

Hadoop 高可用集群完全分布式安装教程一篇就够用(zookeeper、spark、hbase、mysql、hive)
写在之前,Hadoop完全分布式集群资源配置规划情况

一、全局基本配置
💡 建议一开始安装的时候在网络配置项的地方,选择自动ipv4,然后进行ip设置1、更改静态网络
命令如下:
# 检查虚拟机是否能够ping通www.baidu.com service network restart # 尝试重启网络服务 # 修改网络服务为静态网络 指定路由以及DNS服务器 vim /etc/sysconfig/network-scripts/ifcfg-ens33
文件内容如下:
TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO="static" DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=c494a46e-a55b-431a-9b5e-b2bbdc767606 DEVICE=ens33 ONBOOT=yes IPADDR=192.168.201.201# 虚拟机对应的ip地址 NETMASK=255.255.255.0 # 子网掩码 GATEWAY=192.168.201.2# 网关地址 DNS1=114.114.114.114 # DNS服务器地址
然后重启网络:
service network restart
再次测试 网络是否能够正常联通
ping www.baidu.com
2、关闭防火墙
#关闭防火墙 systemctl stop firewalld #禁用防火墙 systemctl disable firewalld #查看防火墙状态 systemctl status firewalld
3、配置主机名(方便后期Hadoop集群服务)
#给3台虚拟机设置主机名分别为hadoop01、hadoop02和hadoop03。 #在第一台机器操作 hostnamectl set-hostname hadoop01 #在第二台机器操作 hostnamectl set-hostname hadoop02 #在第三台机器操作 hostnamectl set-hostname hadoop03
设置完毕后在ssh工具处刷新即可
4、编辑hosts头文件(Linux)
vi /etc/hosts # 编辑hosts文件 # 在最后一行添加 192.168.201.201 hadoop01 192.168.201.202 hadoop02 192.168.201.203 hadoop03
5、编辑hosts头文件(windows)
# 在Windows中打开C:\Windows\System32\drivers\etc路径,在hosts文件中添加如下内容: 192.168.201.201 hadoop01 192.168.201.202 hadoop02 192.168.201.203 hadoop03
6、ssh免密登录
# 每一个机器都需要这样操作 ssh-keygen -b 1024 -t rsa cd .ssh ssh-copy-id hadoop01 ssh-copy-id hadoop02 ssh-copy-id hadoop03
7、编写集群分发脚本
# 需要在用户目录下新建一个bin文件夹,然后存放集群分发脚本xsync # 为什么要新建bin文件夹的原因 执行 echo $PATH 查看系统环境路径 能够全局执行 # /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin mkdir /root/bin vim xsync chmod 777 xsync # 如果报错 # bash: rsync: command not found # rsync: connection unexpectedly closed (0 bytes received so far) [sender] # rsync error: remote command not found (code 127) at io.c(226) [sender=3.1.2] # 下载 rsync 即可 因为作者使用的从机使用的是最小化安装版本 因此需要额外安装rsync yum -y install rsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop01 hadoop02 hadoop03
do
echo -e "\n==================== $host ===================="
#3. 遍历所有目录,逐个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exist!
fi
done
done
echo -e "\n"
8、编写集群查看jps进行脚本
cd ~/bin
vim jpsall
#!/bin/bash
for host in hadoop01 hadoop02 hadoop03
do
echo -e "\n=============== $host ==============="
ssh $host "export JAVA_HOME=/opt/module/jdk1.8.0_391 && export PATH=\$JAVA_HOME/bin:\$PATH && jps"
done
echo -e "\n"
# 保存 给文件赋予执行权限
chmod 777 jpsall
二、jdk安装配置
# 解压 tar -zxvf jdk-8u391-linux-x64.tar.gz -C /opt/module/ # 设置环境变量 vim /etc/profile #在末尾追加环境变量 export JAVA_HOME=/opt/module/jdk1.8.0_391 export PATH=$JAVA_HOME/bin:$PATH # 使用集群分发命令 将 环境变量 分发至其他从机 xsync /etc/profile # 激活环境变量 source /etc/profile [root@hadoop03 module]# java -version java version "1.8.0_391" Java(TM) SE Runtime Environment (build 1.8.0_391-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.391-b13, mixed mode)
三、zookeeper安装配置
zookeeper集群 搭建
# 解压 tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/ cd /opt/module/ mv apache-zookeeper-3.7.1-bin/ zookeeper-3.7.1 cd zookeeper-3.7.1/conf/ #zk配置文件是 zoo.cfg ,创建并配置 mv zoo_sample.cfg zoo.cfg vim zoo.cfg # 修改 dataDir=/opt/module/zookeeper-3.7.1/data # 添加 对应主机名的id识别全局端口 server.1=hadoop01:2888:3888 server.2=hadoop02:2888:3888 server.3=hadoop03:2888:3888
💡 说明:在zookeeper 集群中有三种角色:Leader、Follower 和 Observer,但在同一时刻只会有一个 Leader,其他都是 Follower 或 Observer。
cd .. # 创建存放数据的文件夹 mkdir data # 创建myid编号 echo 1 > data/myid
💡 说明:对于zooKeeper集群来说,每个节点都需要配置一个唯一的myid。确保每个节点都能被正确地识别和识别为集群的一部分。
# 配置zookeeper环境变量 vim /etc/profile export ZOOKEEPER_HOME=/opt/module/zookeeper-3.7.1 export PATH=$PATH:$ZOOKEEPER_HOME/bin # 使用集群分发命令 将 环境变量 分发至其他从机 xsync /etc/profile # 激活环境变量 source /etc/profile # 使用集群分发命令 将 zookeeper 分发至其他从机 xsync /opt/module/zookeeper-3.7.1 # 分别修改 hadoop02 和 hadoop03 的 myid 编号 [root@hadoop02 module]# echo 2 > /opt/module/zookeeper-3.7.1/data/myid [root@hadoop03 module]# echo 3 > /opt/module/zookeeper-3.7.1/data/myid #所有节点启动,需要在每个节点执行 zkServer.sh start
zookeeper集群 启动命令
# 编写脚本对zookeeper集群实现批量启动,停止,重启
# 在 用户目录下的 bin 文件下 创建集群启动文件
cd /root/bin/
vim zkserver
#!/bin/bash
echo "$1 zkServer ..."
for i in {hadoop02,hadoop01,hadoop03}
do
ssh $i "source /etc/profile && zkServer.sh $1"
done
# 给文件赋予权限
chmod 777 zkserver

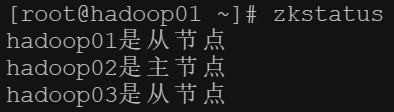
zookeeper集群 状态检查命令
# 通过编写脚本实现批量检查
vim zkstatus
#!/bin/bash
for host in {hadoop02,hadoop01,hadoop03}
do
status=$(ssh $host 'source /etc/profile && zkServer.sh status 2>&1 | grep Mode')
if [[ $status == "Mode: follower" ]];then
echo "$host是从节点"
elif [[ $status == "Mode: leader" ]];then
echo "$host是主节点"
else
echo "未查询到$host节点zookeeper状态,请检查服务"
fi
done
# 给文件赋予权限
chmod 777 zkstatus
四、hadoop搭建集群
主机环境配置
cd /opt/software/ tar -zxvf hadoop-3.3.5.tar.gz -C /opt/module/ # 配置 hadoop 环境变量 vim /etc/profile export HADOOP_HOME=/opt/module/hadoop-3.3.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # 激活环境变量 source /etc/profile [root@hadoop01 software]# hadoop version Hadoop 3.3.5 Source code repository https://github.com/apache/hadoop.git -r 706d88266abcee09ed78fbaa0ad5f74d818ab0e9 Compiled by stevel on 2023-03-15T15:56Z Compiled with protoc 3.7.1 From source with checksum 6bbd9afcf4838a0eb12a5f189e9bd7
编辑hadoop hdfs核心配置文件
编辑主机workers文件
vim workers #填入从机名 hadoop01 hadoop02 hadoop03
修改core-site.xml文件
vim core-site.xmlfs.defaultFS hdfs://mycluster hadoop.tmp.dir /data/hadoop/tmp ha.zookeeper.quorum hadoop01:2181,hadoop02:2181,hadoop03:2181 ipc.client.connect.max.retries 100 ipc.client.connect.retry.interval 10000 io.file.buffer.size 65536
配置hdfs-site.xml文件
vim hdfs-site.xmldfs.nameservices mycluster dfs.ha.namenodes.mycluster nn1,nn2 dfs.namenode.rpc-address.mycluster.nn1 hadoop01:9000 dfs.namenode.http-address.mycluster.nn1 hadoop01:50070 dfs.namenode.rpc-address.mycluster.nn2 hadoop02:9000 dfs.namenode.http-address.mycluster.nn2 hadoop02:50070 dfs.namenode.name.dir /data/hadoop/hdfs/namenode namenode上存储hdfs命名空间元数据 dfs.datanode.data.dir /data/hadoop/hdfs/datanode datanode上数据块的物理存储位置 dfs.replication 3 副本个数,默认是3,应小于datanode数量 dfs.webhdfs.enabled true dfs.permissions.enabled false dfs.datanode.max.transfer.threads 4096 dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_rsa dfs.ha.automatic-failover.enabled true dfs.namenode.shared.edits.dir qjournal://hadoop01:8485;hadoop02:8485/mycluster dfs.journalnode.edits.dir /data/hadoop/hdfs/ha/jn
修改hadoop-env.sh文件
vim hadoop-env.sh #修改JAVA_HOME的路径 export JAVA_HOME=/opt/module/jdk1.8.0_391
设置hdfs集群启动时,允许root用户启动
vim /etc/profile #设置hdfs集群启动时,允许root用户启动 HDFS_NAMENODE_USER=root export HDFS_NAMENODE_USER HDFS_DATANODE_USER=root export HDFS_DATANODE_USER HDFS_JOURNALNODE_USER=root export HDFS_JOURNALNODE_USER HDFS_ZKFC_USER=root export HDFS_ZKFC_USER # 激活环境变量 source /etc/profile
启动hadoop hdfs系统
# 使用集群分发命令 将 hadoop 以及 环境变量 分发至其他从机 xsync /opt/module/hadoop-3.3.5 xsync /etc/profile # 激活环境变量 source /etc/profile #启动JN,格式化之前要优先启动JN,现在是两个nn,要通过JN传递数据。 [root@hadoop01 ~]# hdfs --daemon start journalnode [root@hadoop02 ~]# hdfs --daemon start journalnode # 由于没有事先创建logs文件夹,因此会自动创建 # WARNING: /opt/module/hadoop-3.3.5/logs does not exist. Creating. # 格式化NN,将hadoop01作为主节点 [root@hadoop01 ~]# hdfs namenode -format # 格式化NameNode会在指定的NameNode数据目录中创建一个名为current的子目录,用于存储NameNode的元数据和命名空间信息 [root@hadoop01 ~]# ll /data/hadoop/hdfs/namenode/ total 0 drwx------. 2 root root 112 Nov 28 04:26 current # hadoop02上的nn作为主备,在hadoop02执行拷贝元数据之前,需要先启动hadoop01上的namanode [root@hadoop01 ~]# hdfs --daemon start namenode # 拷贝元数据,在Hadoop HDFS中初始化一个备用的NameNode节点。当主要的NameNode节点出现故障时,备用的NameNode节点就可以快速启动并接管服务,而无需重新加载整个文件系统的元数据,提供高可用性。 # 注意在hadoop02上执行 [root@hadoop02 ~]# hdfs namenode -bootstrapStandby
在hadoop02上,执行元数据复制
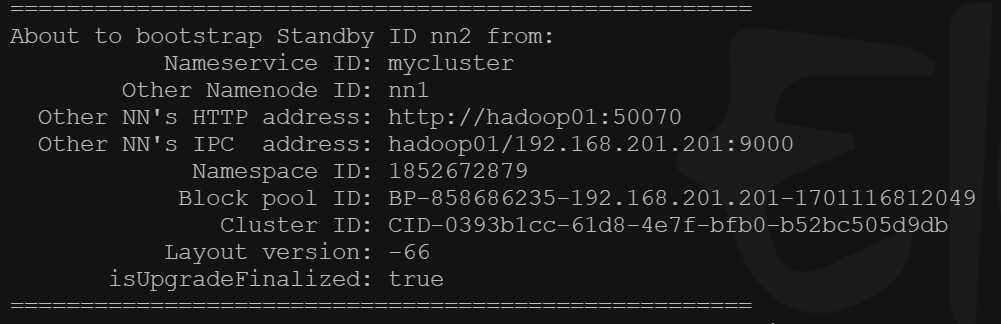
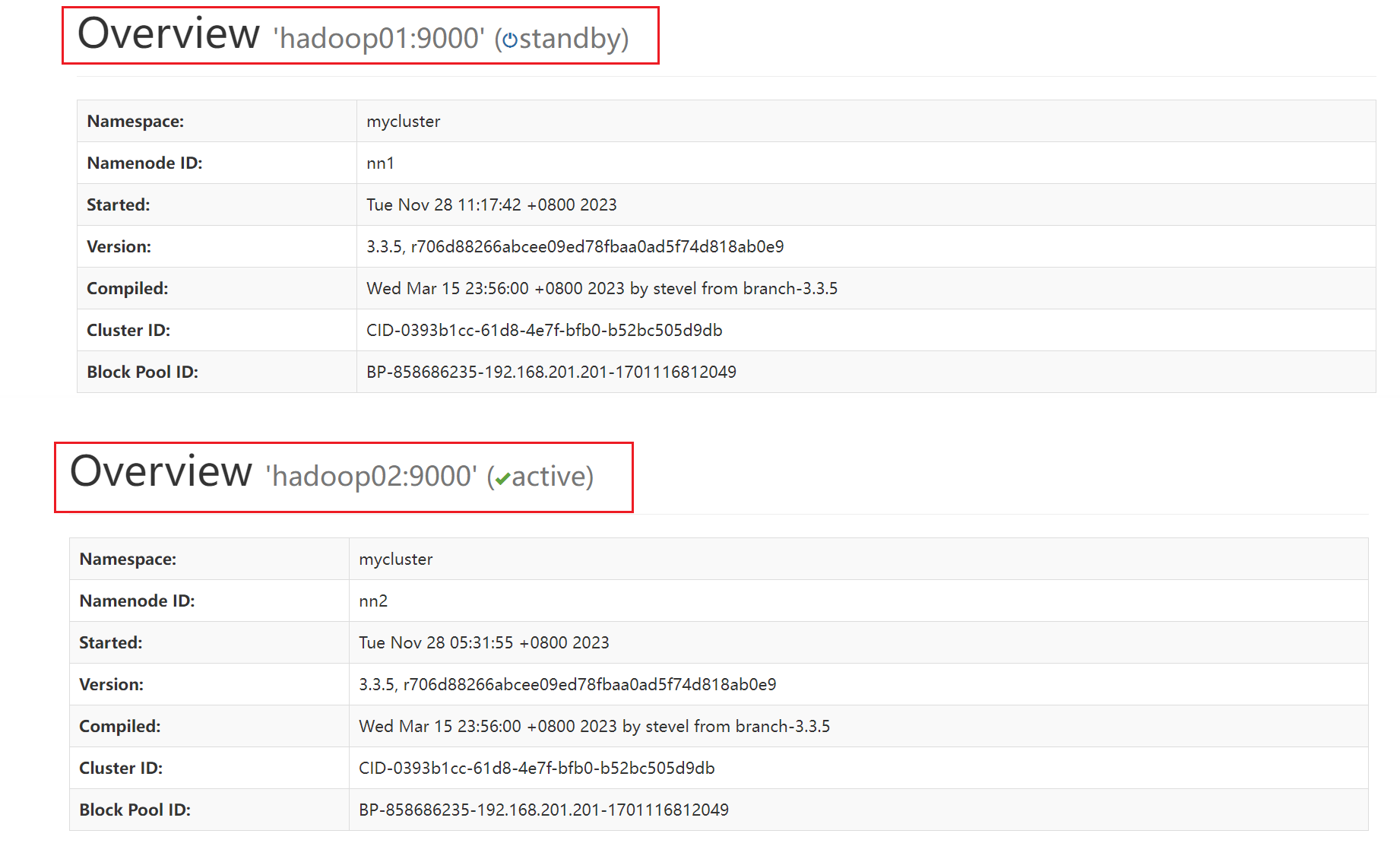
# 启动hadoop02上的namenode [root@hadoop02 ~]# hdfs --daemon start namenode # 格式化zk,用于监控和管理Hadoop HDFS中的主备NameNode节点切换的组件。此命令会创建一个ZooKeeper目录结构,并将初始的主备NameNode节点信息存储在ZooKeeper中。这样,ZKFC就可以使用ZooKeeper来进行主备节点的管理和切换。 # 在设置Hadoop HDFS的高可用性环境时,需要先使用hdfs namenode -bootstrapStandby命令初始化备用的NameNode节点,然后使用hdfs zkfc -formatZK 命令初始化ZKFC。这两个命令的组合可以确保Hadoop HDFS的主备节点切换的可靠性和高可用性。 [root@hadoop01 ~]# hdfs zkfc -formatZK # 注意 执行上述步骤前,需要先开启zookeeper集群服务!!! # 启动zk客户端 [root@hadoop01 ~]# zkCli.sh # 可以通过ls查看目录结构 [zk: localhost:2181(CONNECTED) 5] ls / [hadoop-ha, zookeeper] # quit 退出客户端 # 启动 datanode 或者使用下面用集群命令 start-dfs.sh 一键启动所有服务 [root@hadoop01 ~]# hdfs --daemon start datanode # 注意:以后启动 hdfs 就只需要先启动 zookeeper,然后执行 start-dfs.sh 就可以了 # 启动 zookeeper 只需要 执行 zkserver start 即可 [root@hadoop01 ~]# start-dfs.sh Starting namenodes on [hadoop01 hadoop02] Last login: Tue Nov 28 11:16:37 CST 2023 from 192.168.201.1 on pts/0 Starting datanodes Last login: Tue Nov 28 11:17:31 CST 2023 on pts/0 Starting journal nodes [hadoop02 hadoop01] Last login: Tue Nov 28 11:17:34 CST 2023 on pts/0 Starting ZK Failover Controllers on NN hosts [hadoop01 hadoop02] Last login: Tue Nov 28 11:18:02 CST 2023 on pts/0 # 验证高可用 [root@hadoop01 ~]# hdfs haadmin -getServiceState nn1 active [root@hadoop01 ~]# hdfs haadmin -getServiceState nn2 standby # 如果两台都是standby,可以通过 hdfs haadmin -transitionToActive --forcemanual nn1 命令强制将nn1转换为为active # 访问页面验证 # 到浏览器访问,hadoop01:50070 (192.168.201.201:50070) 和 (hadoop01:50070) 192.168.201.202:50070 验证 # 如果出现主从节点状态不正常的情况,执行以下命令 [root@hadoop01 ~]# hdfs haadmin -failover nn2 nn1 Failover to NameNode at hadoop01/192.168.201.201:9000 successful
编辑hadoop yarn核心配置文件
编辑mapred-site.xml文件
[root@hadoop01 ~]# cd /opt/module/hadoop-3.3.5/etc/hadoop/ vim mapred-site.xml # 添加以下配置mapreduce.framework.name yarn 指定mapreduce使用yarn框架
编辑yarn-site.xml文件
vim yarn-site.xml# 这里是在文件包着的里面写入内容 !!! yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.ha.enabled true 是否开启高可用 yarn.resourcemanager.cluster-id yrc yarn.resourcemanager.ha.rm-ids rm1,rm2 yarn.resourcemanager.hostname.rm1 hadoop01 yarn.resourcemanager.hostname.rm2 hadoop02 yarn.resourcemanager.address.rm1 hadoop01:8032 yarn.resourcemanager.address.rm2 hadoop02:8032 yarn.resourcemanager.scheduler.address.rm1 hadoop01:8030 yarn.resourcemanager.scheduler.address.rm2 hadoop02:8030 yarn.resourcemanager.resource-tracker.address.rm1 hadoop01:8031 yarn.resourcemanager.resource-tracker.address.rm2 hadoop02:8031 yarn.resourcemanager.zk-address hadoop01:2181,hadoop02:2181,hadoop03:2181 yarn.resourcemanager.recovery.enabled true yarn.resourcemanager.store.class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLAS SPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
设置yarn集群启动时,允许root用户启动
vim /etc/profile #允许root用户启动yarn集群服务 YARN_RESOURCEMANAGER_USER=root export YARN_RESOURCEMANAGER_USER YARN_NODEMANAGER_USER=root export YARN_NODEMANAGER_USER # 激活环境变量 source /etc/profile # 集群分发 修改后的hadoop文件 xsync hadoop-3.3.5/ # 集群分发 环境变量 xsync /etc/profile [root@hadoop01 ~]# start-yarn.sh Starting resourcemanagers on [ hadoop01 hadoop02] Last login: Tue Nov 28 13:42:30 CST 2023 on pts/0 Starting nodemanagers Last login: Tue Nov 28 13:45:56 CST 2023 on pts/0 [root@hadoop01 ~]# jps 20018 DataNode 19443 NodeManager 20501 DFSZKFailoverController 20294 JournalNode 19865 NameNode 19274 ResourceManager 18798 QuorumPeerMain 20814 Jps # 产生这样的原因 可能是一开始 启动zookeeper服务时导致,hadoop01不是主节点(已修改) [root@hadoop01 module]# yarn rmadmin -getServiceState rm1 standby [root@hadoop01 module]# yarn rmadmin -getServiceState rm2 active #如果某些原因yarn没有启动成功,可以单独启动 yarn-daemon.sh start resourcemanager
集群启动 推荐方式 (分步启动 可能导致主节点出现问题)
# 先启动 zookeeper 同步服务 zkserver start # 然后直接启动hadoop集群 start-all.sh [root@hadoop01 ~]# zkserver start start zkServer ... ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.7.1/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.7.1/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.7.1/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@hadoop01 ~]# start-all.sh Starting namenodes on [hadoop01 hadoop02] Last login: Tue Nov 28 14:45:58 CST 2023 from 192.168.201.1 on pts/0 Starting datanodes Last login: Tue Nov 28 14:47:02 CST 2023 on pts/0 Starting journal nodes [hadoop02 hadoop01] Last login: Tue Nov 28 14:47:05 CST 2023 on pts/0 Starting ZK Failover Controllers on NN hosts [hadoop01 hadoop02] Last login: Tue Nov 28 14:47:11 CST 2023 on pts/0 Starting resourcemanagers on [ hadoop01 hadoop02] Last login: Tue Nov 28 14:47:16 CST 2023 on pts/0 Starting nodemanagers Last login: Tue Nov 28 14:47:23 CST 2023 on pts/0 [root@hadoop01 ~]# jps 3779 ResourceManager 4195 Jps 3941 NodeManager 2390 QuorumPeerMain 2663 NameNode 3113 JournalNode 2827 DataNode 3340 DFSZKFailoverController
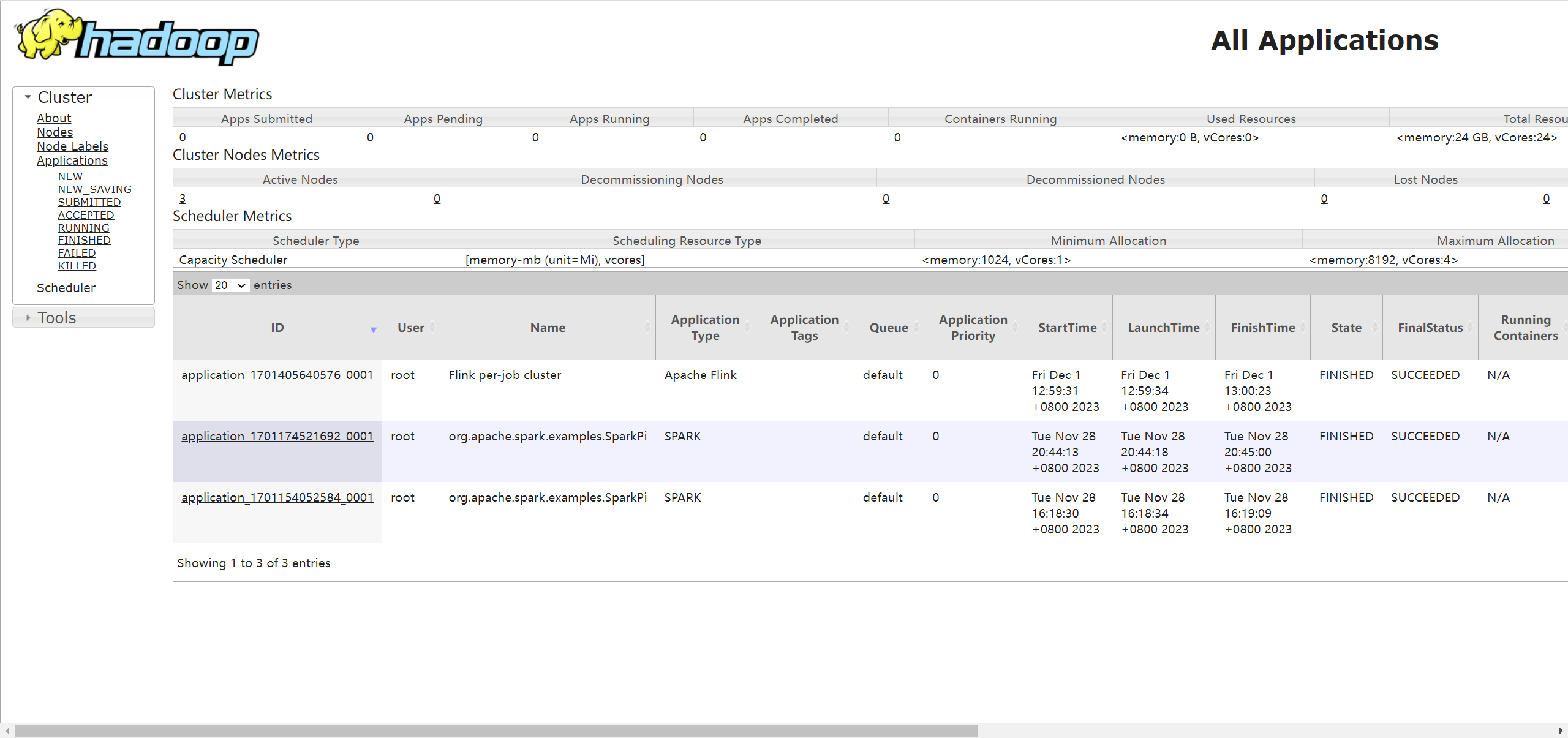
启动查看命令 : hadoop01:8088 hadoop01:50070
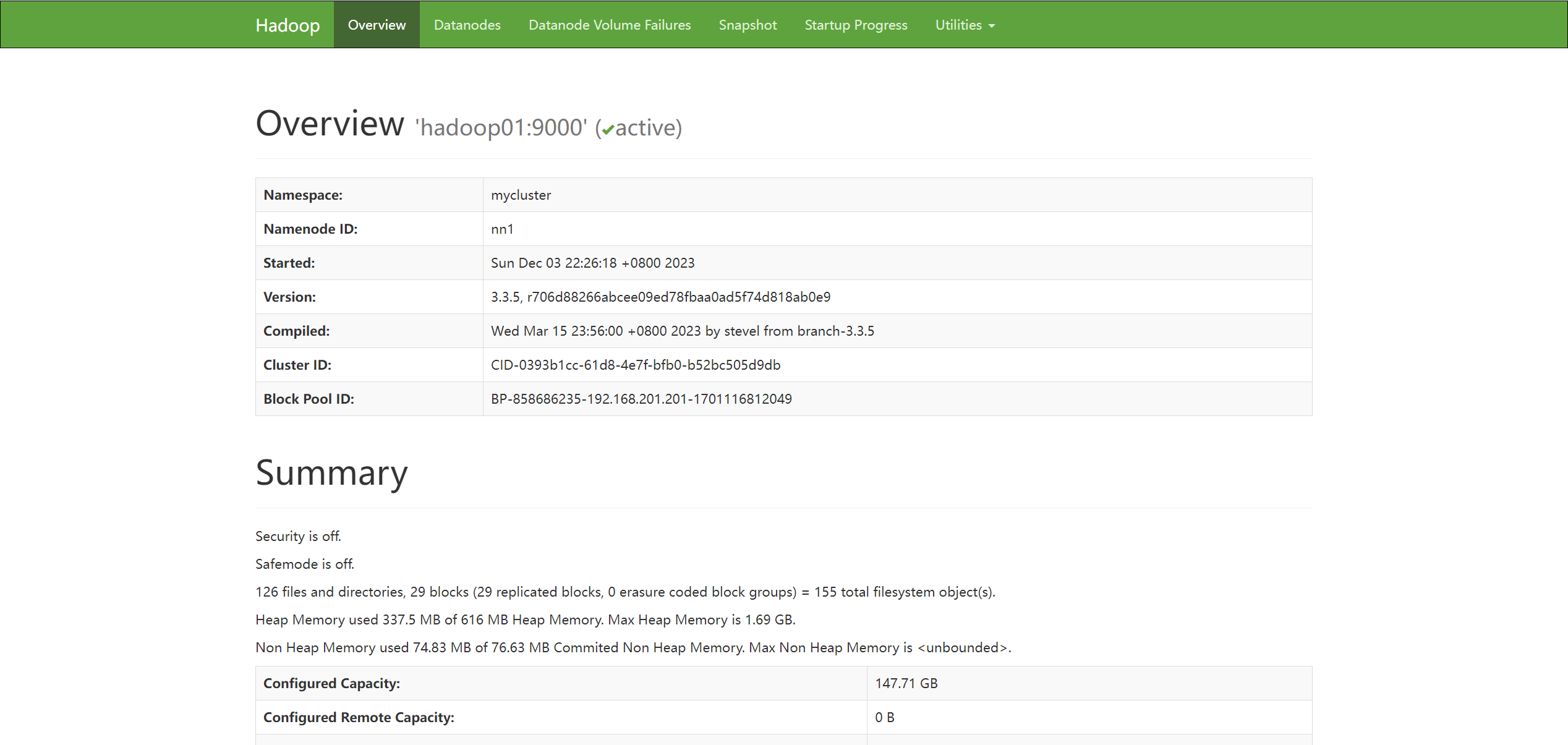
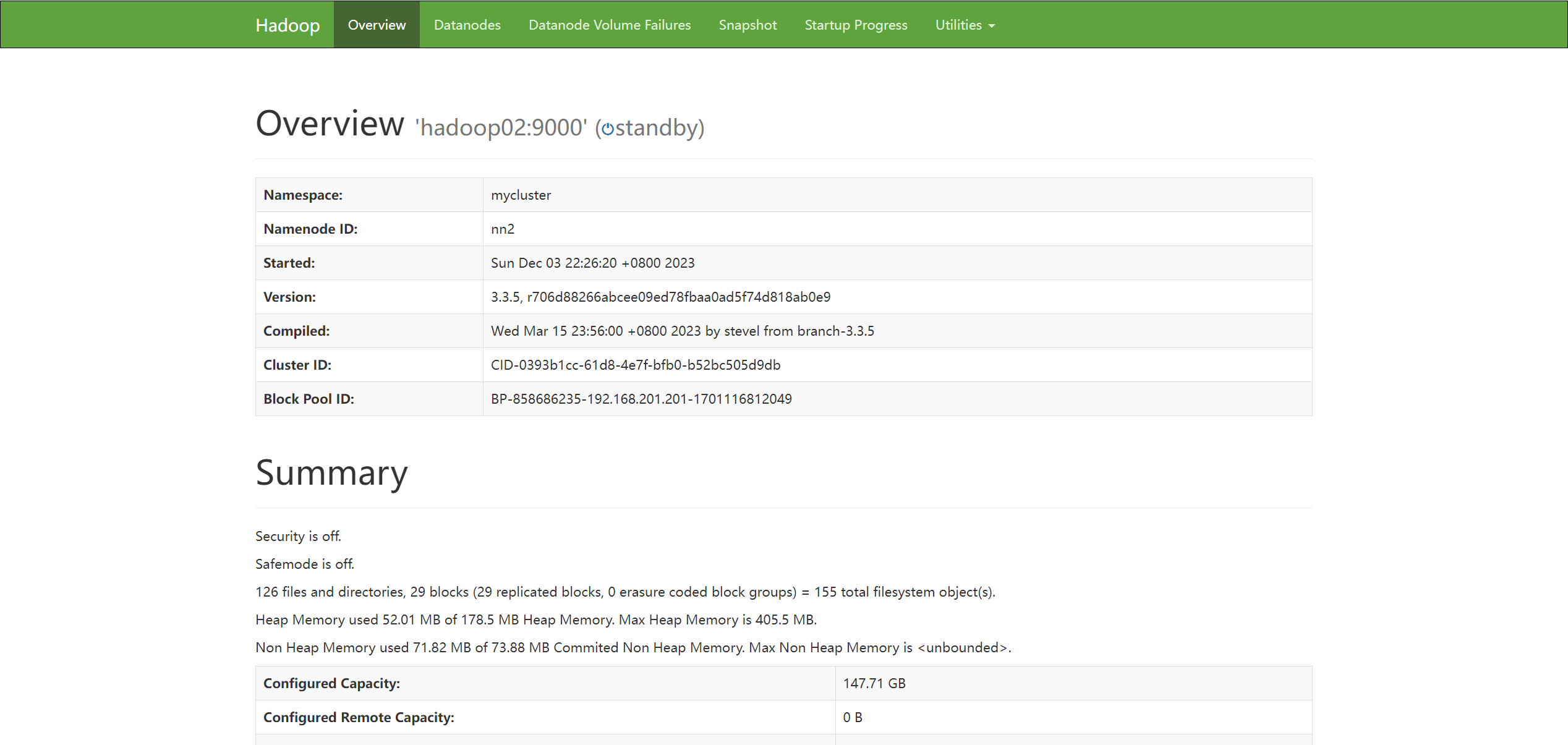
至此hadoop ha 高可用集群已搭建完毕,可以尝试进行中断任一节点的服务,然后刷新web浏览器,即可查看状态进行切换为active状态,检测完后可以重新开启
kill -9 2663 (namenode 节点对应的 进程id) # 在浏览器上多刷新几次 并且打开 hadoop02:50070 查看状态 # 重新开启 namenode 节点 hdfs --daemon start namenode
hadoop01:50070
hadoop02:50070
hadoop01:8088 (输入hadoop02:8088 时,会切换至hadoop01:8088)
因为 ha 机制 同时刻 只允许一个 yarn 服务状态为active ,否则会出现 脑裂 (split-brain)
五、spark集群搭建
主机环境配置
cd /opt/software/ tar -zxvf spark-3.2.4-bin-hadoop3.2-scala2.13.tgz -C /opt/module/ cd /opt/module mv spark-3.2.4-bin-hadoop3.2-scala2.13/ spark-3.2.4/ # 配置 spark 环境变量 vim /etc/profile export SPARK_HOME=/opt/module/spark-3.2.4 export PATH=$PATH:$SPARK_HOME/bin # 激活环境变量 source /etc/profile
配置spark 核心文件
编辑 spark-env.sh 文件
cd /opt/module/spark-3.2.4/conf/ mv spark-env.sh.template spark-env.sh vim spark-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_391 export HADOOP_CONF_DIR=/opt/module/hadoop-3.3.5/etc/hadoop/ export YARN_CONF_DIR=/opt/module/hadoop-3.3.5/etc/hadoop/ export SPARK_MASTER_IP=hadoop01 export SPARK_MASTER_PORT=7077 export SPARK_MASTER_WEBUI_PORT=8090 export SPARK_WORKER_WEBUI_PORT=8091 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zookeeper.dir=/opt/module/zookeeper-3.7.1"💡 说明: JAVA_HOEM:设置Java安装目录的路径 HADOOP_CONF_DIR:设置Hadoop的配置目录路径 YARN_CONF_DIR:设置YARN的配置目录路径,YARN是Hadoop的资源管理器 SPARK_MASTER_IP:设置Spark主节点的IP地址或主机名。Spark主节点负责协调集群中的各个工作节点。 SPARK_MASTER_PORT:设置Spark主节点的端口号。通过该端口,工作节点可以与Spark主节点进行通信。 SPARK_MASTER_WEBUI_PORT:设置Spark主节点的Web界面端口号。可以通过该端口访问Spark主节点的Web界面。 SPARK_WORKER_WEBUI_PORT:设置Spark工作节点的Web界面端口号。可以通过该端口访问Spark工作节点的Web界面。
编辑 workers 文件
mv workers.template workers vim workers # 修改为以下内容 hadoop01 hadoop02 hadoop03
spark 集群 测试
启动 spark 测试
# 将 hadoop 相关配置文件 复制到 spark cd /opt/module/hadoop-3.3.5/etc/hadoop cp core-site.xml hdfs-site.xml /opt/module/spark-3.2.4/conf/ # 同步 spark 文件目录 xsync /opt/module/spark-3.2.4 # 同步 环境变量 xsync /etc/profile #在 hadoop02 上配置备用 master 节点 [root@hadoop02 ~]# vim /opt/module/spark-3.2.4/conf/spark-env.sh #将 export SPARK_MASTER_IP=hadoop01 改为 export SPARK_MASTER_IP=hadoop02 # 没有 vim 编辑器 需要使用 yum 下载 yum install -y vim #由于启动命令和hadoop下的命令文件名一样,我们需要cd到spark目录下执行 [root@hadoop01 ~]# cd /opt/module/spark-3.2.4/sbin [root@hadoop01 sbin]# ./start-all.sh
[root@hadoop01 sbin]# jps 3779 ResourceManager 3941 NodeManager 2390 QuorumPeerMain 7078 Worker 2663 NameNode 6952 Master 3113 JournalNode 2827 DataNode 3340 DFSZKFailoverController 7245 Jps # 在 hadoop02 上 开启 备用 Master 节点 [root@hadoop02 ~]# cd /opt/module/spark-3.2.4/sbin [root@hadoop02 sbin]# ./start-master.sh #jps查看hadoop01 和 hadoop02 上都有Master,hadoop03节点有Worker
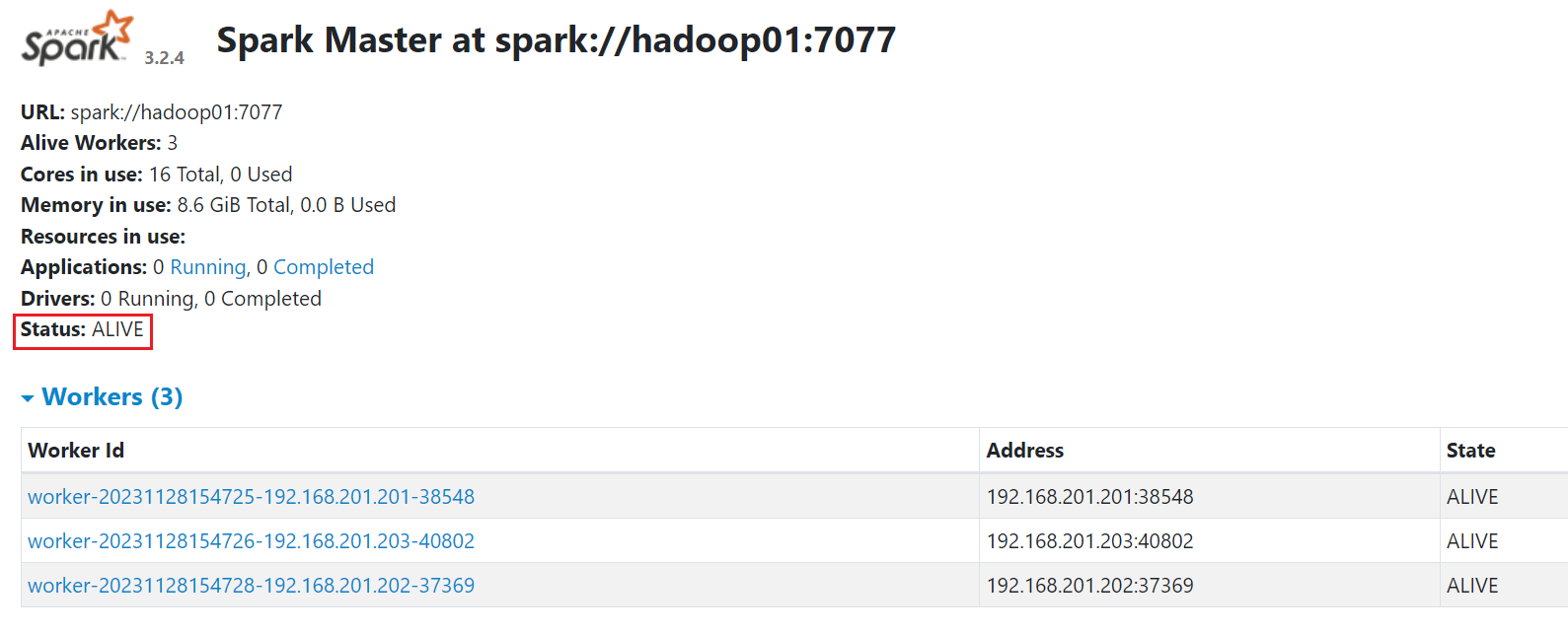
浏览器访问 hadoop01:8090 可以看到上面状态 Status: ALIVE
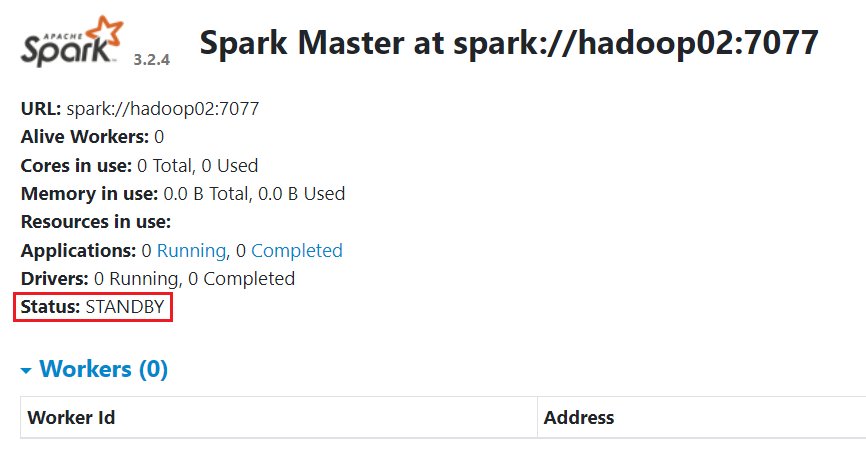
浏览器访问 hadoop02:8090 可以看到上面状态 Status: STANDBY
中断 master 切换测试
# 强制中断 Master 服务 [root@hadoop01 sbin]# jps 3779 ResourceManager 3941 NodeManager 7445 Jps 2390 QuorumPeerMain 7078 Worker 2663 NameNode 6952 Master 3113 JournalNode 2827 DataNode 3340 DFSZKFailoverController [root@hadoop01 sbin]# kill -9 6952
刷新页面,hadoop01:8090 已经访问不到了,我们在访问 hadoop02:8090时,多刷新几次,可以看到 master 已经切换到hadoop02
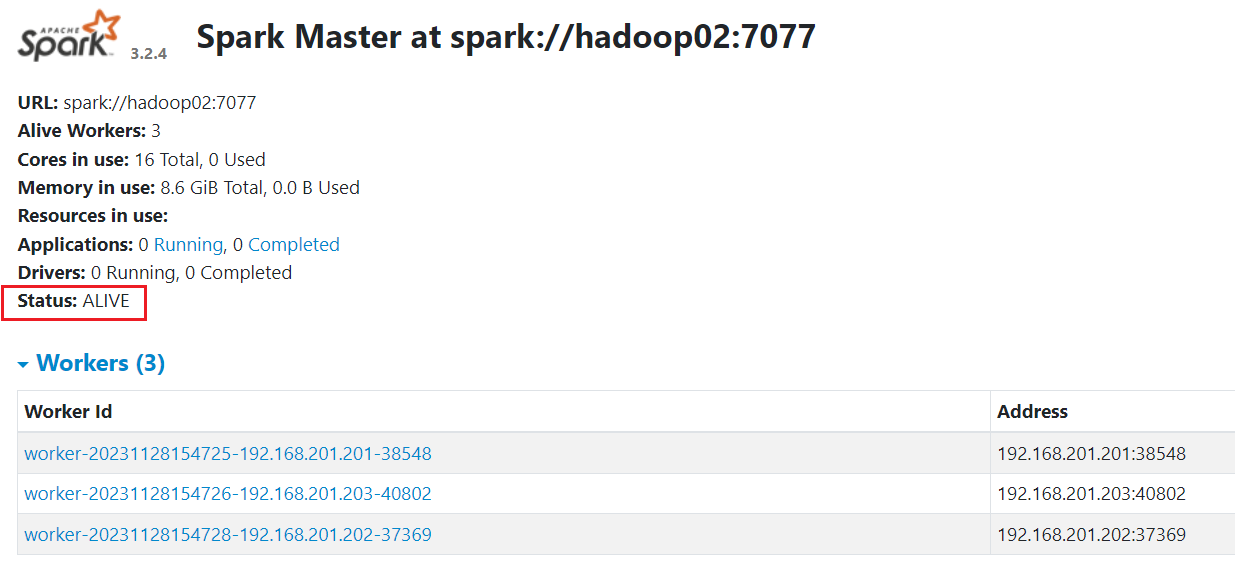
# 在 hadoop01 上 重新启动 Master 服务 ./start-master.sh # 然后 重新执行 开启 hadoop02 上的 备用 Master 进程 # 此时 发现 hadoop01 上的 状态回到了 active 状态, 而 hadoop02 为 standby 状态
启动 spark 计算服务测试
# 使用 spark 计算 pi [root@hadoop01 sbin]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/module/spark-3.2.4/examples/jars/spark-examples_2.13-3.2.4.jar
- 代码解释:
- spark-submit: 是用于提交 Spark 应用程序的命令行工具。
- –class org.apache.spark.examples.SparkPi: 指定要运行的 Spark 应用程序的主类,这里是 SparkPi 示例应用程序。这是一个计算 π 值的简单 Spark 应用程序。
- –master yarn: 指定 Spark 应用程序运行的主节点(master)。在这里,yarn 表示使用 YARN 作为集群管理器。
- –deploy-mode cluster: 指定 Spark 应用程序的部署模式,cluster 表示在集群上运行。在这种模式下,驱动程序(Driver)会在集群中的某个节点上启动,而不是在提交命令的本地机器上启动。
- /opt/module/spark-3.2.4/examples/jars/spark-examples_2.13-3.2.4.jar : 这是 Spark 应用程序的 JAR 文件的路径,其中包含了 Spark 应用程序的代码和依赖。在这里,SparkPi 示例的 JAR 文件路径。
- 完整解释是 使用 spark-submit 提交一个 Spark 应用程序,这个应用程序的主类是 org.apache.spark.examples.SparkPi,在 YARN 集群上以 cluster 模式运行,其代码和依赖位于 /opt/module/spark-3.2.4/examples/jars/spark-examples_2.13-3.2.4.jar 这个 JAR 文件中。
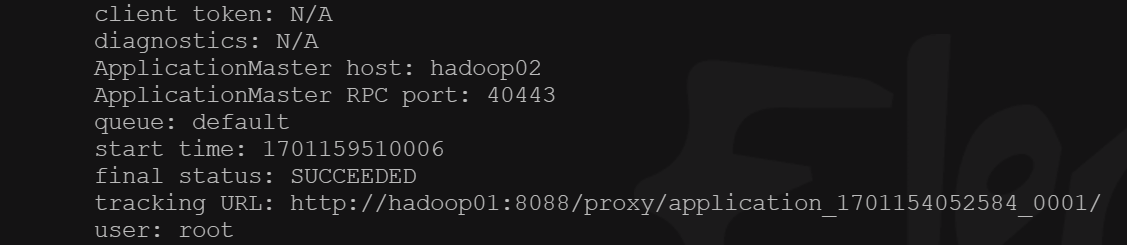
# 可以在 hadoop01:8088 上查看 运行状态 以及 日志信息 等
配置 yarn 历史服务器
配置hadoop mapred-site.xml
cd /opt/module/hadoop-3.3.5/etc/hadoop/ vim mapred-site.xml # 添加以下配置项mapreduce.jobhistory.address hadoop01:10020 mapreduce.jobhistory.webapp.address hadoop01:19888 配置hadoop yarn-site.xml
vim yarn-site.xml # 添加以下配置项yarn.log-aggregation-enable true yarn.log.server.url http://hadoop01:19888/jobhistory/logs/ yarn.log-aggregation.retain-seconds 86400 同步文件到其他主机 以及 spark 配置中
# 同步至其他主机的 hadoop 文件目录中 [root@hadoop01 hadoop]# xsync mapred-site.xml yarn-site.xml # 复制文件 并 同步至 其他主机的 spark 文件目录中 [root@hadoop01 hadoop]# cp mapred-site.xml yarn-site.xml /opt/module/spark-3.2.4/conf/ [root@hadoop01 hadoop]# xsync /opt/module/spark-3.2.4/conf/
配置 spark 历史服务器
配置 spark spark-defaults.conf文件
cd /opt/module/spark-3.2.4/conf/ [root@hadoop01 conf]# mv spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf # 添加或者放开注释并修改 spark.eventLog.enabled true spark.eventLog.compress true spark.eventLog.dir hdfs://mycluster/spark-logs spark.yarn.historyServer.address hadoop01:18080,hadoop02:18080 spark.history.ui.port 18080 spark.history.fs.logDirectory hdfs://mycluster/spark-logs spark.history.retainedApplications 30
- 文件说明:
- spark.eventLog.enabled 设置为 true 表示启用Spark事件日志记录功能。
- spark.eventLog.compress 指定Spark事件日志是否需要进行压缩
- spark.eventLog.dir 指定了事件日志的存储路径
- spark.yarn.historyServer.address 指定了YARN历史服务器的地址
- spark.history.ui.port 指定了Spark历史服务器UI的端口号
- spark.history.fs.logDirectory 指定了历史记录文件在文件系统中的存储路径
- spark.history.retainedApplications 指定了历史服务器要保留的应用程序数量,设置为 30,表示历史服务器将保留最近提交的30个应用程序的历史记录。
同步文件到其他主机
# 同步至 其他主机的 spark 文件目录中 [root@hadoop01 conf]# xsync spark-defaults.conf # 删除 其他主机的 spark-defaults.conf文件 [root@hadoop02 ~]# rm -rf /opt/module/spark-3.2.4/conf/spark-defaults.conf.template
重新开启集群测试
#创建时间日志的存储路径,需要在启动历史服务器之前创建,不然报错找不到路径或文件 [root@hadoop01 sbin]# hdfs dfs -mkdir /spark-logs # hadoop01 上执行 zkserver start start-all.sh mapred --daemon start historyserver $SPARK_HOME/sbin/start-all.sh $SPARK_HOME/sbin/start-history-server.sh # hadoop02 上执行 $SPARK_HOME/sbin/start-master.sh $SPARK_HOME/sbin/start-history-server.sh
hadoop01:18080

hadoop01:19888 (logs 日志 在 hadoop01:8088 页面点击 logs 跳转)
hadoop01:19888
💡 如果 出现 类似 这样的问题 http://hadoop01:8088/proxy/application_1701174521692_0001/ 点击之后 ,报错的 是因为 那个日志 是通过代理 到 对应的 集群上 保存的 proxy 就是代理的原因,在spark 的history 日志里面 有相关的日志 http://hadoop01:18080/history/application_1701174521692_0001/1/jobs/
六、hbase集群搭建
主机环境配置
cd /opt/software/ tar -zxvf hbase-2.4.17-bin.tar.gz -C /opt/module/ cd /opt/module/ # 配置 hbase 环境变量 vim /etc/profile # HBase环境变量 export HBASE_HOME=/opt/module/hbase-2.4.17 export PATH=$PATH:$HBASE_HOME/bin # 激活环境变量 source /etc/profile
配置hbase 核心文件
配置hbase-env.sh 文件
cd /opt/module/hbase-2.4.17/conf/ vim hbase-env.sh # 修改以下内容 export JAVA_HOME=/opt/module/jdk1.8.0_391 #保存pid文件 export HBASE_PID_DIR=/opt/module/hbase-2.4.17/pids #禁用HBase自带的Zookeeper,因为我们是使用独立的Zookeeper export HBASE_MANAGES_ZK=false
配置hbase-site.xml 文件
vim hbase-site.xml # 将原有的配置信息 进行删除 添加以下配置项
hbase.rootdir hdfs://mycluster/hbase hbase.master.info.port 60010 hbase.cluster.distributed true hbase.zookeeper.quorum hadoop01:2181,hadoop02:2181,hadoop03:2181 hbase.zookeeper.property.dataDir /opt/module/zookeeper-3.7.1/data hbase.zookeeper.property.clientPort 2181 hbase.tmp.dir /opt/module/hbase-2.4.17/tmp hbase.unsafe.stream.capability.enforce false hbase.wal.provider filesystem 配置regionservers 文件
vim regionservers # 修改为 以下信息 hadoop01 hadoop02 hadoop03
复制配置文件
# 复制 hadoop 配置到 hbase 目录下 cd /opt/module/hadoop-3.3.5/etc/hadoop/ cp core-site.xml hdfs-site.xml /opt/module/hbase-2.4.17/conf/ # 将 hbase 文件 同步到其他主机 cd /opt/module xsync hbase-2.4.17/ xsync /etc/profile # 分别在 hadoop02 和 hadoop03 上 执行以下代码 激活环境变量 source /etc/profile
启动hbase集群
# 查看那个是主节点 (hadoop01 还是 hadoop02) 然后执行 集群启动命令 [root@hadoop01 module]# hdfs haadmin -getServiceState nn1 active [root@hadoop01 module]# start-hbase.sh # 然后在另外一个备份节点上执行 hbase-daemon.sh start master
查看集群web界面 : master : hadoop01:60010 backup master **** : hadoop02:60010
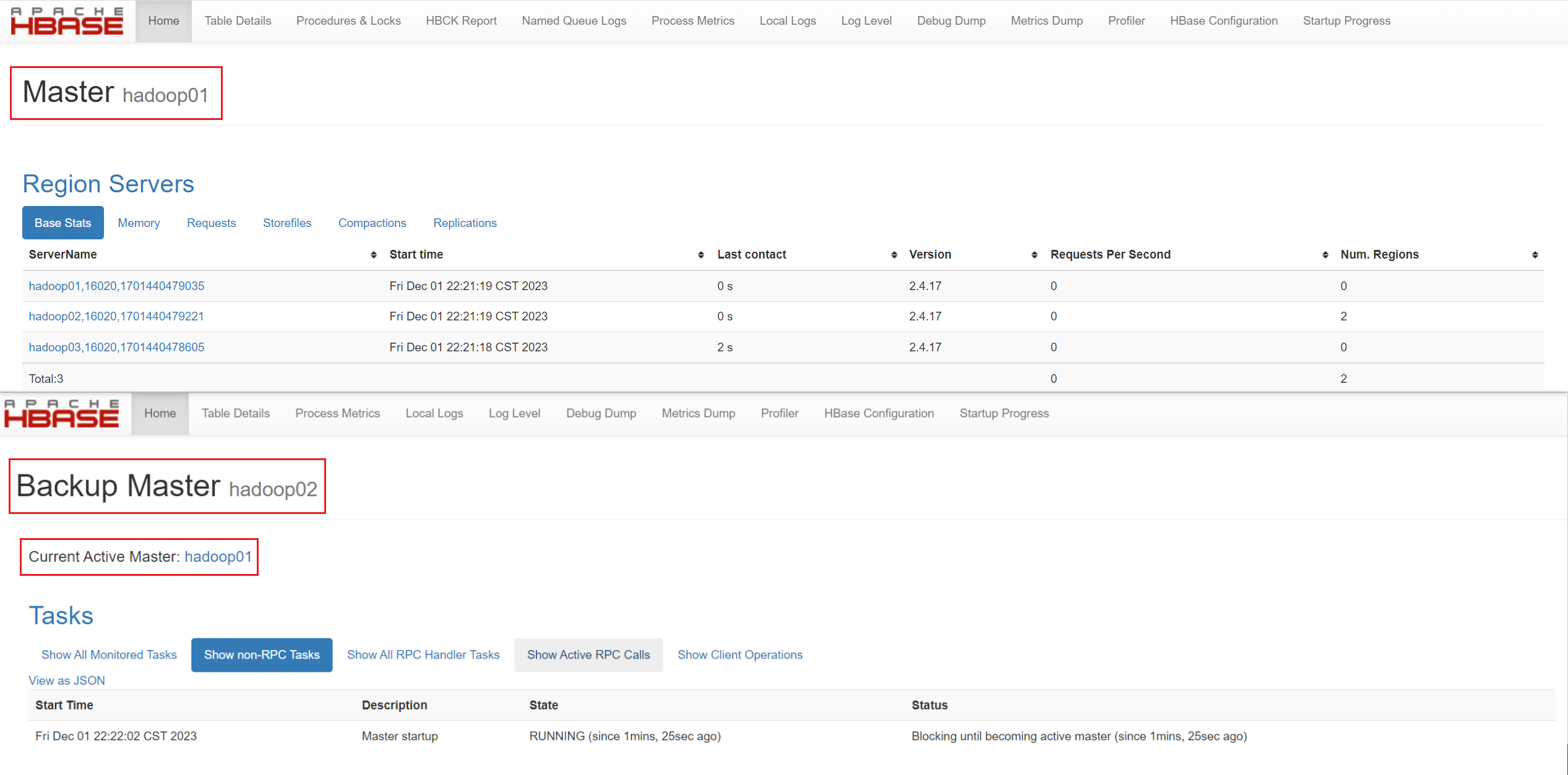
简单测试shell 命令
# 任意节点进行 [root@hadoop03 bin]# hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hbase-2.4.17/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Reload4jLoggerFactory] HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell Version 2.4.17, r7fd096f39b4284da9a71da3ce67c48d259ffa79a, Fri Mar 31 18:10:45 UTC 2023 Took 0.0027 seconds hbase:001:0> version # 输入 version 2.4.17, r7fd096f39b4284da9a71da3ce67c48d259ffa79a, Fri Mar 31 18:10:45 UTC 2023 Took 0.0004 seconds # exit 退出 # 由于本笔记目的是为了进行项目配置,暂不涉及更多的集群
七、mysql数据库集群搭建
卸载系统自带的mariadb
# 查看并卸载系统的mariadb软件 [root@hadoop01 ~]# rpm -qa | grep mariadb mariadb-libs-5.5.68-1.el7.x86_64 # 卸载mariadb [root@hadoop01 ~]# rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64 # 因为centos7内部集成了mariadb,而安装mysql的话会和mariadb的文件冲突,所以需要先卸载掉mariadb # 查询还有没有 mariadb 和 mysql [root@hadoop01 ~]# rpm -qa | grep mariadb [root@hadoop01 ~]# rpm -qa | grep mysql # 创建mysql用户并禁止登录 (系统用户 不会生成 home 目录等 其他文件信息) # 该用户将拥有系统权限,但不会有与家目录相关的文件和配置。 MySQL 的运行文件、日志文件等通常会有专门的目录,并不依赖于 MySQL 用户的家目录。 [root@hadoop01 ~]# useradd mysql -s /sbin/nologin # 通常用于系统上运行服务的用户,这些用户的目的是为了执行服务而不是人为的交互。例如,MySQL 服务通常以一个专门的用户(例如 mysql)的身份运行,这个用户的 shell 被设置为 /sbin/nologin,以防止不必要的登录。这样可以增加系统的安全性,因为攻击者无法直接通过登录该用户来执行交互式命令。
💡 在搭建 Hadoop 生态系统中,通常不会使用 MySQL 的 **`root`** 用户作为 Hive Metastore 的连接用户。应该为 Hive Metastore 创建一个专门的用户,并使用该用户来连接到 MySQL 数据库,从而提高安全性并根据最小权限原则进行用户管理。安装mysql
# 解压 [root@hadoop01 ~]# tar -zxvf /opt/software/mysql-5.7.35-el7-x86_64.tar.gz -C /opt/module/ [root@hadoop01 ~]# cd /opt/module/ [root@hadoop01 module]# mv mysql-5.7.35-el7-x86_64/ mysql-5.7.35 # 创建mysql数据目录以及配置目录 [root@hadoop01 module]# mkdir mysql-5.7.35/{data,conf,logs,binlog} # 添加系统环境变量 vim /etc/profile # mysql 环境变量 export MYSQL_HOME=/opt/module/mysql-5.7.35 export PATH=$PATH:$MYSQL_HOME/bin配置mysql
# 创建mysql配置文件 [root@hadoop01 module]# cd mysql-5.7.35/conf/ [root@hadoop01 conf]# vim my.cnf (不能改成别的名字) # 客户端配置,包括客户端连接mysql服务器的相关配置 [client] port = 3306 socket = /opt/module/mysql-5.7.35/mysqld.sock default-character-set = utf8mb4 # MySQL命令行客户端的配置 [mysql] # 指定MySQL命令行提示符的格式。 prompt="\u@mysqldb \R:\m:\s [\d]> " # 禁用自动补全功能 no-auto-rehash # 指定MySQL命令行客户端的默认字符集 default-character-set = utf8mb4 # MySQL服务器的配置 [mysqld] # 指定MySQL服务器运行的用户 (一般设置为mysql,需要提前创建mysql用户) user = mysql # 指定MySQL服务器监听的端口号 port = 3306 socket = /opt/module/mysql-5.7.35/mysqld.sock # 禁用DNS反向解析 skip-name-resolve # 设置字符编码 character-set-server = utf8 collation-server = utf8_general_ci # 设置默认时区 default-time_zone='+8:00' # 指定MySQL服务器的唯一标识 server-id = 1 # Directory # 安装目录 basedir = /opt/module/mysql-5.7.35/ # 数据存储目录 datadir = /opt/module/mysql-5.7.35/data # 安全文件目录 secure_file_priv = /opt/module/mysql-5.7.35/data # PID文件的路径 pid-file = /opt/module/mysql-5.7.35/mysql.pid # MySQL服务器的最大连接数 max_connections = 1024 # 最大连接错误数 max_connect_errors = 100 # 连接超时时间 wait_timeout = 100 # 最大允许数据包大小 max_allowed_packet = 128M # 表缓存数量 table_open_cache = 2048 # 连接请求队列长度 back_log = 600 # 指定MySQL服务器的默认存储引擎 default-storage-engine = innodb # 允许二进制日志中包含函数创建语句 log_bin_trust_function_creators = 1 # Log # 关闭通用查询日志 general_log=off general_log_file = /opt/module/mysql-5.7.35/logs/mysql.log #错误日志的路径 log-error = /opt/module/mysql-5.7.35/logs/error.log # binlog #指定二进制日志的路径和格式 log-bin = /opt/module/mysql-5.7.35/binlog/mysql-binlog binlog_format=mixed # slowlog慢查询日志 slow_query_log = 1 slow_query_log_file = /opt/module/mysql-5.7.35/logs/slow.log long_query_time = 2 log_output = FILE log_queries_not_using_indexes = 0 # global_buffers innodb_buffer_pool_size = 2G innodb_log_buffer_size = 16M innodb_flush_log_at_trx_commit = 2 key_buffer_size = 64M innodb_log_file_size = 512M innodb_log_file_size = 2G innodb_log_files_in_group = 2 innodb_data_file_path = ibdata1:20M:autoextend sql_mode = STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION [mysqldump] # 指定mysqldump工具使用快速导出模式 quick # 指定mysqldump工具允许的最大数据包大小为32M max_allowed_packet = 32M
初始化mysql 并启动
# 创建链接 [root@hadoop01 conf]# ln my.cnf /etc/my.cnf # 这通常用于将配置文件从一个位置链接到另一个位置,以方便访问或者使不同的程序或用户能够共享同一份配置文件。 # 将mysql-5.7.35文件下的文件归属设置为mysql用户 [root@hadoop01 conf]# chown -R mysql:mysql /opt/module/mysql-5.7.35/ # 初始化 MySQL 数据库 [root@hadoop01 conf]# cd .. [root@hadoop01 mysql-5.7.35]# ./bin/mysqld --initialize --user=mysql --datadir=/opt/module/mysql-5.7.35/data/ --basedir=/opt/module/mysql-5.7.35/ # --initialize : 这个选项告诉 MySQL 初始化数据库。在首次启动 MySQL 服务器之前,你需要执行这个操作来创建数据库的初始结构,包括系统表和权限表。 # 配置 mysql 快捷启动 [root@hadoop01 mysql-5.7.35]# cp support-files/mysql.server /etc/init.d/mysqld [root@hadoop01 mysql-5.7.35]# chmod 777 /etc/init.d/mysqld # 启动 mysql [root@hadoop01 mysql-5.7.35]# /etc/init.d/mysqld start Starting MySQL.... SUCCESS! # 查看 mysql 进程 [root@hadoop01 mysql-5.7.35]# ss -ntulp | grep mysql tcp LISTEN 0 128 [::]:3306 [::]:* users:(("mysqld",pid=5419,fd=30))设置mysql 开机自启
# 设置mysql开机自启 chkconfig --level 35 mysqld on # 表示在运行级别 3 和 5 下启用 mysqld 服务,意味着 MySQL 服务将在系统启动时自动启动 [root@hadoop01 mysql-5.7.35]# chkconfig --list mysqld Note: This output shows SysV services only and does not include native systemd services. SysV configuration data might be overridden by native systemd configuration. If you want to list systemd services use 'systemctl list-unit-files'. To see services enabled on particular target use 'systemctl list-dependencies [target]'. mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off # MySQL 服务在运行级别 2、3、4、5 下是启用的,而在运行级别 0 和 6 下是禁用的。这意味着 MySQL 服务会在系统启动时自动启动,并在进入多用户模式(运行级别 2、3、4、5)时保持启用。 chmod 777 /etc/rc.d/init.d/mysqld chkconfig --add mysqld chkconfig --list mysqld [root@hadoop01 mysql-5.7.35]# service mysqld status SUCCESS! MySQL running (5419) [root@hadoop01 mysql-5.7.35]# reboot [root@hadoop01 ~]# ss -ntulp | grep mysql tcp LISTEN 0 128 [::]:3306 [::]:* users:(("mysqld",pid=2133,fd=32))创建hive使用的相关用户并授权
[root@hadoop01 ~]# grep password /opt/module/mysql-5.7.35/logs/error.log 2023-12-02T10:46:22.116862Z 1 [Note] A temporary password is generated for root@localhost: 1WuYfoDmvc-L [root@hadoop01 ~]# mysqladmin -uroot -p'1WuYfoDmvc-L' password 123456 # 出现警告不用管 (因为密码使用了明文) # 登录 mysql 客户端 [root@hadoop01 ~]# mysql -uroot -p123456 # 添加远程访问权限 root@mysqldb 19:13: [(none)]> grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; # 创建hive数据库并授权 root@mysqldb 19:14: [(none)]> create database hive; root@mysqldb 19:15: [(none)]> create user "hive"@"%" identified by "123456"; root@mysqldb 19:16: [(none)]> grant all privileges on hive.* to "hive"@"%"; root@mysqldb 19:16: [(none)]> flush privileges; # 创建一个名为 "hive" 的数据库,创建一个用户名为 "hive",允许从任何主机(%表示通配符,表示来自任何主机)连接的用户,并授予该用户对 "hive" 数据库的所有权限 # 输入exit 退出即可
八、hive集群搭建
首先需要hadoop 用户代理服务 core-site.xml
# 需要将集群都关闭!!! 再进行!!! # 修改 hadoop 配置文件复制到 hive 中 [root@hadoop01 ~]# cd /opt/module/hadoop-3.3.5/etc/hadoop/ [root@hadoop01 hadoop]# vim core-site.xml # 添加以下配置项:
hadoop.proxyuser.root.hosts * hadoop.proxyuser.root.groups * 主机环境配置
[root@hadoop01 ~]# tar -zxvf /opt/software/apache-hive-3.1.3-bin.tar.gz -C /opt/module/ [root@hadoop01 ~]# cd /opt/module/ [root@hadoop01 module]# mv apache-hive-3.1.3-bin/ hive-3.1.3/ # 配置 hbase 环境变量 vim /etc/profile # hive环境变量 export HIVE_HOME=/opt/module/hive-3.1.3 export PATH=$PATH:$HIVE_HOME/bin # 激活环境变量 source /etc/profile
配置hive 核心文件
cd hive-3.1.3/conf/ # 配置hive日志文件 cp hive-log4j2.properties.template hive-log4j2.properties [root@hadoop01 conf]# vim hive-log4j2.properties # 修改 日志 存放位置 # 修改配置项: property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name} # 修改为 property.hive.log.dir = /opt/module/hive-3.1.3/logs # 解决 hive 控制台输出大量日志信息 解决方法 [root@hadoop01 conf]# vim log4j.properties # 插入以下内容即可 log4j.rootLogger=WARN,CA log4j.appender.CA=org.apache.log4j.ConsoleAppender log4j.appender.CA.layout=org.apache.log4j.PatternLayout log4j.appender.CA.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n [root@hadoop01 conf]# cp hive-env.sh.template hive-env.sh [root@hadoop01 conf]# vim hive-env.sh # 修改配置项如下 HADOOP_HOME=/opt/module/hadoop-3.3.5 export HIVE_CONF_DIR=/opt/module/hive-3.1.3/conf export HIVE_AUX_JARS_PATH=/opt/module/hive-3.1.3/lib export JAVA_HOME=/opt/module/jdk1.8.0_391配置hive-site.xml 文件 (metastore 和 hiveserver2)
💡 说明:Metastore负责管理和存储Hive表的元数据信息,而HiveServer2充当Hive服务端,允许客户端通过不同的接口与Hive交互执行查询。# 需要开启 hadoop 集群 和 zookeeper集群 [root@hadoop01 conf]# hadoop fs -ls /user Found 1 items drwxr-xr-x - root supergroup 0 2023-12-01 12:59 /user/root [root@hadoop01 conf]# hdfs dfs -mkdir -p /user/hive/{warehouse,tmp,logs} [root@hadoop01 conf]# hdfs dfs -chmod -R 777 /user/hive/ [root@hadoop01 conf]# vim hive-site.xmlhive.metastore.local true hive.exec.scratchdir /user/hive/tmp hive.scratch.dir.permission 777 hive.metastore.warehouse.dir /user/hive/warehouse javax.jdo.option.ConnectionURL jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true&useSSL=false javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName hive javax.jdo.option.ConnectionPassword 123456 hive.metastore.uris thrift://hadoop01:9083,thrift://hadoop02:9083 hive.server2.support.dynamic.service.discovery true 当启用时,Hive Server 2会注册到ZooKeeper,并通过ZooKeeper进行服务发现。这可以支持Hive Server 2的高可用和负载均衡配置 hive.server2.active.passive.ha.enable true hive.server2.zookeeper.namespace hiveserver2_zk hive.zookeeper.quorum hadoop01:2181,hadoop02:2181,hadoop03:2181 hive.zookeeper.client.port 2181 hive.server2.thrift.port 10001 hive.server2.thrift.bind.host hadoop02 hive.querylog.location /user/hive/logs hive.cli.print.header true hive.cli.print.current.db true 初始化mysql
# 将下载 mysql 驱动包到 hive 的 lib 目录下 [root@hadoop01 conf]# cp /opt/software/mysql-connector-java-5.1.49.jar /opt/module/hive-3.1.3/lib/ # 删除 hive 下的 log4j-slf4j-impl-2.17.1.jar,会与hadoop下的 slf4j-reload4j-1.7.36.jar 冲突 [root@hadoop01 conf]# rm -rf ../lib/log4j-slf4j-impl-2.17.1.jar [root@hadoop01 conf]# rm -rf /opt/module/hive-3.1.3/lib/guava-19.0.jar [root@hadoop01 conf]# cp /opt/module/hadoop-3.3.5/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/hive-3.1.3/lib/ # 将 hive 文件 同步到其他主机 cd /opt/module [root@hadoop01 module]# xsync hive-3.1.3/ [root@hadoop01 module]# xsync /etc/profile # 分别在 hadoop02 和 hadoop03 上 执行以下代码 激活环境变量 # 在 hadoop02 和 hadoop03 上 建议先删除 关于 mysql 的环境变量 source /etc/profile # 在初始化 mysql 之前 要在hadoop03 上 修改 hive-site.xml文件 # 在 hadoop02 上不用修改,因为使用的是同一份配置,即hadoop01 和 hadoop02 是一样的 # 在 hadoop03 上修改hive.server2.thrift.bind.host hadoop03 在数据库管理工具中,可以进行查看虚拟机中的mysql数据库中的hive库 这里我使用的是 datagrip
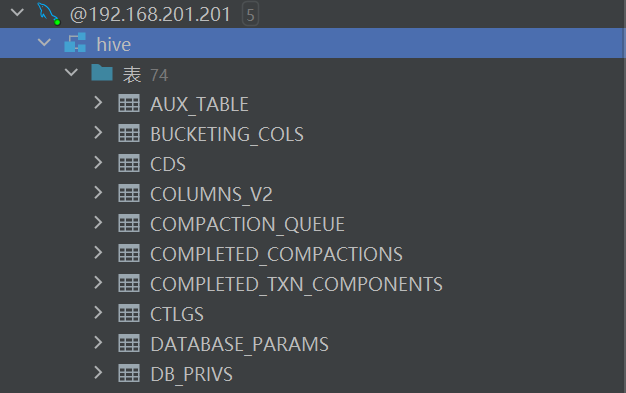
初始化报错解决方法
# 如果按照我实现的顺序进行,一般不会出现问题 [root@hadoop01 module]# schematool -dbType mysql -initSchema Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Starting metastore schema initialization to 3.1.0 Initialization script hive-schema-3.1.0.mysql.sql Error: Syntax error: Encountered "
" at line 1, column 64. (state=42X01,code=30000) org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !! Underlying cause: java.io.IOException : Schema script failed, errorcode 2 Use --verbose for detailed stacktrace. *** schemaTool failed *** # 初始化失败了,通过查询 原因是 hive 中的 lib 文件里面 关于 guava-19.0.jar 版本为 19 而在 hadoop 中的版本为 27 guava-27.0-jre.jar # 解决方法: [root@hadoop01 module]# rm -rf /opt/module/hive-3.1.3/lib/guava-19.0.jar [root@hadoop01 module]# cp /opt/module/hadoop-3.3.5/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/hive-3.1.3/lib/ # 重新执行格式化 [root@hadoop01 module]# schematool -dbType mysql -initSchema Metastore connection URL: jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true&useSSL=false Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: hive Starting metastore schema initialization to 3.1.0 Initialization script hive-schema-3.1.0.mysql.sql Error: Table 'CTLGS' already exists (state=42S01,code=1050) org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !! Underlying cause: java.io.IOException : Schema script failed, errorcode 2 Use --verbose for detailed stacktrace. *** schemaTool failed *** # 需要连接数据库,将hive 中的所有表进行删除 启动metastore
[root@hadoop02 ~]# nohup hive --service metastore >> /opt/module/hive-3.1.3/logs/metastore.log 2>&1 & [root@hadoop02 ~]# mkdir /opt/module/hive-3.1.3/logs [root@hadoop02 ~]# nohup hive --service metastore >> /opt/module/hive-3.1.3/logs/metastore.log 2>&1 & [1] 3695 #查看启动的服务,验证 [root@hadoop02 hive-3.1.3]# ss -ntulp | grep 3695 tcp LISTEN 0 50 [::]:9083 [::]:* users:(("java",pid=3695,fd=630))启动hiveserver2
[root@hadoop02 ~]# nohup hive --service hiveserver2 >> /opt/module/hive-3.1.3/logs/hiveserver2.log 2>&1 & [root@hadoop03 ~]# mkdir /opt/module/hive-3.1.3/logs [root@hadoop03 ~]# nohup hive --service hiveserver2 >> /opt/module/hive-3.1.3/logs/hiveserver2.log 2>&1 & [1] 2141 #查看启动的服务,验证 [root@hadoop03 hadoop]# ss -ntulp | grep 2141 tcp LISTEN 0 50 [::]:10001 [::]:* users:(("java",pid=2141,fd=627)) tcp LISTEN 0 50 [::]:10002 [::]:* users:(("java",pid=2141,fd=632))hive启动测试
在浏览器上输入 hadoop02:10002或者hadoop03:10002
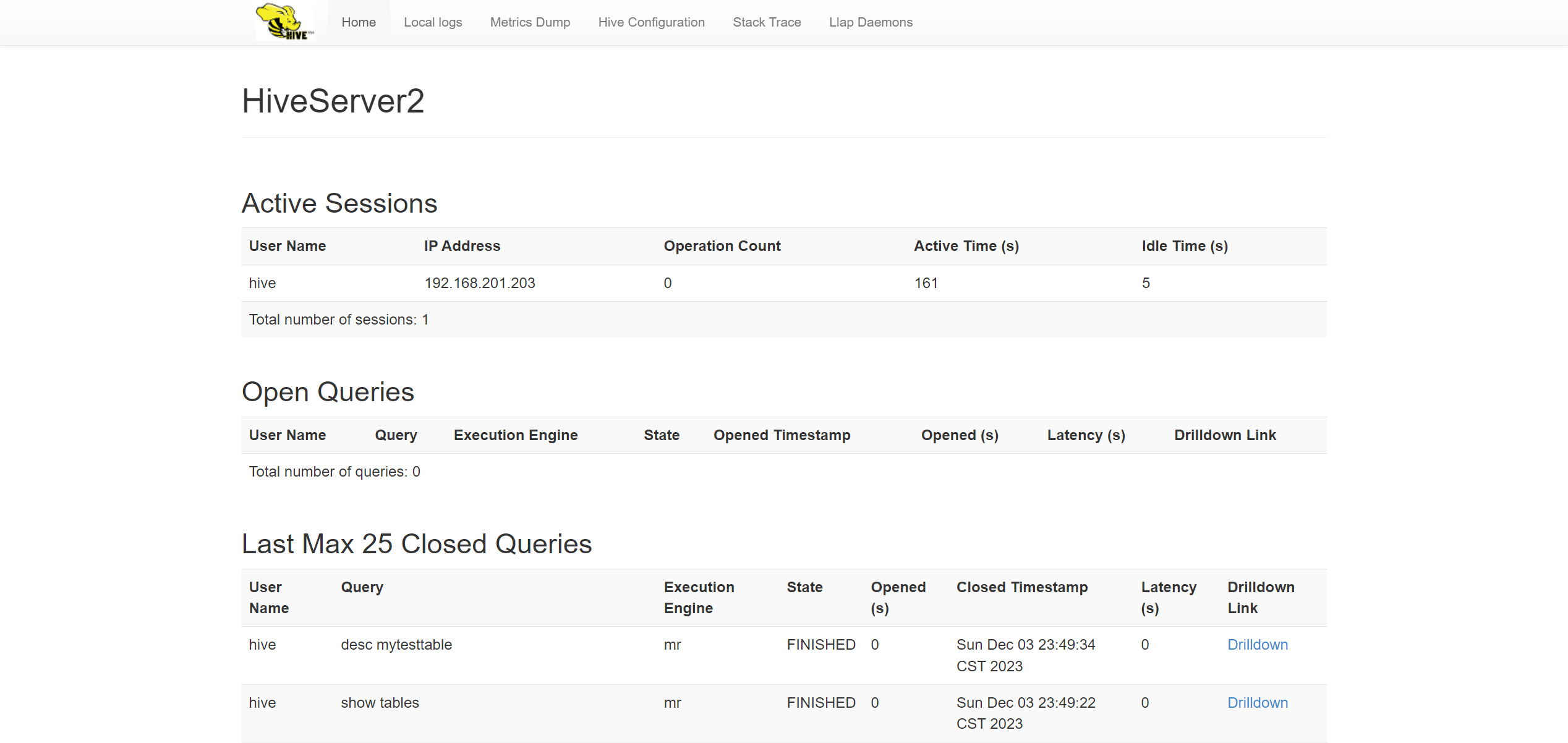
# 在本次 hive 集群搭建的过程中,我将 hadoop03 当作客户机来使用 # 连接测试 [root@hadoop03 hadoop]# beeline -u jdbc:hive2://hadoop02:10001 Connecting to jdbc:hive2://hadoop02:10001 2023-12-03 23:06:53,137 INFO jdbc.Utils: Supplied authorities: hadoop02:10001 2023-12-03 23:06:53,139 INFO jdbc.Utils: Resolved authority: hadoop02:10001 Connected to: Apache Hive (version 3.1.3) Driver: Hive JDBC (version 2.3.9) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 2.3.9 by Apache Hive 0: jdbc:hive2://hadoop02:10001> Closing: 0: jdbc:hive2://hadoop02:10001 [root@hadoop03 hadoop]# beeline -u jdbc:hive2://hadoop03:10001 Connecting to jdbc:hive2://hadoop03:10001 2023-12-03 23:08:10,208 INFO jdbc.Utils: Supplied authorities: hadoop03:10001 2023-12-03 23:08:10,209 INFO jdbc.Utils: Resolved authority: hadoop03:10001 Connected to: Apache Hive (version 3.1.3) Driver: Hive JDBC (version 2.3.9) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 2.3.9 by Apache Hive 0: jdbc:hive2://hadoop03:10001> Closing: 0: jdbc:hive2://hadoop03:10001
hive数据库创建测试并查看hiveserver2状态
[root@hadoop03 hadoop]# beeline Beeline version 2.3.9 by Apache Hive beeline> !connect jdbc:hive2://hadoop02:10001 Connecting to jdbc:hive2://hadoop02:10001 Enter username for jdbc:hive2://hadoop02:10001: hive Enter password for jdbc:hive2://hadoop02:10001: 2023-12-03 23:46:57,731 INFO jdbc.Utils: Supplied authorities: hadoop02:10001 2023-12-03 23:46:57,732 INFO jdbc.Utils: Resolved authority: hadoop02:10001 Connected to: Apache Hive (version 3.1.3) Driver: Hive JDBC (version 2.3.9) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://hadoop02:10001> create database if not exists mytestdb; No rows affected (0.1 seconds) 0: jdbc:hive2://hadoop02:10001> use mytestdb; No rows affected (0.059 seconds) 0: jdbc:hive2://hadoop02:10001> show tables; +--------------+ | tab_name | +--------------+ | mytesttable | +--------------+ 1 row selected (0.127 seconds) 0: jdbc:hive2://hadoop02:10001> describe database mytestdb; +-----------+----------+---------------------------------------------------+-------------+-------------+-------------+ | db_name | comment | location | owner_name | owner_type | parameters | +-----------+----------+---------------------------------------------------+-------------+-------------+-------------+ | mytestdb | | hdfs://mycluster/user/hive/warehouse/mytestdb.db | anonymous | USER | | +-----------+----------+---------------------------------------------------+-------------+-------------+-------------+ 1 row selected (0.068 seconds) 0: jdbc:hive2://hadoop02:10001> CREATE EXTERNAL TABLE IF NOT EXISTS mytesttable ( . . . . . . . . . . . . . . . > name string, . . . . . . . . . . . . . . . > age string, . . . . . . . . . . . . . . . > workplace ARRAY
. . . . . . . . . . . . . . . > ) . . . . . . . . . . . . . . . > COMMENT 'This is an text table'; No rows affected (0.074 seconds) 0: jdbc:hive2://hadoop02:10001> show tables; +--------------+ | tab_name | +--------------+ | mytesttable | +--------------+ 1 row selected (0.091 seconds) 0: jdbc:hive2://hadoop02:10001> desc mytesttable; +------------+----------------+----------+ | col_name | data_type | comment | +------------+----------------+----------+ | name | string | | | age | string | | | workplace | array | | +------------+----------------+----------+ 3 rows selected (0.136 seconds) 0: jdbc:hive2://hadoop02:10001> Closing: 0: jdbc:hive2://hadoop02:10001 可以查看,我们创建数据库的过程中,所使用的语句信息会同时保存到hdfs中,并且使用mapreduce的形式运行
另附上述软件下载地址
# jdk https://www.oracle.com/java/technologies/downloads/#sjre8-windows 然后选择最新的linux jdk下载就好 不过需要注册oracle账号进行下载 # hadoop https://archive.apache.org/dist/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz # hbase https://dlcdn.apache.org/hbase/2.4.17/hbase-2.4.17-bin.tar.gz # hive https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz # kafka https://archive.apache.org/dist/kafka/3.4.0/kafka_2.12-3.4.0.tgz # spark https://archive.apache.org/dist/spark/spark-3.2.4/spark-3.2.4-bin-hadoop3.2-scala2.13.tgz # flink https://archive.apache.org/dist/flink/flink-1.16.1/flink-1.16.1-bin-scala_2.12.tgz # flink-share https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-10.0/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar # mysql https://cdn.mysql.com/archives/mysql-5.7/mysql-5.7.35-el7-x86_64.tar.gz # mysql-jdbc https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.49/mysql-connector-java-5.1.49.jar # 软件打包链接 链接:https://pan.baidu.com/s/19cmBl9fpf7-7luxtBhMUJw?pwd=bkth 提取码:bkth
- 文件说明:

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)





还没有评论,来说两句吧...