初始表,name设定为唯一索引,表中存在1条数据:
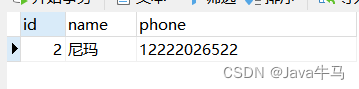
执行sql:
INSERT INTO `test123` (`id`,`name`,`phone`) VALUES (1,'牛马11','13333026523'), (3,'牛马11','144444026524') ON DUPLICATE KEY UPDATE `name` = "牛马22";
执行结果:

结论:sql命令中如果有唯一索引重复的数据,那么最终只会插入一条,并且 name = “牛马22”
.
.
总结 on duplicate key update:
-
数据表id是自动递增的不建议使用该语句;如果冲突数据比较多,新增的下一条id会相应跳跃的比较大。
-
有并发事务执行的insert 语句情况下不建议使用该语句,可能会导致产生死锁。
============================================================================================
2. insert ignore into
当插入数据时,如果数据存在,则忽略冲突的这行数据插入,其他插入正常执行;前提条件是插入的数据字段设置了主键或唯一索引;
sql命令示例:
表名:test123,字段名:id,name,phone
INSERT IGNORE INTO `test123` (`id`,`name`,`phone`) VALUES (1,'牛马','13333026523'), (2,'尼玛','12222026522');
============================================================================================
3. replace into
replace into 跟 insert into功能类似,不同点在于:replace into 首先尝试插入数据到表中,如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。否则,直接插入新数据。
注意,插入数据的表必须有主键或者是唯一索引!否则replace into 会直接插入数据,这将导致表中出现重复的数据。
replace into 的sql命令:
1. replace into table_name(col_name, …) values(…);
第1种形式类似于insert into的用法;
2. replace into table_name(col_name, …) select …;
第2种 replace select 的用法也类似于insert select,这种用法并不一定要求列名匹配,它需要的是列的位置。
例如,replace into table1( id, name, phone) select num, remark, phone_num from table2;
这个例子使用replace into从表table2中将所有数据导入到表table1中。
3. replace into table_name set col_name=value, …;
第3种replace set用法类似于update set用法,使用一个例如"SET col_name = col_name + 1"的赋值,则对位于右侧的列名称的引用会被作为DEFAULT(col_name)处理。因此,该赋值相当于SET col_name = DEFAULT(col_name) + 1。
============================================================================================
4. insert if not exists
即insert into … select … where not exist … ,这种方式适合于插入的数据字段没有设置主键或唯一索引,当插入一条数据时,首先判断MySQL数据库中是否存在这条数据,如果不存在,则正常插入,如果存在,则忽略。
sql语法示例:
INSERT INTO TABLE (field1, field2, fieldn) SELECT 'field1', 'field2', 'fieldn' FROM DUAL WHERE NOT EXISTS ( SELECT field FROM TABLE WHERE field = ? )详细可参考:insert if not exists 插入示例

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...