

文章目录
- BUAA数据结构第五次作业2023
- 1. 树叶节点遍历(树-基础题)
- 题目
- 问题描述
- 输入形式
- 输出形式
- 样例输入
- 样例输出
- 样例说明
- 评分标准
- 问题分析
- 具体处理过程
- 完整代码
- 2. 词频统计(树实现)
- 题目
- 问题描述
- 输入形式
- 输出形式
- 样例输入
- 样例输出
- 样例说明
- 评分标准
- 问题分析
- 具体处理过程
- 完整代码
- 3. 计算器(表达式计算-表达式树实现)
- 题目
- 问题描述
- 输入形式
- 输出形式
- 样例输入
- 样例输出
- 样例说明
- 评分标准
- 问题分析
- 具体处理过程
- 完整代码
- 4. 服务优化
- 题目
- 问题描述
- 输入形式
- 输出形式
- 样例输入
- 样例输出
- 样例说明
- 评分标准
- 问题分析
- 具体处理过程
- 完整代码
- 程序片段编程题 1. 实验: 树的构造与遍历
- 1. 实验目的与要求
- 2.实验内容
- 问题描述
- 输入形式
- 输出形式
- 3. 实验准备
- 4. 实验步骤
- 【步骤一】
- 【步骤二】
- 【步骤三】
- 【步骤四】
- 题解
- 步骤一
- 步骤二
- 步骤三
- 步骤四
- 四个步骤的完整代码
BUAA数据结构第五次作业2023
1. 树叶节点遍历(树-基础题)
题目
问题描述
从标准输入中输入一组整数,在输入过程中按照左子结点值小于根结点值、右子结点值大于等于根结点值的方式构造一棵二叉查找树,然后从左至右输出所有树中叶结点的值及高度(根结点的高度为1)。例如,若按照以下顺序输入一组整数:50、38、30、64、58、40、10、73、70、50、60、100、35,则生成下面的二叉查找树:
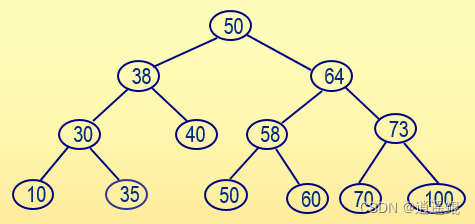
从左到右的叶子结点包括:10、35、40、50、60、70、100,叶结点40的高度为3,其它叶结点的高度都为4。
输入形式
先从标准输入读取整数的个数,然后从下一行开始输入各个整数,整数之间以一个空格分隔。
输出形式
按照从左到右的顺序分行输出叶结点的值及高度,值和高度之间以一个空格分隔。
样例输入
13
50 38 30 64 58 40 10 73 70 50 60 100 35
样例输出
10 4
35 4
40 3
50 4
60 4
70 4
100 4
样例说明
按照从左到右的顺序输出叶结点(即没有子树的结点)的值和高度,每行输出一个。
评分标准
该题要求输出所有叶结点的值和高度,提交程序名为:bst.c
问题分析
本题是BST树的基本题目,甚至被当做例题放在课件里了(我们班是这样的),代码网上应该也有很多,此处我就当解释一下这些代码吧。本题的题面说的很清晰,要求我们按顺序完成一下两件事:
- 根据给的输入数据构建bst;
- 按要求顺序找到各叶子结点并输出其数据。
具体处理过程
首先定义二叉树的结构类型:
typedef struct node { int data; struct node* lchild; struct node* rchild; } node; typedef node* bst;主函数中的框架应当如此:
int main() { int n; scanf("%d", &n); bst root = NULL; int tmp; for (int i = 0; i < n; i++) { // 读入数据,并插入bst scanf("%d", &tmp); root = insert(root, tmp); } printleaf(root, 1); // 按要求输出叶子结点数据 return 0; }其中insert和printleaf的声明如下:
bst insert(bst root, int insert_data) ; void printleaf(bst root, int height);
在insert函数中,传入了根节点root,这是因为insert函数的实现一般是递归的(因为方便好想,当然循环可也可),在最后我们找到了该结点应该插入的位置时,要把这个结点malloc时返回的指针赋给它的双亲结点的左孩子指针或右孩子指针——这也是为什么我们要把root传入函数,而不是把bst的根结点直接定义为全局变量的原因。
其中insert函数的实现如下:
bst insert(bst root, int insert_data) // 把当前数据插入到bst中 { if (root == NULL) { // 当前结点还没有数据,把它插入这里——这是递归的终止条件 root = (node*) malloc(sizeof(node)); root -> data = insert_data; root -> lchild = root -> rchild = NULL; return root; // 这个相当重要,因为要把当前这个刚malloc的结点指针赋值给其双亲结点的左/右孩子指针 } else { if (insert_data < root -> data) { // 数据小于这个结点,把它插到左子树中 root -> lchild = insert(root -> lchild, insert_data); } else { // 数据大于这个结点,把它插入右子树中 root -> rchild = insert(root -> rchild, insert_data); } return root; /* 这个return的作用不太好想,因为真正实现插入操作的return是上面那个return, 这里设置返回值是由调用的形式“root = insert(root, tmp)”所决定的,我们要保证其它的结点在插入后没有变化*/ } }printleaf函数显然也要递归其实现,传入的height参数表示当前的深度,这样在每次递归的时候就能记住当前的深度,其实现如下:
void printleaf(bst root, int height) { if (root -> lchild == NULL && root -> rchild == NULL) { // 该结点为叶子结点,打印数据 printf("%d %d\n", root -> data, height); return; } // 根据题意,由左至右深度优先去打印 if (root -> lchild != NULL) { printleaf(root -> lchild, height + 1); } if (root -> rchild != NULL) { printleaf(root -> rchild, height + 1); } }完整代码
# include
# include typedef struct node { int data; struct node* lchild; struct node* rchild; } node; typedef node* bst; bst insert(bst root, int insert_data) ; void printleaf(bst root, int height); int main() { int n; scanf("%d", &n); bst root = NULL; int tmp; for (int i = 0; i < n; i++) { // 读入数据,并插入bst scanf("%d", &tmp); root = insert(root, tmp); } printleaf(root, 1); // 按要求输出叶子结点数据 return 0; } bst insert(bst root, int insert_data) // 把当前数据插入到bst中 { if (root == NULL) { // 当前结点还没有数据,把它插入这里——这是递归的终止条件 root = (node*) malloc(sizeof(node)); root -> data = insert_data; root -> lchild = root -> rchild = NULL; return root; // 这个相当重要,因为要把当前这个刚malloc的结点指针赋值给其双亲结点的左/右孩子指针 } else { if (insert_data < root -> data) { // 数据小于这个结点,把它插到左子树中 root -> lchild = insert(root -> lchild, insert_data); } else { // 数据大于这个结点,把它插入右子树中 root -> rchild = insert(root -> rchild, insert_data); } return root; /* 这个return的作用不太好想,因为真正实现插入操作的return是上面那个return, 这里设置返回值是由调用的形式“root = insert(root, tmp)”所决定的,我们要保证其它的结点在插入后没有变化*/ } } void printleaf(bst root, int height) { if (root -> lchild == NULL && root -> rchild == NULL) { // 该结点为叶子结点,打印数据 printf("%d %d\n", root -> data, height); return; } // 根据题意,由左至右深度优先去打印 if (root -> lchild != NULL) { printleaf(root -> lchild, height + 1); } if (root -> rchild != NULL) { printleaf(root -> rchild, height + 1); } } 2. 词频统计(树实现)
题目
问题描述
编写程序统计一个英文文本文件中每个单词的出现次数(词频统计),并将统计结果按单词字典序输出到屏幕上。
要求:程序应用二叉排序树(BST)来存储和统计读入的单词。
注:在此单词为仅由字母组成的字符序列。包含大写字母的单词应将大写字母转换为小写字母后统计。在生成二叉排序树不做平衡处理。
输入形式
打开当前目录下文件article.txt,从中读取英文单词进行词频统计。
输出形式
程序应首先输出二叉排序树中根节点、根节点的右节点及根节点的右节点的右节点上的单词(即root、root->right、root->right->right节点上的单词),单词中间有一个空格分隔,最后一个单词后没有空格,直接为回车(若单词个数不足三个,则按实际数目输出)。
程序将单词统计结果按单词字典序输出到屏幕上,每行输出一个单词及其出现次数,单词和其出现次数间由一个空格分隔,出现次数后无空格,直接为回车。
样例输入
当前目录下文件article.txt内容如下:
“Do not take to heart every thing you hear.”
“Do not spend all that you have.”
“Do not sleep as long as you want;”
样例输出
do not take
all 1
as 2
do 3
every 1
have 1
hear 1
heart 1
long 1
not 3
sleep 1
spend 1
take 1
that 1
thing 1
to 1
want 1
you 3
样例说明
程序首先在屏幕上输出程序中二叉排序树上根节点、根节点的右子节点及根节点的右子节点的右子节点上的单词,分别为do not take,然后按单词字典序依次输出单词及其出现次数。
评分标准
通过全部测试点得满分
问题分析
本题和第一题没有本质上的区别,无非是存储的数据类型由整数变成了字符串,插入时比较条件由数的大小变成了字典序的大小,以及文件的读入。
词频统计在本课程中贯穿始终:从最开始的数组链表,到现在的树,到后来的哈希,甚至最终的大作业基本每年都是词频统计,所以设计一个通用函数get_word很有必要(在写大作业时也可以用这个函数)。
具体处理过程
首先定义bst结点类型:
typedef struct node { char word[20]; int time; struct node* lchild; struct node* rchild; } node; typedef node* bst;本题的框架如下:
int main() { bst root = NULL; char tmp_word[20] = {0}; FILE * in = fopen("article.txt", "r"); // 读入数据,插入bst while (get_word(in, tmp_word) != EOF) { root = insert(root, tmp_word); } // 按要求先输出三个特殊结点 bst tmp = root; for (int i = 0; i < 3; i++) { if (tmp) { printf("%s ", tmp -> word); tmp = tmp -> rchild; } } printf("\n"); print_ans(root); // 输出所有单词词频 return 0; }get_word函数实现如下(非常实用的一个函数):
int get_word(FILE *fp, char *dst) { int i = 0; char c; while ((c = fgetc(fp)) != EOF) { if (isalpha(c) != 0) { dst[i++] = tolower(c); } else if (i) { dst[i] = '\0'; return 0; // 正常情况,随便返回一个值 } } return EOF; }insert函数跟上一题的差不多,就不多解释了,注释说的应该挺明白了:
bst insert(bst root, char* insert_data) // 数据插入到bst中 { if (root == NULL) { // 当前位置空,插到这 root = (node*) malloc(sizeof(node)); strcpy(root -> word, insert_data); root -> time = 1; // 这个别忘了 root -> lchild = root -> rchild = NULL; return root; } else { if (strcmp(insert_data, root -> word) < 0) { root -> lchild = insert(root -> lchild, insert_data); } else if (strcmp(insert_data, root -> word) > 0) { root -> rchild = insert(root -> rchild, insert_data); } else { // 多加一个判断条件,当这里已经有数据了,就把time域加一 root -> time++; } return root; } }设计print_ans函数时,只需要记住对bst中序遍历就得到了从小到大排序的序列信息就可以,所以就是一个标准的中序遍历函数:
void print_ans(bst root) { if (root -> lchild != NULL) { // 左 print_ans(root -> lchild); } if (root) printf("%s %d\n", root -> word, root -> time); // 中 if (root ->rchild != NULL) { // 右 print_ans(root -> rchild); } }完整代码
# include
# include # include # include typedef struct node { char word[20]; int time; struct node* lchild; struct node* rchild; } node; typedef node* bst; int get_word(FILE *fp, char *dst); bst insert(bst root, char* insert_data); void print_ans(bst root); int main() { bst root = NULL; char tmp_word[20] = {0}; FILE * in = fopen("article.txt", "r"); // 读入数据,插入bst while (get_word(in, tmp_word) != EOF) { root = insert(root, tmp_word); } // 按要求先输出三个特殊结点 bst tmp = root; for (int i = 0; i < 3; i++) { if (tmp) { printf("%s ", tmp -> word); tmp = tmp -> rchild; } } printf("\n"); print_ans(root); // 输出所有单词词频 return 0; } int get_word(FILE *fp, char *dst) { int i = 0; char c; while ((c = fgetc(fp)) != EOF) { if (isalpha(c) != 0) { dst[i++] = tolower(c); } else if (i) { dst[i] = '\0'; return 0; // 正常情况,随便返回一个值 } } return EOF; } bst insert(bst root, char* insert_data) // 数据插入到bst中 { if (root == NULL) { // 当前位置空,插到这 root = (node*) malloc(sizeof(node)); strcpy(root -> word, insert_data); root -> time = 1; // 这个别忘了 root -> lchild = root -> rchild = NULL; return root; } else { if (strcmp(insert_data, root -> word) < 0) { root -> lchild = insert(root -> lchild, insert_data); } else if (strcmp(insert_data, root -> word) > 0) { root -> rchild = insert(root -> rchild, insert_data); } else { // 多加一个判断条件,当这里已经有数据了,就把time域加一 root -> time++; } return root; } } void print_ans(bst root) { if (root -> lchild != NULL) { // 左 print_ans(root -> lchild); } if (root) printf("%s %d\n", root -> word, root -> time); // 中 if (root ->rchild != NULL) { // 右 print_ans(root -> rchild); } } 3. 计算器(表达式计算-表达式树实现)
题目
问题描述
从标准输入中读入一个整数算术运算表达式,如24 / ( 1 + 2 + 36 / 6 / 2 - 2) * ( 12 / 2 / 2 )= ,计算表达式结果,并输出。
要求:
- 表达式运算符只有+、-、*、/,表达式末尾的=字符表示表达式输入结束,表达式中可能会出现空格;
- 表达式中会出现圆括号,括号可能嵌套,不会出现错误的表达式;
- 出现除号/时,以整数相除进行运算,结果仍为整数,例如:5/3结果应为1。
- 要求采用表达式树来实现表达式计算。
表达式树(expression tree):
我们已经知道了在计算机中用后缀表达式和栈来计算中缀表达式的值。在计算机中还有一种方式是利用表达式树来计算表达式的值。表达式树是这样一种树,其根节点为操作符,非根节点为操作数,对其进行后序遍历将计算表达式的值。由后缀表达式生成表达式树的方法如下:
- 读入一个符号:
- 如果是操作数,则建立一个单节点树并将指向他的指针推入栈中;
- 如果是运算符,就从栈中弹出指向两棵树T1和T2的指针(T1先弹出)并形成一棵新树,树根为该运算符,它的左、右子树分别指向T2和T1,然后将新树的指针压入栈中。
例如输入的后缀表达为:
ab+cde+**
则生成的表达式树为:
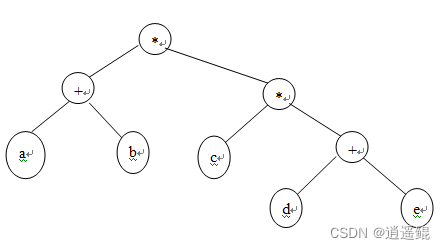
输入形式
从键盘输入一个以=结尾的整数算术运算表达式。操作符和操作数之间可以有空格分隔。
输出形式
首先在屏幕上输出表达式树根、左子节点及右子节点上的运算符或操作数,中间由一个空格分隔,最后有一个回车(如果无某节点,则该项不输出)。然后输出表达式计算结果。
样例输入
24 / ( 1 + 2 + 36 / 6 / 2 - 2) * ( 12 / 2 / 2 ) =
样例输出
* / /
18
样例说明
按照运算符及括号优先级依次计算表达式的值。在生成的表达树中,*是根节点的运算符,/ 是根节点的左子节点上运算符,/是根节点的右子节点上运算符,按题目要求要输出。
评分标准
通过所有测试点得满分。
问题分析
生成表达式树也不能用中缀表达式,还是要先把它转化成后缀表达式——这个过程在栈与队那次作业已经实现过一次了,所以这里就直接拿来用了。在得到后缀表达式后,去构建表达式树时的思路其实还是用到了队列(就是题目说的“森林”)的想法,思路其实应该还算清晰。唯一需要注意的是当处理到最后一个操作符时,当前的队列里应该有两棵树,如果用数组去实现队列的话,还是建议数组的第0个位置空着——这样就不用特判这个情况了(大家好好想想,用纸笔画一下应该能懂我在说什么)。我没有用数组去实现,而是用的链表去实现,其实链表实现队列也应当设置一个哑结点,就相当于数组第0个位置空着,最后返回的根节点就是哑结点,但是我当时写的时候一开始没想到这一点,所以直接硬干了,
还debug了好久。具体处理过程
首先要读入表达式,并将其转化为后缀表达式(逆波兰表达式),直接复用上次作业的代码即可:
# include
# include typedef struct stack_node { union { int num; char op; } data; int type; // 记录是数字(1)还是操作符(0) } stack_node; int ishigh(char c1,char c2) { //判断加减乘除运算符的优先级 int a1,a2; if(c1=='+'||c1=='-')a1=0; else a1 = 1; if(c2=='+'||c2=='-')a2=0; else a2 = 1; if(a1>=a2)return 1; return 0; } int change(char *str,stack_node* representation,char* opera) { int op_num = 0; int rep_num = 0; //暂存各位数字以及数字的位数 int tmp_num[100]; int tmp = 0; for(int i=0;str[i]!='=';i++){ if(!(str[i]>='0'&&str[i]<='9')){ if(tmp!=0){//如果当前不是数字,并且队中还有数字,则现将数字算出来存储到表达式数组中 int number = 0; for(int j=0;j 现在representation结构体数组中就记录了后缀表达式,而rep_num记录了该数组的位数。
接下来要把后缀表达式转化为表达式树,首先要定义表达式树结点类型,由于我们打算用链表去实现,所以除了lchild和rchild两个指针之外,还需要设置一个next指针:
typedef struct tree_node { union { int num; char op; } data; // 该结点的数据(用联合去定义) int type; // 该结点的数据类型(数字1,操作符0) struct tree_node* next; struct tree_node* lchild; struct tree_node* rchild; } tree_node;接下来要设计一个函数把representation中的后缀表达式转化为表达式树,实现如下:
tree_node* switch_to_tree(stack_node representation[], int rep_num) // 将后缀表达式转化为表达式树,返回树的根结点指针 { tree_node* root = NULL; // “队”头 tree_node* tail = NULL; // 队“尾” for (int i = 0; i < rep_num; i++) { // 对后缀表达式每一位遍历 if (representation[i].type == 1) { // 当前位是数字 if (root == NULL) { // 这是读入的第一个数据,创建根结点 root = (tree_node*) malloc(sizeof(tree_node)); root -> data.num = representation[i].data.num; root -> lchild = root -> rchild = root -> next = NULL; root -> type = 1; tail = root; } else { // 为该数字创建新结点,并把它放到队尾 tail -> next = (tree_node*) malloc(sizeof(tree_node)); tail = tail -> next; tail -> data.num = representation[i].data.num; tail -> lchild = tail -> rchild = tail -> next = NULL; tail -> type = 1; } } else { // 当前位是操作符 tree_node* last1 = tail; // 最后一个结点 tree_node* last2 = find_pre(root, tail); // 倒数第二个结点 tree_node* last3 = find_pre(root, last2); // 倒数第三个结点 if (last3 != NULL) { // 当前队列中的结点个数大于2,说明还没读到最后一个操作符 last3 -> next = (tree_node*) malloc(sizeof(tree_node)); // 创建新结点(替代原来last2的位置) tail = last3 -> next; tail -> next = NULL; tail -> type = 0; tail -> data.op = representation[i].data.op; tail -> lchild = last2; // 把最后两个结点分别作为新结点的左右孩子 tail -> rchild = last1; } else { // 特判当前队里只剩下两个结点(最后一次操作) root = (tree_node*) malloc(sizeof(tree_node)); // 把root改为新结点(记录的是当前(也就是表达式最后一位)的操作符) root -> type = 0; root -> data.op = representation[i].data.op; root -> lchild = last2; root -> rchild = last1; tail = root; root -> next = NULL; tail -> next =NULL; } } } return root; }其中find_pre是链表的常规操作,实现如下:
tree_node* find_pre(tree_node* root, tree_node* tail) { if (root == tail) return NULL; tree_node* p = root; while(p -> next != tail) { p = p -> next; } return p; }主函数中调用该函数后,就得到了表达式树,接下来按照题意输出:
// 主函数中 tree_node* root = switch_to_tree(representation, rep_num); // 转化为表达式树 printf("%c ", root -> data.op); // 打印根结点的数据(一定是操作符) if (root -> lchild != NULL) { // 打印根结点的左子树的数据(题意要求) if (root -> lchild ->type == 1) { printf("%d ", root -> lchild -> data.num); } else { printf("%c ", root -> lchild -> data.op); } } if (root -> rchild != NULL) { // 打印根结点右子树的数据(题意要求) if (root -> rchild ->type == 1) { printf("%d", root -> rchild -> data.num); } else { printf("%c", root -> rchild -> data.op); } } printf("\n"); printf("%d", calculate(root)); // 用表达式树计算其中calculate函数的实现也很简单,无非就是传入一个树的根结点,去计算该树的表达式值。可以用递归去解决:该树的根结点为叶子结点时(type==1),直接返回其所代表的数值(这是递归终止条件),否则(该树的根结点是操作符)分别计算出其左右子树的数值后计算即可:
int calculate(tree_node *root) // 计算表达式树的值 { if (root -> type == 1) return root -> data.num; // 该树的根结点为叶子结点 // 否则,该结点为操作符 int num1 = calculate(root -> lchild); // 左子树的值 int num2 = calculate(root -> rchild); // 右子树的值 switch(root -> data.op){ case '+': return num1 + num2; case '-': return num1 -num2; case '*': return num1 * num2; case '/': return num1 / num2; } }顺便说一句,debug的时候需要判断自己构建的表达式树对不对,可以设计一个函数把其中序遍历一遍,就应当输出正常的中缀表达式,我debug时用到了,其实现如下:
void printTree(tree_node *root) { if (root == NULL) return; printTree(root->lchild); if (root->type == 1) { printf("%d ", root->data.num); } else { printf("%c ", root->data.op); } printTree(root->rchild); }完整代码
# include
# include typedef struct stack_node { union { int num; char op; } data; int type; } stack_node; typedef struct tree_node { union { int num; char op; } data; // 该结点的数据(用联合去定义) int type; // 该结点的数据类型(数字1,操作符0) struct tree_node* next; struct tree_node* lchild; struct tree_node* rchild; } tree_node; int ishigh(char c1,char c2) { //判断加减乘除运算符的优先级 int a1,a2; if(c1=='+'||c1=='-')a1=0; else a1 = 1; if(c2=='+'||c2=='-')a2=0; else a2 = 1; if(a1>=a2)return 1; return 0; } int change(char *str,stack_node* representation,char* opera) { int op_num = 0; int rep_num = 0; //暂存各位数字以及数字的位数 int tmp_num[100]; int tmp = 0; for(int i=0;str[i]!='=';i++){ if(!(str[i]>='0'&&str[i]<='9')){ if(tmp!=0){//如果当前不是数字,并且队中还有数字,则现将数字算出来存储到表达式数组中 int number = 0; for(int j=0;j 4. 服务优化
题目
问题描述
假设某机场所有登机口(Gate)呈树形排列(树的度为3),安检处为树的根,如下图所示。图中的分叉结点(编号大于等于100)表示分叉路口,登机口用小于100的编号表示(其一定是一个叶结点)。通过对机场所有出发航班的日志分析,得知每个登机口每天的平均发送旅客流量。作为提升机场服务水平的一个措施,在不改变所有航班相对关系的情况下(即:出发时间不变,原在同一登机口的航班不变),仅改变登机口(例如:将3号登机口改到5号登机口的位置),使得整体旅客到登机口的时间有所减少(即:从安检口到登机口所经过的分叉路口最少)。
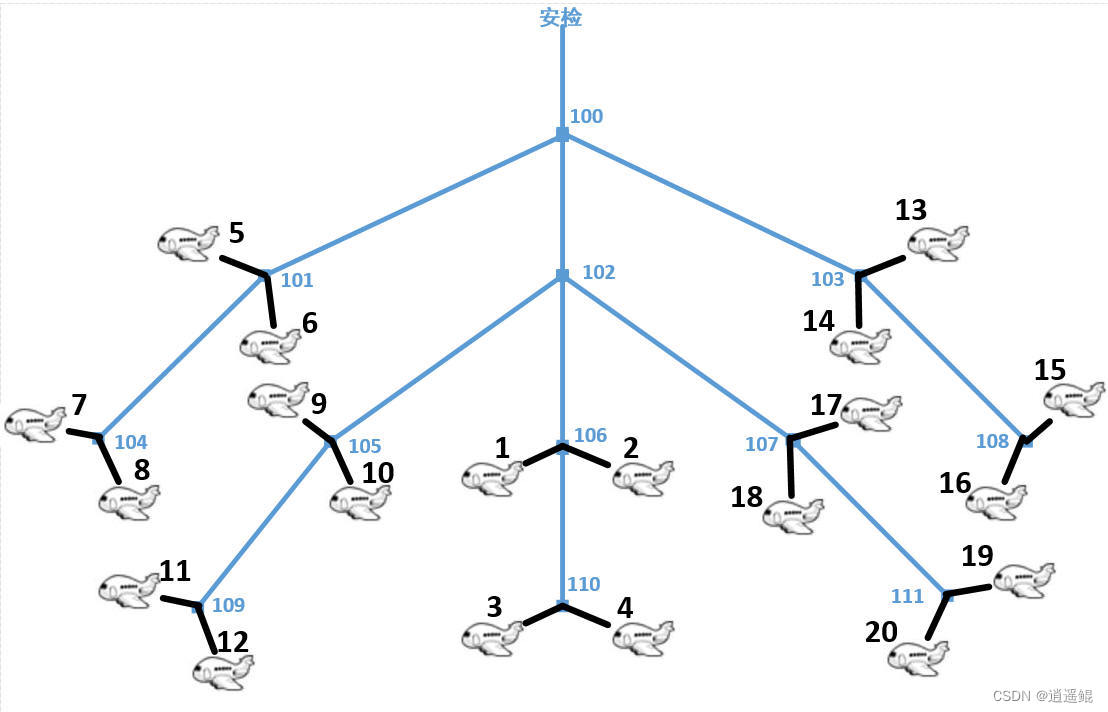
编写程序模拟上述登机口的调整,登机口调整规则如下:
- 首先按照由大到小的顺序对输入的登机口流量进行排序,流量相同的按照登机口编号由小到大排序;
- 从上述登机口树的树根开始,将登机口按照从上到下(安检口在最上方)、从左到右的顺序,依次对应上面排序后将要调整的登机口。
例如上图的树中,若只考虑登机口,则从上到下有三层,第一层从左到右的顺序为:5、6、14、13,第二层从左到右的顺序为:7、8、9、10、1、2、18、17、16、15,第三层从左到右的顺序为:11、12、3、4、20、19。若按规则1排序后流量由大至小的前五个登机口为3、12、16、20、15,则将流量最大的3号登机口调整到最上层且最左边的位置(即:5号登机口的位置),12号调整到6号,16号调整到14号,20号调整到13号,15号调整到第二层最左边的位置(即7号登机口的位置)。
输入形式
1)首先按层次从根开始依次输入树结点之间的关系。其中分叉结点编号从数字100开始(树根结点编号为100,其它分叉结点编号没有规律但不会重复),登机口为编号小于100的数字(编号没有规律但不会重复,其一定是一个叶结点)。树中结点间关系用下面方式描述:
R S1 S2 S3 -1
其中R为分叉结点,从左至右S1,S2,S3分别为树叉R的子结点,其可为树叉或登机口,由于树的度为3,S1,S2,S3中至多可以2个为空,最后该行以-1和换行符结束。各项间以一个空格分隔。如:
100 101 102 103 -1
表明编号100的树根有三个子叉,编号分别为101、102和103,又如:
104 7 8 -1
表明树叉104上有2个编号分别为7和8的登机口。
假设分叉结点数不超过100个。分叉结点输入的顺序不确定,但可以确定:输入某个分叉结点信息时,其父结点的信息已经输入。
输入完所有树结点关系后,在新的一行上输入-1表示树结点关系输入完毕。
2)接下来输入登机口的流量信息,每个登机口流量信息分占一行,分别包括登机口编号(1~99之间的整数)和流量(大于0的整数),两整数间以一个空格分隔。登机口数目与前面构造树时的登机机口数目一致。
输出形式
按照上述调整规则中排序后的顺序(即按旅客流量由大到小,流量相同的按照登机口编号由小到大)依次分行输出每个登机口的调整结果:先输出调整前的登机口编号,然后输出字符串"->"(由英文减号字符与英文大于字符组成),再输出要调整到的登机口编号。
样例输入
100 101 102 103 -1
103 14 108 13 -1
101 5 104 6 -1
104 7 8 -1
102 105 106 107 -1
106 1 110 2 -1
108 16 15 -1
107 18 111 17 -1
110 3 4 -1
105 9 109 10 -1
111 20 19 -1
109 11 12 -1
-1
17 865
5 668
20 3000
13 1020
11 980
8 2202
15 1897
6 1001
14 922
7 2178
19 2189
1 1267
12 3281
2 980
18 1020
10 980
3 1876
9 1197
16 980
4 576
样例输出
12->5
20->6
8->14
19->13
7->7
15->8
3->9
1->10
9->1
13->2
18->18
6->17
2->16
10->15
11->11
16->12
14->3
17->4
5->20
4->19
样例说明
样例输入了12条树结点关系,形成了如上图的树。然后输入了20个登机口的流量,将这20个登机口按照上述调整规则1排序后形成的顺序为:12、20、8、19、7、15、3、1、9、13、18、6、2、10、11、16、14、17、5、4。最后按该顺序将所有登机口按照上述调整规则2进行调整,输出调整结果。
评分标准
该题要求计算并输出登机口的调整方法,提交程序名为adjust.c。
问题分析
写在前面:本题乍一看似乎可以不用树,直接用数组去写,但是用数组的话就无法记住其层次遍历的序列,所以趁早断了这个想法,我就是吃了没先把题目分析完的亏,这条思路莽到最后又推倒重来的。
本题的处理步骤如下:
- 按照题意构建出对应的树(读入-1前),并把所有登机口结点记录到一个数组中(后面要排序)(这一步和流量无关,我们按照题意去构建这棵树的原因就是为了第二步得到其层次遍历序列);
- 把该树按照层次遍历的方法遍历一遍,记这个序列的每个编号(这个序列就是输出时的每行的第二个数(样例中的5 6 14 13 …));
- 读入各登机口流量的数据;
- 按照流量,对各登机口结点进行排序;
- 按照题意输出,其中输出相当于两列数字,第一列是排序后的登机口编号,第二列是原来层次遍历得到的编号序列。
具体处理过程
首先定义结点类型,我们要记录该结点的编号,同时其最多有三个孩子,所以不妨开一个数组去记录其孩子,同时用一个int型变量记录它当前有几个孩子,方便去插入:
typedef struct node { int index; struct node* child[3]; int child_num; int flowrate; // 人流量 } node, * tree;主函数中可以先把根结点构建出来,因为根据题意,根结点一定是编号为100的那个结点:
tree root = (tree) malloc(sizeof(struct node)); root -> index = 100; root -> child[0] = root -> child[1] = root -> child[2] = NULL; root -> child_num = 0;接下来根据读入的信息去构建树,框架应当如此:
int root_index; // 读入要插入的根结点的编号 while(1) { scanf("%d", &root_index); if (root_index == -1) break; // 读到-1退出循环 int child_index; while(1) { // 读其孩子结点的编号 scanf("%d", &child_index); if (child_index == -1) break; insert(root, root_index, child_index); } }其中insert函数应当实现这样的功能:在树中找到编号为root_index的树,然后把数据为child_index的结点插入到其孩子结点中,对于查找只需查找当前结点,然后再去其所有的孩子结点中查找就行,实现如下:
int insert(node* root, int root_index, int child_index) { if (root -> index == root_index) { root -> child[root -> child_num] = (node*) malloc(sizeof(node)); root -> child[root -> child_num] -> index = child_index; root -> child[root -> child_num] -> child_num = 0; root -> child_num++; return 1; } for (int i = 0; i < root -> child_num; i++) { if (insert(root -> child[i], root_index, child_index) == 1) { return 1; // 插入成功了,直接退出函数不再去其他孩子结点中查找插入了 } } return 0; }之所以将其返回值设计成int型而非void,是为了注释那一行所说,通过其插入某一个孩子成功了直接退出函数,而不用再去其下一个孩子结点查找了。
现在我们就构建出了这棵树,接下来要层次遍历所有结点,记录下来其中的登机口结点(叶子结点),关于登机口结点怎么存是一个问题,单纯地把结点实体存入当然没有关系,但是那样效率不会很高(当然这题也跟效率没关系),其实我们完全可以存每个结点的指针,然后排序时把二级指针传入cmp就行。
有关树的层次遍历可以参考课件以及网上的文章,其中用到了队列的想法,所以我开了两个全局变量数组,一个记录所有结点(层次遍历),另一个记录叶子结点的信息(这个是目标,因为我们就是想得到其层次遍历后的序列),为了方便排序,还应记录下叶子结点的个数:
node* all_queue[200]; // 所有结点的队列(层次遍历时用到) node* leaf_queue[100]; // 存储所有叶子结点 int leaf_num = 0; // 叶子结点的个数
而后设计layerorder函数如下(层次遍历):
void layerorder(tree root) // 层次遍历 { node* p; int front = 0, rear = 1; all_queue[0] = root; while(front < rear) { p = all_queue[front++]; if (p -> index < 100) { // 叶子结点 leaf_queue[leaf_num++] = p; } for (int i = 0; i < p -> child_num; i++) { all_queue[rear++] = p -> child[i]; } } }主函数中调用该函数后,得到了我们想要的层次遍历序列,但是后面我们还要对leaf_queue这个数组排序,所以得找一个“替身”保存下这个序列的编号信息:
// 主函数中 int index_order[100] = {0}; // 记录层次遍历的编号顺序 for (int i = 0; i < leaf_num; i++) { index_order[i] = leaf_queue[i] -> index; }然后按照要求读入人流量信息,直接读到leaf_queue就行:
int index,flowrate; for (int i = 0; i < leaf_num; i++) { scanf("%d%d", &index, &flowrate); for (int j = 0; j < leaf_num; j++) { // 在数组中去找编号为index的结点指针 if (leaf_queue[j] -> index == index) { // 找到了 leaf_queue[j] -> flowrate = flowrate; break; } } }然后对leaf_queue数组按照题目要求进行排序,注意这是个指针数组,要把二级指针传入cmp,故设计cmp函数如下:
int cmp(const void* e1, const void* e2) { // 传入二级指针 node** a = (node**) e1; node** b = (node**) e2; // 二级指针先解引用,再用“->”找到对应的域 if ((*a) -> flowrate != (*b) -> flowrate) return (*b) -> flowrate - (*a) -> flowrate; return (*a) -> index - (*b) -> index; }在主函数中排序后,把leaf_queue和index_order各位输出即可:
// 主函数中 qsort(leaf_queue, leaf_num, sizeof(node*), cmp); for (int i = 0; i < leaf_num; i++) { printf("%d->%d\n", leaf_queue[i] -> index, index_order[i]); }完整代码
# include
# include typedef struct node { int index; struct node* child[3]; int child_num; int flowrate; // 人流量 } node, * tree; node* all_queue[200]; // 所有结点的队列(层次遍历时用到) node* leaf_queue[100]; // 存储所有叶子结点 int leaf_num = 0; // 叶子结点的个数 int insert(node* root, int root_index, int child_index) { if (root -> index == root_index) { root -> child[root -> child_num] = (node*) malloc(sizeof(node)); root -> child[root -> child_num] -> index = child_index; root -> child[root -> child_num] -> child_num = 0; root -> child_num++; return 1; } for (int i = 0; i < root -> child_num; i++) { if (insert(root -> child[i], root_index, child_index) == 1) { return 1; // 插入成功了,直接退出函数不再去其他孩子结点中查找插入了 } } return 0; } void layerorder(tree root) // 层次遍历 { node* p; int front = 0, rear = 1; all_queue[0] = root; while(front < rear) { p = all_queue[front++]; if (p -> index < 100) { leaf_queue[leaf_num++] = p; } for (int i = 0; i < p -> child_num; i++) { all_queue[rear++] = p -> child[i]; } } } int cmp(const void* e1, const void* e2) { // 传入二级指针 node** a = (node**) e1; node** b = (node**) e2; // 二级指针先解引用,再用“->”找到对应的域 if ((*a) -> flowrate != (*b) -> flowrate) return (*b) -> flowrate - (*a) -> flowrate; return (*a) -> index - (*b) -> index; } int main() { tree root = (tree) malloc(sizeof(struct node)); root -> index = 100; root -> child[0] = root -> child[1] = root -> child[2] = NULL; root -> child_num = 0; int root_index; // 读入要插入的根结点的编号 while(1) { scanf("%d", &root_index); if (root_index == -1) break; // 读到-1退出循环 int child_index; while(1) { // 读其孩子结点的编号 scanf("%d", &child_index); if (child_index == -1) break; insert(root, root_index, child_index); } } layerorder(root); int index_order[100] = {0}; // 记录层次遍历的编号顺序 for (int i = 0; i < leaf_num; i++) { index_order[i] = leaf_queue[i] -> index; } int index,flowrate; for (int i = 0; i < leaf_num; i++) { scanf("%d%d", &index, &flowrate); for (int j = 0; j < leaf_num; j++) { // 在数组中去找编号为index的结点指针 if (leaf_queue[j] -> index == index) { // 找到了 leaf_queue[j] -> flowrate = flowrate; break; } } } qsort(leaf_queue, leaf_num, sizeof(node*), cmp); for (int i = 0; i < leaf_num; i++) { printf("%d->%d\n", leaf_queue[i] -> index, index_order[i]); } return 0; } 程序片段编程题 1. 实验: 树的构造与遍历
1. 实验目的与要求
在学习和理解二叉树的原理、构造及遍历方法的基础上,应用所学知识来解决实际问题。
本实验将通过一个实际应用问题的解决过程掌握Huffman树的构造、Huffman编码的生成及基于所获得的Huffman编码压缩文本文件。
涉及的知识点包括树的构造、遍历及C语言位运算和二进制文件。
2.实验内容
Huffman编码文件压缩
问题描述
编写一程序采用Huffman编码对一个正文文件进行压缩。具体压缩方法如下:
- 对正文文件中字符(换行字符’\n’除外,不统计)按出现次数(即频率)进行统计。
- 依据字符频率生成相应的Huffman树(未出现的字符不生成)。
- 依据Huffman树生成相应字符的Huffman编码。
- 依据字符Huffman编码压缩文件(即将源文件字符按照其Huffman编码输出)。
说明:
- 只对文件中出现的字符生成Huffman树,注意:一定不要处理\n,即不要为其生成Huffman编码。
- 采用ASCII码值为0的字符作为压缩文件的结束符(即可将其出现次数设为1来参与编码)。
- 在生成Huffman树前,初始在对字符频率权重进行(由小至大)排序时,频率相同的字符ASCII编码值小的在前;新生成的权重节点插入到有序权重序列中时,若出现相同权重,则将新生成的权重节点插入到原有相同权重节点之后(采用稳定排序)。
- 在生成Huffman树时,权重节点在前的作为左孩子节点,权重节点在后的作为右孩子节点。
- 源文件是文本文件,字符采用ASCII编码,每个字符占8个二进制位;而采用Huffman编码后,高频字符编码长度较短(小于8位),因此最后输出时需要使用C语言中的位运算将字符的Huffman码依次输出到每个字节中。
输入形式
对当前目录下文件input.txt进行压缩。
输出形式
将压缩后结果输出到文件output.txt中,同时将压缩结果用十六进制形式(printf(“%x”,…))输出到屏幕上,以便检查和查看结果。
3. 实验准备
1.文件下载
从教学平台(judge.buaa.edu.cn)课程下载区下载文件lab_tree2.rar,该文件中包括了本实验中用到的文件huffman2student.c和input.txt:
huffman2student.c的内容如下:
//文件压缩-Huffman实现 #include
#include #include #define MAXSIZE 32 struct tnode { //Huffman树结构 char c; int weight; //树节点权重,叶节点为字符和它的出现次数 struct tnode *left,*right; } ; int Ccount[128]={0}; //存放每个字符的出现次数,如Ccount[i]表示ASCII值为i的字符出现次数 struct tnode *Root=NULL; //Huffman树的根节点 char HCode[128][MAXSIZE]={{0}}; //字符的Huffman编码,如HCode['a']为字符a的Huffman编码(字符串形式) int Step=0; //实验步骤 FILE *Src, *Obj; void statCount(); //步骤1:统计文件中字符频率 void createHTree(); //步骤2:创建一个Huffman树,根节点为Root void makeHCode(); //步骤3:根据Huffman树生成Huffman编码 void atoHZIP(); //步骤4:根据Huffman编码将指定ASCII码文本文件转换成Huffman码文件 void print1(); //输出步骤1的结果 void print2(struct tnode *p); //输出步骤2的结果 void print3(); //输出步骤3的结果 void print4(); //输出步骤4的结果 int main() { if((Src=fopen("input.txt","r"))==NULL) { fprintf(stderr, "%s open failed!\n", "input.txt"); return 1; } if((Obj=fopen("output.txt","w"))==NULL) { fprintf(stderr, "%s open failed!\n", "output.txt"); return 1; } scanf("%d",&Step); //输入当前实验步骤 statCount(); //实验步骤1:统计文件中字符出现次数(频率) (Step==1) ? print1(): 1; //输出实验步骤1结果 createHTree(); //实验步骤2:依据字符频率生成相应的Huffman树 (Step==2) ? print2(Root): 2; //输出实验步骤2结果 makeHCode(); //实验步骤3:依据Root为树的根的Huffman树生成相应Huffman编码 (Step==3) ? print3(): 3; //输出实验步骤3结果 (Step>=4) ? atoHZIP(),print4(): 4; //实验步骤4:据Huffman编码生成压缩文件,并输出实验步骤4结果 fclose(Src); fclose(Obj); return 0; } //【实验步骤1】开始 void statCount() { } //【实验步骤1】结束 //【实验步骤2】开始 void createHTree() { } //【实验步骤2】结束 //【实验步骤3】开始 void makeHCode() { } //【实验步骤3】结束 //【实验步骤4】开始 void atoHZIP() { } //【实验步骤4】结束 void print1() { int i; printf("NUL:1\n"); for(i=1; i<128; i++) if(Ccount[i] > 0) printf("%c:%d\n", i, Ccount[i]); } void print2(struct tnode *p) { if(p != NULL){ if((p->left==NULL)&&(p->right==NULL)) switch(p->c){ case 0: printf("NUL ");break; case ' ': printf("SP ");break; case '\t': printf("TAB ");break; case '\n': printf("CR ");break; default: printf("%c ",p->c); break; } print2(p->left); print2(p->right); } } void print3() { int i; for(i=0; i<128; i++){ if(HCode[i][0] != 0){ switch(i){ case 0: printf("NUL:");break; case ' ': printf("SP:");break; case '\t': printf("TAB:");break; case '\n': printf("CR:");break; default: printf("%c:",i); break; } printf("%s\n",HCode[i]); } } } void print4() { long int in_size, out_size; fseek(Src,0,SEEK_END); fseek(Obj,0,SEEK_END); in_size = ftell(Src); out_size = ftell(Obj); printf("\n原文件大小:%ldB\n",in_size); printf("压缩后文件大小:%ldB\n",out_size); printf("压缩率:%.2f%%\n",(float)(in_size-out_size)*100/in_size); } - huffman2student.c:该文件给出本实验程序的框架,框架中部分内容未完成(见下面相关实验步骤),通过本实验补充完成缺失的代码,使得程序运行后得到相应要求的运行结果;
- input.txt:为本实验的测试数据。
input.txt中的内容如下:
I will give you some advice about life.Eat more roughage.Do more than others expect you to do and do it pains.Remember what life tells you.Do not take to heart every thing you hear.Do not spend all that you have.Do not sleep as long as you want.Whenever you say" I love you", please say it honestly.Whevever you say"I am sorry", please look into the other person’s eyes.
huffman2student.c文件中相关数据结构说明
结构类型说明:
struct tnode { //Huffman树结构节点类型 char c; int weight; struct tnode *left; struct tnode *right; } ;结构类型struct tnode用来定义Huffman树的节点,其中;
1)对于树的叶节点,成员c和weight用来存放字符及其出现次数;对于非叶节点来说,c值可不用考虑,weight的值满足Huffman树非叶节点生成条件,若p为当前Huffman树节点指针,则有:
p->weight = p->left->weight + p->right->weigth;
2)成员left和right分别为Huffman树节点左右子树节点指针。
全局变量说明:
int Ccount[128]={0}; struct tnode *Root=NULL; char HCode[128][MAXSIZE]={0}; int Step=0; FILE *Src, *Obj;整型数组Ccount存放每个字符的出现次数,如Ccount[‘a’]表示字符a的出现次数。
变量Root为所生成的Huffman树的根节点指针。
数组HCode用于存储字符的Huffman编码,如HCode[‘a’]为字符a的Huffman编码,本实验中为字符串”1000”。
变量Step为实验步骤状态变量,其取值为1、2、3、4,分别对应实验步骤1、2、3、4。
变量Src、Obj为输入输出的文件指针,分别用于打开输入文件“input.txt”和输出文件“output.txt”。
4. 实验步骤
【步骤一】
- 实验要求
在程序文件huffman2student.c中“//【实验步骤1】开始”和“ //【实验步骤1】结束”间编写相应代码,以实现函数statCount,统计文本文件input.txt中字符出现频率。
//【实验步骤1】开始
void statCount()
{
}
//【实验步骤1】结束
- 实验说明
函数statCount用来统计输入文件(文件指针为全局变量Src)中字符的出现次数(频率),并将字符出现次数存入全局变量数组Ccount中,如Ccount[‘a’]存放字符a的出现次数。
注意:在该函数中Ccount[0]一定要置为1,即Ccount[0]=1。编码值为0(’\0’)的字符用来作为压缩文件的结束符。
- 实验结果
函数print1()用来打印输出步骤1的结果,即输出数组Ccount中字符出现次数多于0的字符及次数,编码值为0的字符用NUL表示。完成【步骤1】编码后,本地编译并运行该程序,并在标准输入中输入1,程序运行正确时在屏幕上将输出如下结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2JHILASA-1684203856943)(./3.png)]
图1步骤1运行结果
在本地运行正确的情况下,将你所编写的程序文件中//【实验步骤1】开始”和“ //【实验步骤1】结束”间的代码拷贝粘贴到实验报告后所附代码【实验步骤1】下的框中,然后点击提交按钮,若得到如下运行结果(测试数据1评判结果为完全正确):

表明实验步骤1:通过,否则:不通过。
【步骤二】
- 实验要求
在程序文件huffman2student.c中的 “//【实验步骤2】开始”和“ //【实验步骤2】结束”间编写相应代码,实现函数createHTree,该函数生成一个根结点指针为Root的Huffman树。
//【实验步骤2】开始
void createHTree( )
{
}
//【实验步骤2】结束
- 实验说明
在程序文件huffman2student.c中函数createHTree将根据每个字符的出现次数(字符出现次数存放在全局数组Ccount中,Ccount[i]表示ASCII码值为i的字符出现次数),按照Huffman树生成规则,生成一棵Huffman树。
算法提示:
1.依据数组Ccout中出现次数不为0的( 即Ccount[i]>0)项,构造出树林F={T0, T1,¼, Tm}*,初始时Ti(0≤i≤m)为只有一个根结构的树,且根结点(叶结点)的权值为相应字符的出现次数的二叉树(每棵树结点的类型为struct tnode,其成员c为字符,weight为树节点权值):
for(i=0; i<128; i++)
if(Ccount[i]>0){
p = (struct tnode *)malloc(sizeof(struct tnode));
p->c = i; p->weight = Ccount[i];
p->left = p->right = NULL;
add p into F;
}
2.对树林F中每棵树按其根结点的权值由小至大进行排序(排序时,当权值weight相同时,字符c小的排在前面),得到一个有序树林F
3.while 树个数>1 in F
a) 将F中T0和T1作为左、右子树合并成为一棵新的二叉树T’,并令T’->weight= T0->weight+ T1->wei
b) 删除T0和T1 from F,同时将T’加入F。要求加入T’后F仍然有序。若F中有树根结点权值与T’相同,则T’应加入到其后
*4.Root = T0(Root为Huffman树的根结点指针。循环结束时,F中只有一个T0)
注:在实现函数createHTree时,在框中还可根据需要定义其它函数,例如:
void myfun(){ …}void createHTree(){ … myfun(); …}
- 实验结果
函数print2()用来打印输出步骤2的结果,即按前序遍历方式遍历步骤2所生成(由全局变量Root所指向的)Huffman树结点字符信息。输出时编码值为0的字符用NUL表示、空格符用SP表示、制表符用TAB表示、回车符用CR表示。完成【步骤2】编码后,本地编译并运行该程序,并在标准输入中输入2,程序运行正确时在屏幕上将输出如下结果:

图2 步骤2运行结果
在本地运行正确的情况下,将你在本地所编写的程序文件中//【实验步骤2】开始”和“ //【实验步骤2】结束”间的代码拷贝粘贴到实验报告后所附代码【实验步骤2】下的框中,然后点击提交按钮,若得到如下运行结果(测试数据2评判结果为完全正确):
表明实验步骤2:通过,否则:不通过。
【步骤三】
- 实验要求
在程序文件huffman2student.c中的 “//【实验步骤3】开始”和“ //【实验步骤3】结束”间编写相应代码,实现函数makeHCode,该函数依据【实验步骤3】中所产生的Huffman树为文本中出现的每个字符生成对应的Huffman编码。遍历Huffman树生成字符Huffman码时,左边为0右边为1。
//【实验步骤3】开始
void makeHCode( )
{
}
//【实验步骤3】结束
- 实验说明
【步骤3】依据【步骤2】所生成的根结点为Root的Huffman树生为文本中出现的每个字符生成相应的Huffman编码。全局变量HCode定义如下:
char HCode[128] [MAXSIZE];
HCode变量用来存放每个字符的Huffman编码串,如HCode[‘e’]存放的是字母e的Huffman编码串,在本实验中实际值将为字符串”011”。
算法提示:
可编写一个按前序遍历方法对根节点为Root的树进行遍历的递归函数,并在遍历过程中用一个字符串来记录遍历节点时从根节点到当前节点的路径(经过的边),经过左边时记录为’0’,经过右边时记录为’1’;当遍历节点为叶节点时,将对应路径串存放到相应的HCode数组中,即执行strcpy(HCode[p->c],路径串)。
注:在实现函数makeHCode时,在框中还可根据需要定义其它函数,如调用一个有类于前序遍历的递归函数来遍历Huffman树生成字符的Huffman编码:
void visitHTree(){ …}void makeHCode(){ … visitHTree(); …}
- 实验结果
函数print3()用来打印输出步骤3的结果,即输出步骤3所生成的存储在全局变量HCode中非空字符的Huffman编码串。完成【步骤3】编码后,本地编译并运行该程序,并在标准输入中输入3,在屏幕上将输出ASCII字符与其Huffman编码对应表,冒号左边为字符,右边为其对应的Huffman编码,其中NUL表示ASCII编码为0的字符,SP表示空格字符编码值为0的字符用,程序运行正确时在屏幕上将输出如下结果:

图3 步骤3运行结果
在本地运行正确的情况下,将你在本地所编写的程序文件中//【实验步骤3】开始”和“ //【实验步骤3】结束”间的代码拷贝粘贴到实验报告后所附代码【实验步骤3】下的框中,然后点击提交按钮,若得到如下运行结果(测试数据3评判结果为完全正确):

表明实验步骤3:通过,否则:不通过。
【步骤四】
- 实验要求
在程序文件huffman2student.c函数中的 “//【实验步骤4】开始”和“ //【实验步骤4】结束”间编写相应代码,实现函数atoHZIP,该函数依据【实验步骤3】中所生成的字符ASCII码与Huffman编码对应表(存储在全局变量HCode中,如HCode[‘e’]存放的是字符e对应的Huffman编码串,在本实验中值为字符串”011”),将原文本文件(文件指针为Src)内容(ASCII字符)转换为Huffman编码文件输出到文件output.txt(文件指针为Obj)中,以实现文件压缩。同时将输出结果用十六进制形式(printf(“%x”,…))输出到屏幕上,以便检查和查看结果。
//【实验步骤4】开始
void atoHZIP( )
{
}
//【实验步骤4】结束
- 实验说明
Huffman压缩原理:在当前Windows、Linux操作系统下,文本文件通常以ASCII编码方式存储和显示。ASCII编码是定长编码,每个字符固定占一个字节(即8位),如字符’e’的ASCII编码为十进制101(十六进制65,二进制为01100101)。而Huffman编码属于可变长编码,本实验中其依据文本中字符的频率进行编码,频率高的字符的编码长度短(小于8位),而频率低的字符的编码长度长(可能多于8位),如在本实验中,字符’ ’(空格)的出现频率最高(出现65次),其Huffman编码为111(占3位,远小于一个字节的8位),其它出现频率较高的字符,如字符’e’的Huffman编码为011、字符’o’的Huffman编码为111;字符’x’出现频率低(出现1次),其Huffman编码为10011110(占8位,刚好一个字节)(注意,在其它问题中,字符最长Huffman编码可能会超过8位)。正是由于高频字符编码短,将使得Huffman编码文件(按位)总长度要小于ASCII文本文件,以实现压缩文件的目的。
然而,将普通ASCII文本文件转换为变长编码的文件不便之处在于C语言中输入/输出函数数据处理的最小单位是一个字节(如putchar()),无法直接将Huffman(不定长)编码字符输出,在输出时需要将不定长编码序列转换为定长序列,按字节输出。而对于不定长编码,频率高的字符其编码要比一个字节短(如本实验中字符’e’的Huffman编码为011,不够一个字节,还需要和其它字符一起组成一个字节输出),频率低的编码可能超过一个字节。如何将不定长编码字符序列转换成定长字符序列输出,一个简单方法是:
1)根据输入字符序列将其Huffman编码串连接成一个(由0、1字符组成的)串;
2)然后依次读取该串中字符,依次放入到一个字节的相应位上;
3)若放满一个字节(即8位),可输出该字节;剩余的字符开始放入到下一个字节中;
4)重复步骤2和3,直到串中所有字符处理完。
下面通过实例来说明:
原始文件input.txt中内容以“I will…”开始,依据所生成的Huffman码表,字母I对应的Huffman编码串为“0101111”,空格对应“111”,w对应“1001110”,i对应“01010”,l对应 “11001”。因此,将其转换后得到一个Huffman编码串“01011111111001110010101100111001…”,由于在C中,最小输出单位是字节(共8位),因此,要通过C语言的位操作符将每8个01字符串放进一个字节中,如第一个8字符串“01011111”中的每个0和1放入到一个字符中十六进制(即printf(”%x”,c)输出时,屏幕上将显示5f)(如下图所示)。下面程序段将Huffman编码串每8个字符串放入一个字节(字符变量hc)中:

char hc; … for(i=0; s[i] != ‘\0’; i++) { hc = (hc << 1) | (s[i]-'0'); if((i+1)%8 == 0) { fputc(hc,obj); //输出到目标(压缩)文件中 printf("%x",hc); //按十六进制输出到屏幕上 } } …说明:
1.当遇到源文本文件输入结束时,应将输入结束符的Huffman码放到Huffman编码串最后,即将编码串HCode[0]放到Huffman编码串最后。
2.在处理完成所有Huffman编码串时(如上述算法结束时),处理源文本最后一个字符(文件结束符)Huffman编码串(其编码串为“01001010”)时,可能出现如下情况:其子串”010”位于前一个字节中输出,而子串“01010”位于另(最后)一个字节的右5位中,需要将这5位左移至左端的头,最后3位补0,然后再输出最后一个字节。

注:在实现函数atoHZIP时,在框中还可根据需要定义其它函数或全局变量,如:
void myfun(){ …}void atoHZIP(){ … myfun(); …}
- 实验结果
函数print4()用来打印输出步骤4的结果,即根据输出步骤3所生成的存储在全局变量HCode中Huffman编码串,依次对源文本文件(input.txt)的ASCII字符转换为Huffman编码字符输出到文件output.txt中,同时按十六进行输出到屏幕上。完成【步骤4】编码后,本地编译并运行该程序,并在标准输入中输入4,在屏幕上将输出:
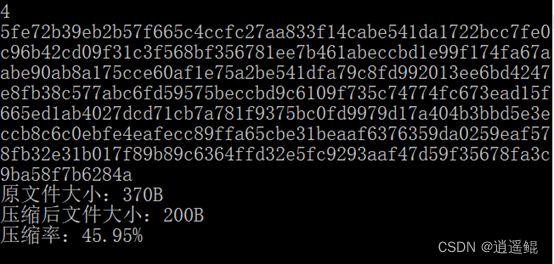
图4 步骤4运行结果
说明:
从屏幕输出结果可以看出,由于采用了不定长的Huffman编码,且出现频率高的字符的编码长度短,压缩后,文件大小由原来的370字节变为200字节,文件压缩了45.95%。
在本地运行正确的情况下,将你在本地所编写的程序文件中//【实验步骤4】开始”和“ //【实验步骤4】结束”间的代码拷贝粘贴到教学平台实验报告后所附代码【实验步骤4】下的框中,然后点击提交按钮,若得到如下运行结果(测试数据4评判结果为完全正确):

表明实验步骤4:通过,否则:不通过。
_______________________________________________________________
题解
步骤一
统计字母出现的频率,用一个循环逐个读入字符即可,代码如下:
void statCount() { Ccount[0]=1; // 题目要求 Src = fopen("input.txt", "r"); char tmp; while((tmp = fgetc(Src)) != EOF) { if (tmp == '\n') continue; Ccount[tmp] += 1; } fclose(Src); }步骤二
本题的算法提示已经把程序框架搭建起来了。其中所说的森林就是多棵树的集合,我的想法是开一个数组记录每棵树的根结点指针作为森林的结构(是指针数组)。而后要对这个数组排序,排序时我的想法是正好和题目要求的顺序相反,这样做的好处是每次都是取出数组(森林)中的最后两棵树合并为一棵——保证了数组第0个元素始终存在,最后根结点就一定是这第0个元素(当然并没有实质性的差别,按照要求去排序也没有问题)。
首先在createHTree函数中定义用到的一些变量:
// createHTree中 struct tnode* forest[128]; // 森林,指针数组 struct tnode* temp[128]; // 后面操作时的临时容器 struct tnode* tmp; int tree_num = 0; // 记录森林中树的个数而后要构建森林,把Ccount中的各位遍历一遍即可:
// createHTree中 for (int i = 0; i < 128; i++) { if (Ccount[i] > 0) { tmp = (struct tnode*) malloc(sizeof(struct tnode)); tmp -> c = i; tmp -> weight = Ccount[i]; tmp -> left = tmp -> right = NULL; forest[tree_num++] = tmp; } }然后要对forest数组排序,注意到这和上一题一样是一个指针数组,要把二级指针传入cmp:
int cmp(const void *e1, const void *e2) { struct tnode** a = (struct tnode**) e1; struct tnode** b = (struct tnode**) e2; if ((*a) -> weight != (*b) -> weight) // 权重不等,按权重排序 return (*b) -> weight - (*a) -> weight; return (*b) -> c - (*a) -> c; // 权重相等,按字符字ASCII码排序 }然后调用qsort:
// createHTree中 qsort(forest, tree_num, sizeof(struct tnode*), cmp); // 对指针数组排序(和题目的要求正好反序排,以保证数组的第0个元素不被破坏)
之后要对森林中各树进行合并,但这里有个bug,就是假如原来两颗权重为1的树合并为一棵权重位2的树了,但是如果原来森林中就有一颗权重为2的树的话,按照题目要求,“要求加入T’后F仍然有序。若F中有树根结点权值与T’相同,则T’应加入到其后”就不支持我们使用qsort了,因为这是不稳定排序,所以没办法只能用memcpy去拷贝内存了(注意我使用的排序顺序和题目正好相反,所以后面的顺序也应该是反过来的,比如谁是左子树谁是右子树这些):
// createHTree中 while(tree_num > 1) { // 循环终止条件,tree_num为1时代表森林中只剩下一棵树(合并完成) struct tnode* p = (struct tnode*) malloc(sizeof(struct tnode)); // 合并成的新树的结点 p -> weight = forest[tree_num - 1] -> weight + forest[tree_num - 2] -> weight; // 把森林中最后两棵树合并为一颗 p -> left = forest[tree_num - 1]; // 左子树 p -> right = forest[tree_num - 2]; // 右子树 tree_num -= 2; // 先把森林中的最后两棵树拿出,树的数量减2 int location; // 新树插入的位置(下标) for (location = 0; location < tree_num; location++) { if (forest[location] -> weight <= p -> weight) { break; } } if (location == tree_num) forest[tree_num++] = p; // 新树的位置是森林尾部,直接插入 else { // 新树插入到森林中间的部分,用memset把前后分开,插入后再把后半部分拷贝回来 memcpy(temp, forest + location, sizeof(struct tnode*) * (tree_num - location)); forest[location] = p; memcpy(forest + location + 1, temp, sizeof(struct tnode*) * (tree_num - location)); tree_num++; } } Root = forest[0]; // 最后只剩下一棵树了,该结点即为哈夫曼树的根结点步骤三
本步就是一个标准的深度优先搜索,可以设置一个dfs函数,它接受结点的指针以及该结点的深度,和到该结点为止的字符串,对它操作完之后,给它的做右子树的字符串分别赋0,1,同时深度加1再次调用自己即可。递归的终止条件就是遍历到叶子结点了,此时要对HCode中相应位置进行赋值。需要注意的一点是,dfs子树前,要把最后一位“回溯”为0,dfs右子树前同理,因为深度优先搜索后,字符串的后面已经填充了很多位,代码如下:
void dfs(struct tnode* root, int height, char* code) { // 叶子结点,可以赋值了 if (root -> left == NULL && root -> right == NULL) { strcpy(HCode[root -> c], code); return ; } // 处理左子树 code[height] = '0'; // 给下一位赋值0 code[height + 1] = '\0'; // 回溯 dfs(root -> left, height + 1, code); // 处理右子树 code[height] = '1'; // 给下一位赋1 code[height + 1] = '\0'; // 回溯 dfs(root -> right, height + 1, code); }makeHCode中调用dfs即可:
void makeHCode() { char code[50] = {0}; dfs(Root, 0, code); }步骤四
本步的算法提示已经把最后输出的代码给出了,需要注意的是题目中提示的char ch不对,这样在16进制下会输出一堆f,具体原因可以百度,解决方法就是改为unsigned char。其它步骤没什么难度,直接给出参考代码:
void atoHZIP() { // 打开文件 Src = fopen("input.txt", "r"); Obj = fopen("output.txt", "w"); char s[102400] = {0}; char text; while((text = fgetc(Src)) != EOF) { if (text != '\n') { strcat(s, HCode[text]); // 转化为哈夫曼编码对应表中的01串 } } strcat(s, HCode[0]); // 末尾设置为HCode[0] int len = strlen(s); int residue = len % 8; for (int i = 0; i < residue; i++) { s[len++] = '0'; // 把末尾不足的位数填充为'0' } // 输出 unsigned char hc; for(int i = 0; s[i] != '\0'; i++) { hc = (hc << 1) | (s[i]-'0'); if((i+1)%8 == 0) { fputc(hc,Obj); //输出到目标(压缩)文件中 printf("%x",hc); //按十六进制输出到屏幕上 } } }四个步骤的完整代码
// 步骤一 void statCount() { Ccount[0]=1; // 题目要求 Src = fopen("input.txt", "r"); char tmp; while((tmp = fgetc(Src)) != EOF) { if (tmp == '\n') continue; Ccount[tmp] += 1; } fclose(Src); } // 步骤二 int cmp(const void *e1, const void *e2) { struct tnode** a = (struct tnode**) e1; struct tnode** b = (struct tnode**) e2; if ((*a) -> weight != (*b) -> weight) // 权重不等,按权重排序 return (*b) -> weight - (*a) -> weight; return (*b) -> c - (*a) -> c; // 权重相等,按字符字ASCII码排序 } void createHTree() { struct tnode* forest[128]; // 森林,指针数组 struct tnode* temp[128]; // 后面操作时的临时容器 struct tnode* tmp; int tree_num = 0; // 记录森林中树的个数 for (int i = 0; i < 128; i++) { if (Ccount[i] > 0) { tmp = (struct tnode*) malloc(sizeof(struct tnode)); tmp -> c = i; tmp -> weight = Ccount[i]; tmp -> left = tmp -> right = NULL; forest[tree_num++] = tmp; } } qsort(forest, tree_num, sizeof(struct tnode*), cmp); // 对指针数组排序(和题目的要求正好反序排,以保证数组的第0个元素不被破坏) while(tree_num > 1) { // 循环终止条件,tree_num为1时代表森林中只剩下一棵树(合并完成) struct tnode* p = (struct tnode*) malloc(sizeof(struct tnode)); // 合并成的新树的结点 p -> weight = forest[tree_num - 1] -> weight + forest[tree_num - 2] -> weight; // 把森林中最后两棵树合并为一颗 p -> left = forest[tree_num - 1]; // 左子树 p -> right = forest[tree_num - 2]; // 右子树 tree_num -= 2; // 先把森林中的最后两棵树拿出,树的数量减2 int location; // 新树插入的位置(下标) for (location = 0; location < tree_num; location++) { if (forest[location] -> weight <= p -> weight) { break; } } if (location == tree_num) forest[tree_num++] = p; // 新树的位置是森林尾部,直接插入 else { // 新树插入到森林中间的部分,用memset把前后分开,插入后再把后半部分拷贝回来 memcpy(temp, forest + location, sizeof(struct tnode*) * (tree_num - location)); forest[location] = p; memcpy(forest + location + 1, temp, sizeof(struct tnode*) * (tree_num - location)); tree_num++; } } Root = forest[0]; // 最后只剩下一棵树了,该结点即为哈夫曼树的根结点 } // 步骤三 void dfs(struct tnode* root, int height, char* code) { // 叶子结点,可以赋值了 if (root -> left == NULL && root -> right == NULL) { strcpy(HCode[root -> c], code); return ; } // 处理左子树 code[height] = '0'; // 给下一位赋值0 code[height + 1] = '\0'; // 回溯 dfs(root -> left, height + 1, code); // 处理右子树 code[height] = '1'; // 给下一位赋1 code[height + 1] = '\0'; // 回溯 dfs(root -> right, height + 1, code); } void makeHCode() { char code[50] = {0}; dfs(Root, 0, code); } // 步骤四 void atoHZIP() { // 打开文件 Src = fopen("input.txt", "r"); Obj = fopen("output.txt", "w"); char s[102400] = {0}; char text; while((text = fgetc(Src)) != EOF) { if (text != '\n') { strcat(s, HCode[text]); // 转化为哈夫曼编码对应表中的01串 } } strcat(s, HCode[0]); // 末尾设置为HCode[0] int len = strlen(s); int residue = len % 8; for (int i = 0; i < residue; i++) { s[len++] = '0'; // 把末尾不足的位数填充为'0' } // 输出 unsigned char hc; for(int i = 0; s[i] != '\0'; i++) { hc = (hc << 1) | (s[i]-'0'); if((i+1)%8 == 0) { fputc(hc,Obj); //输出到目标(压缩)文件中 printf("%x",hc); //按十六进制输出到屏幕上 } } }

![[工业自动化-1]:PLC架构与工作原理](https://img-blog.csdnimg.cn/ce10a1471ed14382bc58364cf8bd5209.png)






还没有评论,来说两句吧...