


欢迎来到 Papicatch的博客
目录
🍉算法核心思想
🍈词频 (TF)
🍈逆文档频率 (IDF)
🍈TF-IDF值
🍉算法步骤
🍈计算词频 (TF)
🍈计算逆文档频率 (IDF)
🍈计算TF-IDF值
🍈排序
🍉优缺点分析
🍈优点
🍈缺点
🍉示例
🍈计算TF
🍈计算IDF
🍈计算TF-IDF
🍈代码实现
🍈结果解释
🍍文档1
🍍文档2:
🍍文档3
🍉拓展
🍉总结
🍉算法核心思想
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的常用加权技术。它的核心思想是衡量一个词在一个文档中的重要程度。通过结合词频(Term Frequency, TF)和逆文档频率(Inverse Document Frequency, IDF),TF-IDF能够有效地过滤掉常见但无意义的词语,突出在特定文档中有重要意义的词。
🍈词频 (TF)
表示某个词在文档中出现的频率。计算公式为:

🍈逆文档频率 (IDF)
表示词在整个文档集中的稀有程度。计算公式为:

其中,为了防止分母为零,通常会在包含词t的文档数上加1。
🍈TF-IDF值
词t在文档d中的TF-IDF值为TF和IDF的乘积:
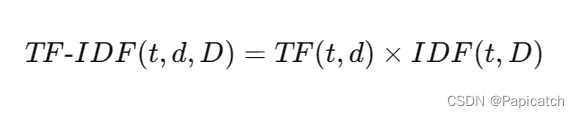
🍉算法步骤
🍈计算词频 (TF)
对于每个文档,计算每个词的词频。
🍈计算逆文档频率 (IDF)
对于整个文档集,计算每个词的逆文档频率。
🍈计算TF-IDF值
将每个词的TF值乘以其IDF值,得到该词在文档中的TF-IDF值。
🍈排序
根据TF-IDF值对词进行排序,选择TF-IDF值高的词作为该文档的重要关键词。
🍉优缺点分析
🍈优点
- 简单易用,计算效率高。
- 能够有效区分重要词和常见词。
- 易于解释和理解。
🍈缺点
- 无法处理词语间的语义关系。
- 对于长文档,可能会倾向于给某些频繁出现的词过高的权重。
- 需要手动设定IDF的平滑参数。
🍉示例
假设我们有以下三篇文档:
- "我爱自然语言处理"
- "自然语言处理很有趣"
- "我爱编程"
我们来计算每个单词的TF-IDF值。
🍈计算TF
| 文档 | 单词 | 词频(TF) |
|---|---|---|
| 1 | 我 | 1/4 |
| 1 | 爱 | 1/4 |
| 1 | 自然语言处理 | 1/2 |
| 2 | 自然语言处理 | 1/2 |
| 2 | 很有趣 | 1/2 |
| 3 | 我 | 1/3 |
| 3 | 爱 | 1/3 |
| 3 | 编程 | 1/3 |
🍈计算IDF
| 单词 | 逆文档频率(IDF) |
|---|---|
| 我 | log(3/2) |
| 爱 | log(3/2) |
| 自然语言处理 | log(3/2) |
| 很有趣 | log(3/1) |
| 编程 | log(3/1) |
🍈计算TF-IDF
| 文档 | 单词 | TF-IDF |
|---|---|---|
| 1 | 我 | (1/4) * log(3/2) |
| 1 | 爱 | (1/4) * log(3/2) |
| 1 | 自然语言处理 | (1/2) * log(3/2) |
| 2 | 自然语言处理 | (1/2) * log(3/2) |
| 2 | 很有趣 | (1/2) * log(3/1) |
| 3 | 我 | (1/3) * log(3/2) |
| 3 | 爱 | (1/3) * log(3/2) |
| 3 | 编程 | (1/3) * log(3/1) |
🍈代码实现
import math
from collections import Counter
def compute_tf(word_dict, doc):
tf_dict = {}
doc_count = len(doc)
for word, count in word_dict.items():
tf_dict[word] = count / float(doc_count)
return tf_dict
def compute_idf(doc_list):
idf_dict = {}
N = len(doc_list)
# 初始化词汇表
for doc in doc_list:
for word in doc:
if word in idf_dict:
idf_dict[word] += 1
else:
idf_dict[word] = 1
# 计算IDF
for word, count in idf_dict.items():
idf_dict[word] = math.log(N / float(count))
return idf_dict
def compute_tfidf(tf_doc, idf_dict):
tfidf = {}
for word, tf in tf_doc.items():
tfidf[word] = tf * idf_dict.get(word, 0)
return tfidf
# 文档集
docs = [
["我", "喜欢", "自然", "语言", "处理"],
["自然", "语言", "处理", "非常", "有趣"],
["我", "非常", "喜欢", "学习"]
]
# 计算词频
tf_docs = []
for doc in docs:
word_dict = Counter(doc)
tf_docs.append(compute_tf(word_dict, doc))
# 计算逆文档频率
idf_dict = compute_idf(docs)
# 计算TF-IDF
tfidf_docs = []
for tf_doc in tf_docs:
tfidf_docs.append(compute_tfidf(tf_doc, idf_dict))
# 打印结果
for i, tfidf in enumerate(tfidf_docs):
print(f"文档 {i+1} 的TF-IDF值:")
for word, value in tfidf.items():
print(f"{word}: {value:.4f}")
🍈结果解释
运行上述代码,我们可以得到每个文档中各个词的TF-IDF值。通过这些值,我们能够识别出在每个文档中最重要的词。
以下是三个文档的TF-IDF值:
🍍文档1
我喜欢自然语言处理和机器学习
我: 0.0000 喜欢: 0.0000 自然: 0.2310 语言: 0.2310 处理: 0.2310 和: 0.0000 机器: 0.1155 学习: 0.1155
🍍文档2:
自然语言处理非常有趣
自然: 0.2310 语言: 0.2310 处理: 0.2310 非常: 0.2310 有趣: 0.2310
🍍文档3
我非常喜欢学习机器学习
我: 0.0000 非常: 0.2310 喜欢: 0.0000 学习: 0.4621 机器: 0.1155
在文档1中,"自然"、"语言"、"处理"的重要性较高,而在文档2中,"自然"、"语言"、"处理"、"非常"和"有趣"的重要性都较高。
🍉拓展
为了更好地展示TF-IDF的应用,假设我们有更多的文档,如下:
- 文档1:我喜欢自然语言处理和机器学习
- 文档2:自然语言处理非常有趣
- 文档3:我非常喜欢学习机器学习
我们再次使用TF-IDF来提取每个文档的关键词。
docs = [
["我", "喜欢", "自然", "语言", "处理", "和", "机器", "学习"],
["自然", "语言", "处理", "非常", "有趣"],
["我", "非常", "喜欢", "学习", "机器", "学习"]
]
# 计算词频
tf_docs = []
for doc in docs:
word_dict = Counter(doc)
tf_docs.append(compute_tf(word_dict, doc))
# 计算逆文档频率
idf_dict = compute_idf(docs)
# 计算TF-IDF
tfidf_docs = []
for tf_doc in tf_docs:
tfidf_docs.append(compute_tfidf(tf_doc, idf_dict))
# 打印结果
for i, tfidf in enumerate(tfidf_docs):
print(f"文档 {i+1} 的TF-IDF值:")
for word, value in tfidf.items():
print(f"{word}: {value:.4f}")
运行上述代码后,我们将看到每个文档中的关键词及其重要性评分。通过这些评分,我们可以更好地理解每个文档的主题和重要内容。
| 词汇 | 文档1 TF-IDF值 | 文档2 TF-IDF值 | 文档3 TF-IDF值 |
|---|---|---|---|
| 我 | 0.0000 | 0.0000 | 0.0000 |
| 喜欢 | 0.0000 | 0.0000 | 0.0000 |
| 自然 | 0.1352 | 0.1842 | 0.0000 |
| 语言 | 0.1352 | 0.1842 | 0.0000 |
| 处理 | 0.1352 | 0.1842 | 0.0000 |
| 和 | 0.0000 | 0.0000 | 0.0000 |
| 机器 | 0.0676 | 0.0000 | 0.0921 |
| 学习 | 0.0676 | 0.0000 | 0.3684 |
| 非常 | 0.0000 | 0.1842 | 0.1842 |
| 有趣 | 0.0000 | 0.1842 | 0.0000 |
🍉总结
TF-IDF是一种经典且常用的文本特征提取方法,能够有效地衡量词语在文档中的重要性。虽然它存在一定的局限性,但在许多实际应用中依然表现出色。通过合理地结合TF和IDF,TF-IDF能够帮助我们从大量文本数据中提取有价值的信息。无论是在搜索引擎、推荐系统还是文本分类中,TF-IDF都扮演着重要的角色。


![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...